2.模糊查询
模糊查询在Mapper.xml中可以用2种占位符
1).#占位符:此时传入的参数上就要有%%
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
String keyword = "%张%";
List<Employee> emps = mapper.queryByKeyWord(keyword);
for (Employee emp : emps) {
System.out.println(emp);
}
映射文件中的sql
<select id="queryByKeyWord" resultType="com.sxt.domain.Employee">
select * from t_employee where ename like #{name}
</select>
2).$占位符:此时传入的参数上可以没有%%,%在sql语句上写
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
String keyword = "张";
List<Employee> emps = mapper.queryByKeyWord(keyword);
select * from t_employee where ename like '%${value}%'
3.多对一关联查询
对于多表连接查询,默认是不能用resultType来映射结果集,但是可以使用VO类来扩展实体类,从而将多表的结果集封装到VO对象上(了解)
public class EmployeeVo extends Employee {
private Integer did;
private String dname;
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
}
重点:使用resultMap来映射多对一关联的查询结果集
3.1 多对一关联查询—用resultMap结果嵌套
在Mapper.xml中用association来映射关联对象,并嵌套在resultMap中

3.2 多对一关联查询—用resultMap查询嵌套
查询嵌套即在查询主对象的resultMap中使用association标签的select属性来引入另一个sql查询,通过select来定位查询从对象的方法,值是查询从对象的statement的唯一标识
查询嵌套的理解:参照课件中的”1.多对一查询嵌套.jpg”
resultMap查询嵌套将多对一关联查询分成了2步,先查询主对象,再查询从对象,会产生2条SQL语句

补充:将所有配置文件都抽取到另一个名为config的Source Foloder里面
1)新建一个Source Folder,名为config

2)将所有配置文件,映射文件都放到config目录下,src里面只存放java源文件
4.一对多关联查询
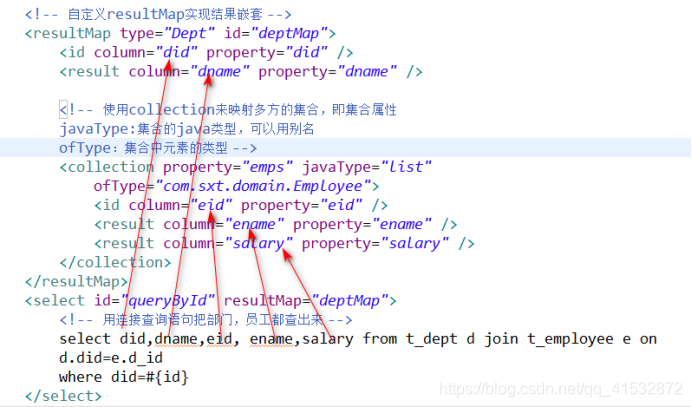
4.1 一对多关联查询—用resultMap结果嵌套
在Mapper.xml中,编写resultMap时,使用collection来映射多方的集合,用一个连接查询的sql
4.2 一对多关联查询—用resultMap查询嵌套
<!-- 自定义resultMap实现查询嵌套 -->
<resultMap type="Dept" id="deptStepMap">
<id column="did" property="did" />
<result column="dname" property="dname" />
<!-- 使用collection来映射多方的集合,即集合属性
javaType:集合的java类型,可以用别名
ofType:集合中元素的类型 -->
<collection property="emps" javaType="list"
ofType="com.sxt.domain.Employee" select="com.sxt.mapper.EmployeeMapper.queryById" column="did" ></collection>
</resultMap>
<select id="queryByStep" resultMap="deptStepMap">
<!-- 查主对象,部门 -->
select did,dname from t_dept where did=#{id}
</select>
上面select属性指向EmployeeMapper中的查询员工的statment的唯一标识
<mapper namespace="com.sxt.mapper.EmployeeMapper">
<!-- 查员工 -->
<select id="queryById" resultType="Employee">
select eid,ename,salary from t_employee where d_id=#{id}
</select>
</mapper>
5.懒加载(理解)
懒加载:又叫延迟加载,当需要用到关联对象的数据时,才去发SQL到数据库中查询关联的对象的数据,否则就不去查数据库。
Mybatis默认不支持懒加载,即没有用到关联对象数据时,也会发SQL查数据库。
如果要让Mybatis支持懒加载,需要在主配置文件中进行全局配置
懒加载只对查询嵌套有效,对结果嵌套无效,如果只查主对象,则只生成一起sql,不会生成查从对象的SQL
6.动态SQL(超级重点)
if,choose,set, where, foreach标签,见案例
7.Mybatis缓存(了解)
1.一级缓存:在SqlSession范围内的缓存,即在SqlSession未关闭前,一级缓存是有效的。
第一次查询对象时,会发送SQL去查询数据库,把查到的结果放到一级缓存中;再次查询相同对象时,直接使用缓存中的数据,不再查数据库。一级缓存默认是开启的
2.二级缓存:Mapper级别的缓存,用不同的SqlSession操作同一个Mapper时,共享该Mapper的二级缓存
注意:被缓存的对象的类要实现Serializable接口
public class Employee implements Serializable{
8.Mybatis注解(掌握)
使用注解写简单的sql语句,如果需要进行一对多/多对一的关联查询,用注解很不方便,建议写在XML映射文件中。如果sql是动态sql,不要用注解。注解和XML配置可以同时使用。
.@Param:指定参数的名称
@Param注解用于指定传给占位符的参数名字,此时占位符里面的xxx就必须与注解的参数名一致。
例如
java
@Select("select eid, ename,sex,salary from t_employee where eid=#{empid}")
Employee queryById(@Param("empid") Integer eid);
9.Mybatis逆向工程(掌握)
参照学习文档一步步做,逆向工程的缺点:
生成的多个实体类之间,不会自动建立一对多/多对一的关联,每个字段在实体类都是一个简单类型的属性,例如下面的Integer dId就是员工表外键映射的属性,并不是Dept类型的
public class Employee implements Serializable {
private Integer eid;
private String ename;
private String sex;
private Integer salary;
private Integer dId;
注意:保存所有配置文件和Mapper.xml的config目录需要手动创建,为了能够生成日志信息,还需要加入log4j相关的jar包以及log4j.properties