一、简述
Disruptor版本:3.4.2
二、Sequence
Sequence的实现类似于AtomicLong,不同的是Sequence进行了缓存行填充。
Sequence类在Disruptor中非常关键,生产者和消费者都持有各自的Sequence对象,用于追踪RingBuffer的生产情况和消费情况。
下面分析Sequence类的缓存行填充:
//对象头占用8个字节
class LhsPadding
{
//7*8=56个字节
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
//value 8个字节
protected volatile long value;
}
class RhsPadding extends Value
{
//7*8=56个字节
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
关于缓存伪共享的原理参考这两篇文章:
http://ifeve.com/falsesharing/
http://ifeve.com/false-shareing-java-7-cn/
大致意思是:CPU加载数据是以缓存行(Cache Line)为基本单位的,缓存行大小可以是64位或128位。当两个独立变量x和y被加载到同一个缓存行,无论是x的修改还是y的修改,都将导致缓存行失效,从而降低程序运行效率。
如下图:
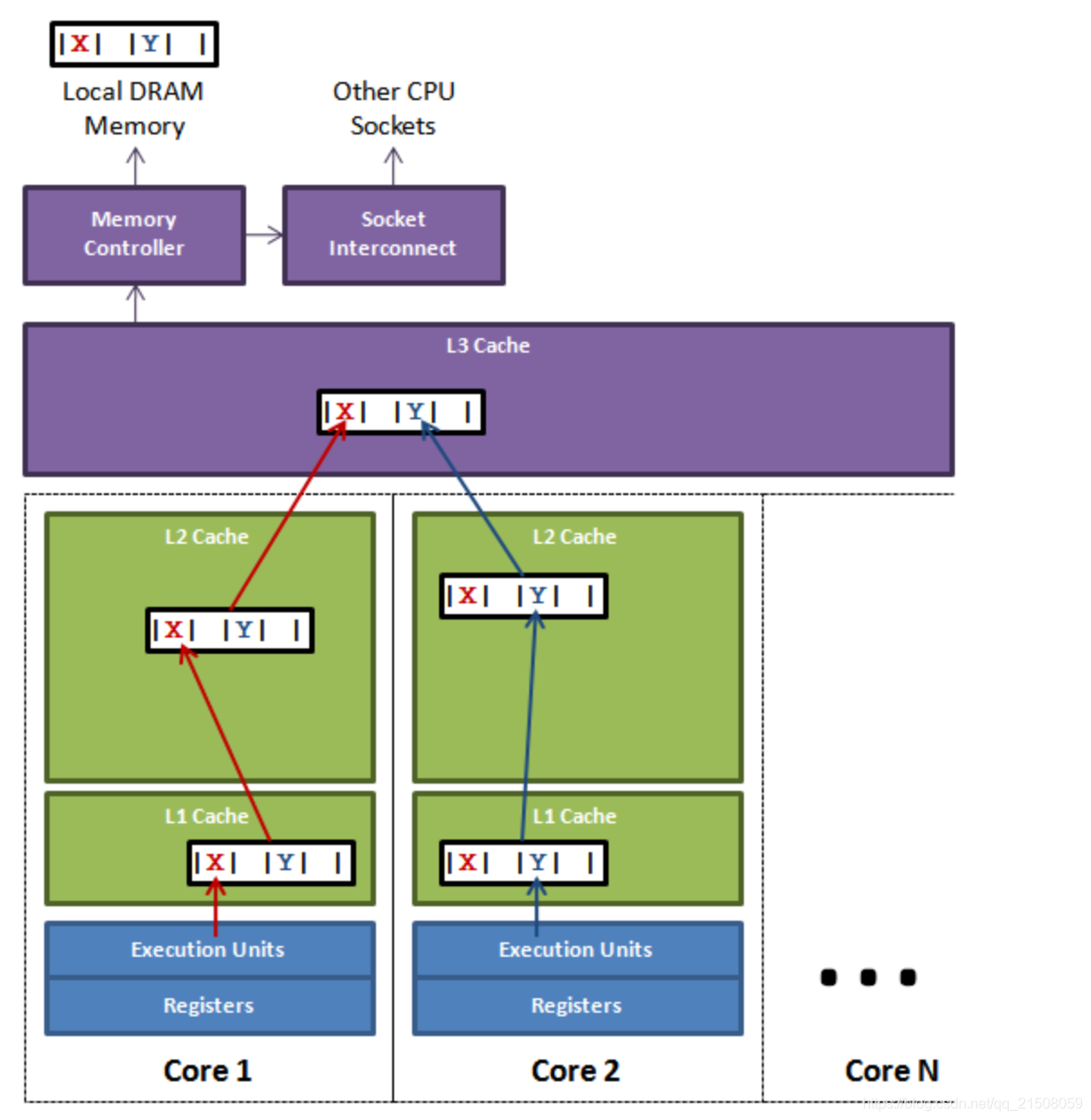
吐槽,Martin大神的图被国内博客疯狂copy。
Sequence在value两旁各填充了7个long类型,加上value,加上对象头,相当于16个long,共128个字节,可解决128位或64位缓存行的伪共享问题。
关于Disruptor中的CAS
基本上,Disruptor使用的是无锁的CAS算法,依赖于Unsafe类以及volatile变量。Unsafe类提供了调用底层操作系统CAS操作的编程接口。
仅分析下令人疑惑的putOrderedLong。
public class Sequence extends RhsPadding
{
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static
{
UNSAFE = Util.getUnsafe();
try
{
//获取字段value的内存偏移量
VALUE_OFFSET = UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}
catch (final Exception e)
{
throw new RuntimeException(e);
}
}
/**
* putOrderedLong只会在volatile写前添加Store/Store屏障,
* 而不会在volatile写后添加Store/Load屏障,因此对volatile
* 变量的写入,不会立即对其他线程可见。但由于减少了StoreLoad内
* 存屏障,提高了执行效率。
*
/
public void set(final long value)
{
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
/**
* Store/Store
* volatile写
* Store/Load
*/
public void setVolatile(final long value)
{
UNSAFE.putLongVolatile(this, VALUE_OFFSET, value);
}
关于CAS:
https://blog.csdn.net/mmoren/article/details/79185862
关于Java内存模型(内存屏障的理解):
https://www.infoq.cn/profile/1278512
三、RingBuffer
RingBuffer是一个环形队列,充当Disruptor数据传输的容器。
RingBuffer同样进行了缓存行填充。
3.1填充RingBuffer字段
abstract class RingBufferPad
{
//前面填充7个long
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
//以下是被缓存行填充保护的字段列表
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
//后填充7个long
protected long p1, p2, p3, p4, p5, p6, p7;
原理和Sequence一样,防止64位或128位的缓存行伪共享。
3.2填充entries数组
abstract class RingBufferFields<E> extends RingBufferPad
{
private static final int BUFFER_PAD;
private static final long REF_ARRAY_BASE;
private static final int REF_ELEMENT_SHIFT;
private static final Unsafe UNSAFE = Util.getUnsafe();
static
{
//获取每个数组元素所占位数
final int scale = UNSAFE.arrayIndexScale(Object[].class);
if (4 == scale)
{
//从index -> 内存偏移,需要 index << REF_ELEMENT_SHIFT
REF_ELEMENT_SHIFT = 2;
}
else if (8 == scale)
{
REF_ELEMENT_SHIFT = 3;
}
else
{
throw new IllegalStateException("Unknown pointer size");
}
//进行128位缓存行填充所需数组元素个数
BUFFER_PAD = 128 / scale;
//第一个元素的内存偏移量,包含了缓存行填充
// Including the buffer pad in the array base offset
REF_ARRAY_BASE = UNSAFE.arrayBaseOffset(Object[].class) + (BUFFER_PAD << REF_ELEMENT_SHIFT);
}
RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer)
{
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
if (bufferSize < 1)
{
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
if (Integer.bitCount(bufferSize) != 1)
{
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.indexMask = bufferSize - 1;
// buffer_pad events buffer_pad,防止访问数组元素时,发生缓存伪共享
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory)
{
for (int i = 0; i < bufferSize; i++)
{
//预先生成对象,即内存预分配
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
@SuppressWarnings("unchecked")
protected final E elementAt(long sequence)
{
//这里可以看出为何bufferSize必须是2的n次方,sequence & indexMask可快速计算出元素下标
return (E) UNSAFE.getObject(entries, REF_ARRAY_BASE + ((sequence & indexMask) << REF_ELEMENT_SHIFT));
}
RingBuffer其他接口,基本上委托Sequencer完成,因此RingBuffer只充当数据交换的容器。
四、Sequencer
生产者通过Sequencer.next()申请RingBuffer中空闲的槽位,通过Sequencer.publish(long)通知消费者槽位可消费。
生产者与消费者通过Sequence联系起来,如下图:
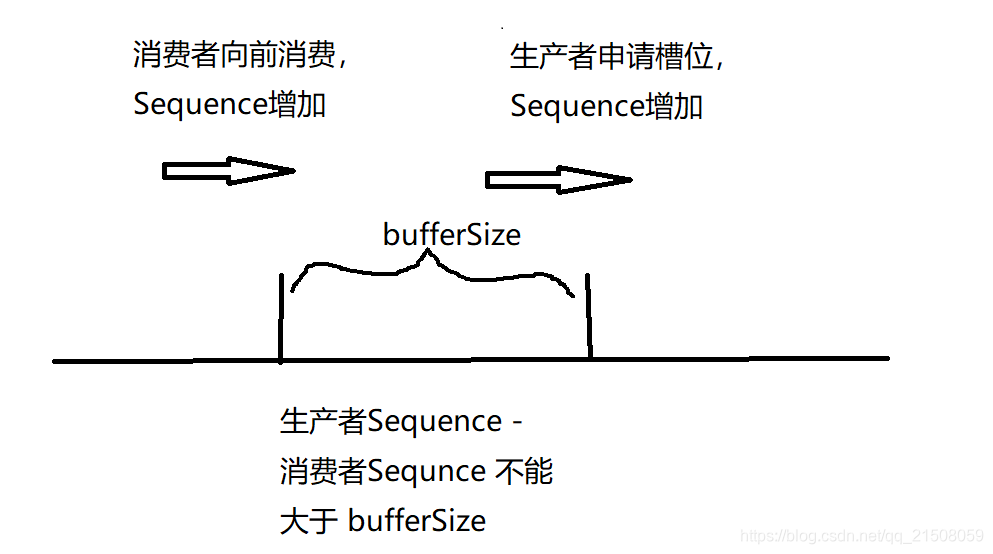
另外,生产者一次申请的Sequence是连续的并且是原子的,如可以申请1~10号位的Sequence,而不能申请 1、3、5这样断续的Sequence。
下面仅分析用于多生产者的MultiProducerSequencer。
4.1 Sequencer.next
RingBuffer.next() -> Sequencer.next() -> Sequencer.next(long),生产者调用Sequencer.next申请空闲的槽位,当无空闲槽位可申请,则调用LockSupport.parkNanos(1);进行CPU自旋等待;否则CAS竞争申请从current~next的Sequence序列。
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
//1.获取当前槽位
current = cursor.get();
//2.申请从current + 1到next范围的槽位
next = current + n;
//3.wrapPoint(用来判断要申请的槽位是否已绕环一圈)
long wrapPoint = next - bufferSize;
//4.上次消费者到达的最大槽位缓存
long cachedGatingSequence = gatingSequenceCache.get();
//5.1 wrapPoint > cacheGatingSequence,此时说明消费者消费槽位速度 < 生产者申请槽位的速度,生产者可能已经申请完所有空闲槽位,为什么说可能?因为cacheGatingSequence是上次缓存的结果,因此要进入if语句内部判断是否需要阻塞
//5.2 cacheGatingSequence > current,从步骤1 -> 步骤4运行期间,另一个线程通过next方法修改了cacheGatingSequence,因此current已无效
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
//6.此刻消费者已消费的最大Sequence
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
//7.仍然表明槽位不够,则CPU自旋等待,等待消费者消费后空出槽位。
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
//8.槽位够用,则更新gatingSequenceCache,防止误判
gatingSequenceCache.set(gatingSequence);
}
//9.CAS尝试获取current ~ next的Sequence,获取失败则重试
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}
分析:
从上面分析可以看到,当消费者消费速度 < 生产者生产速度,导致槽位不够用,生产者将在第7步进行CPU自旋阻塞,如果消费者消费速度远小于生产者生产速度,则多个线程在第7步进行忙等等,导致CPU占用率飙升。
结论:
Disruptor被设计用于高并发系统,要求生产者生产速率和消费者消费速率匹配,在消费者消费速率远小于生产者生产速率时,由于使用LockSupport.partNanos(1)进行自旋等待,将导致CPU占用率飙升。
4.2 Sequencer.publish
RingBuffer.publish(long) -> Sequencer.publish(long),生产者publish方法,声明某个槽位可消费,并唤醒可能因无槽位可消费而阻塞的消费者线程。阻塞以及唤醒消费者线程的方式取决于WaitStrategy策略接口的具体实现,默认是BlockingWaitStrategy,采用wait/notify的方式。
public final class MultiProducerSequencer extends AbstractSequencer
{
//标记某个槽位是否可消费,初始每个元素值为-1
private final int[] availableBuffer;
//bufferSize-1,用于计算某个sequence对应的数组下标
private final int indexMask;
//bufferSize为2^n,则indexShift为n
private final int indexShift;
public MultiProducerSequencer(int bufferSize, final WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
availableBuffer = new int[bufferSize];
indexMask = bufferSize - 1;
//对bufferSize进行数学log2运算,则2^n -> n
indexShift = Util.log2(bufferSize);
initialiseAvailableBuffer();
}
//初始化availableBuffer元素初始值为-1,表示初始所有槽位都不可消费
private void initialiseAvailableBuffer()
{
for (int i = availableBuffer.length - 1; i != 0; i--)
{
setAvailableBufferValue(i, -1);
}
setAvailableBufferValue(0, -1);
}
public void publish(final long sequence)
{
//标记该sequence对应的槽位可消费
setAvailable(sequence);
//唤醒阻塞的消费者线程
waitStrategy.signalAllWhenBlocking();
}
private void setAvailable(final long sequence)
{
setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence));
}
//使用Unsafe.putOrderedInt对数组元素进行赋值,是为了利用
//putOrderedInt提供的Store/Store内存屏障,防止这条指令和前面
//的指令重排序,但putOrderedInt不保证其他线程可以立刻看到写入的新值,
//即putOrderedInt不保证可见性
private void setAvailableBufferValue(int index, int flag)
{
long bufferAddress = (index * SCALE) + BASE;
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
}
//计算是否可用的标志,实际上是sequence/bufferSize,使用移位运算提高执行效率
private int calculateAvailabilityFlag(final long sequence)
{
return (int) (sequence >>> indexShift);
}
//计算sequence对应的数组下标
private int calculateIndex(final long sequence)
{
return ((int) sequence) & indexMask;
}
4.3 Sequencer.tryNext
Sequencer.next在无空闲槽位的情况下,会调用LockSupport.parkNonas(1)进行自旋等待;Sequencer.tryNext在发现无空闲槽位时,会抛出InsufficientCapacityException。
public long tryNext(int n) throws InsufficientCapacityException
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
//无空闲槽位,抛出异常
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
return next;
}
private boolean hasAvailableCapacity(Sequence[] gatingSequences, final int requiredCapacity, long cursorValue)
{
long wrapPoint = (cursorValue + requiredCapacity) - bufferSize;
long cachedGatingSequence = gatingSequenceCache.get();
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > cursorValue)
{
long minSequence = Util.getMinimumSequence(gatingSequences, cursorValue);
//更新gatingSequenceCache,帮助其他生产者判断是否存在空闲槽位
gatingSequenceCache.set(minSequence);
if (wrapPoint > minSequence)
{
return false;
}
}
return true;
}
五、BatchEventProcessor
5.1 BatchEventProcessor创建过程
1.Disruptor.handleEventsWith
设置用于消费Event的EventHandler。EventHandler接口是用户实现的用于消费准备好的Event的接口,但Disruptor中真正从RingBuffer获取事件并消费的接口是EventProcessor,在EventProcessor中将回调EventHandler接口。
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers);
}
2.Disruptor.createEventProcessors
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
//EventProcessor之间存在依赖关系,这些是当前EventProcessor
//所依赖的EventProcessor持有的Sequence,只有前面的EventProcessor
//消费完后,当前EventProcessor才能消费相应的槽位
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
//SequenceBarrier用于等待所依赖的barrierSequences完成的对象
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
//一个EventHandler对应一个BatchEventProcessor
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
//注册新创建的BatchEventProcessor,后面将根据已注册的
//BatchEventProcessor,每个BatchEventProcessor对应
//一个消费者线程
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
//对于生产者而言,判断某个槽位是否消费完,依赖的是最后处理完成的BatchEventProcessor,因此前面的barrierSequences对生产者而已没有意义,而最后批次的processorSequences则需要进行记录
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
//这个对象是为了链式调用handleEventsWith,它将当前的processSequences
//当作下个BatchEventProcessor的barrierSequences传入
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
3.EventHandlerGroup.handleEventsWith
public class EventHandlerGroup<T>
{
//Disruptor对象
private final Disruptor<T> disruptor;
private final ConsumerRepository<T> consumerRepository;
//调用链末尾的BatchEventProcessor的Sequence
private final Sequence[] sequences;
// 把末尾的sequences作为barrierSequences,创建下一个批次的BatchEventProcessor
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return disruptor.createEventProcessors(sequences, handlers);
}
关于EventProcessor之间的依赖关系,可以用看这张图:
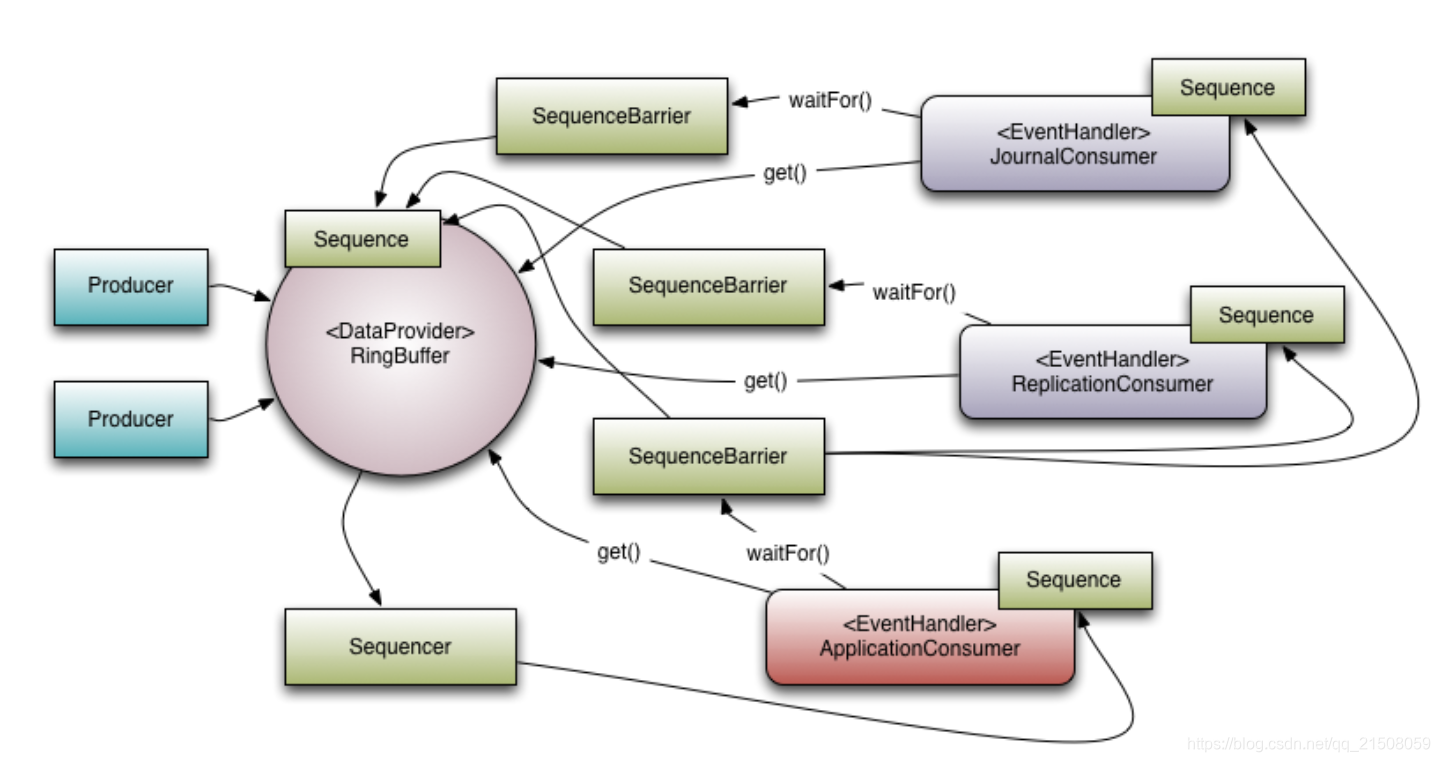
图中共3个消费者,对于某个槽位,JournalConsumer和ReplicationConsumer仅依赖于RingBuffer.Sequence(在3.x版本后,这部分代码转移到Sequencer中),而ApplicationConsumer必须在JournalConsumer和ReplicationConsumer消费完后,才能对于的槽位。
5.2 BatchEventProcessor.processEvents
BatchEventProcessor类图如下所示:
实现了Runnable接口,说明BatchEventProcessor将作为任务被线程池调度。
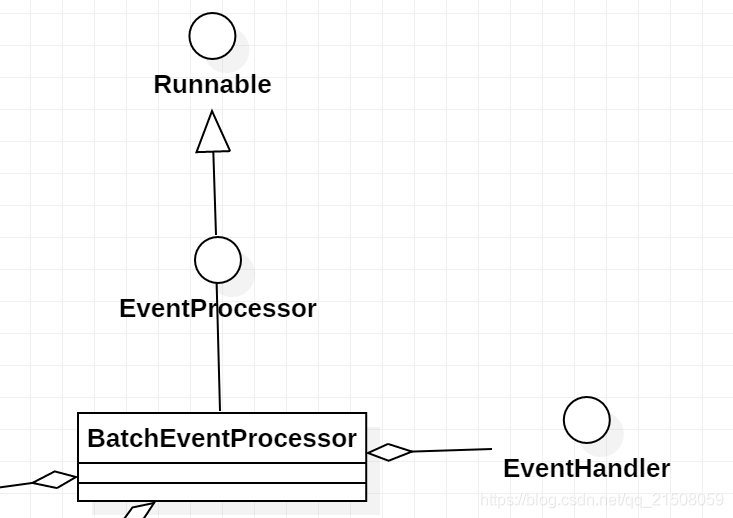
1.BatchEventProcessor.run
除了一些状态判断的代码,主要是调用了processEvents方法。
public void run()
{
if (running.compareAndSet(IDLE, RUNNING))
{
sequenceBarrier.clearAlert();
notifyStart();
try
{
if (running.get() == RUNNING)
{
processEvents();
}
}
finally
{
notifyShutdown();
running.set(IDLE);
}
}
else
{
// This is a little bit of guess work. The running state could of changed to HALTED by
// this point. However, Java does not have compareAndExchange which is the only way
// to get it exactly correct.
if (running.get() == RUNNING)
{
throw new IllegalStateException("Thread is already running");
}
else
{
earlyExit();
}
}
}
2.BatchEventProcessor.processEvents()
private void processEvents()
{
T event = null;
//sequence是已经消费到的最大槽位,nextSequence则是下一个将要消费的槽位
long nextSequence = sequence.get() + 1L;
//由此可知,一个BatchEventProcessor对于一个消费者线程
while (true)
{
try
{
//SequenceBarrierl.waitFor,阻塞直到nextSequence可消费为止,返回时,availableSequence可能>nextSequence,取决于消费者生产速度以及上层消费者消费速度
//两种可能性阻塞:
//1.生产者生产速度过慢,无槽位可消费
//2.上层消费者消费过慢,轮不到自己消费
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
//可选的BatchStartAware声明周期接口,实现该接口,在消费一个批次的槽位前,会得到通知
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
//消费一个批次的槽位
while (nextSequence <= availableSequence)
{
//DataProvider即Sequencer,取出要消费的Event
event = dataProvider.get(nextSequence);
//回调EventHandler接口
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
//设置当前BatchEventProcessor的Sequence,作用是通知调用链下游的BatchEventProcessor,上层已消费完毕
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
六、SeqeunceBarrier
从上面对BatchEventProcessor的分析可知,SequenceBarrier的作用主要是在生产者生产速度过慢,或者上层消费者消费速度过慢的情况下,阻塞消费者线程。
1.ProcessingSequenceBarrier.waitFor
@Override
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
//调用策略接口
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
//返回此次可消费的最大序列
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
2.WaitStrategy.waitFor
默认实现是BlockingWaitStrategy
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
//cursorSequence即Sequencer的Sequence,说明生产者申请的最大槽位
//cursorSequence.get()<sequence,说明生产者还没申请这个槽位,当然现在不可消费
if (cursorSequence.get() < sequence)
{
lock.lock();
try
{
//不满足条件的情况下,阻塞当前消费者线程
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
processorNotifyCondition.await();
}
}
finally
{
lock.unlock();
}
}
//dependentSequence是上层消费者消费到的槽位,不满足情况的条件下
//进行CPU自旋等待(Disruptor认为消费过程不可能太久,因为Disruptor设计用于低延时,高并发的系统)
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
3.Sequencer.getHighestPublishedSequence
上面WaitStrategy有个问题没解决,即生产者槽位申请了,但是是否调用Sequencer.publish了呢?
public long getHighestPublishedSequence(long lowerBound, long availableSequence)
{
//对WaitStrategy返回的availableSequence,验证对应槽位是否publish
for (long sequence = lowerBound; sequence <= availableSequence; sequence++)
{
if (!isAvailable(sequence))
{
return sequence - 1;
}
}
return availableSequence;
}
//这里的计算过程,和Sequencer.publish类似,有疑问请查看Sequencer.publish
public boolean isAvailable(long sequence)
{
int index = calculateIndex(sequence);
int flag = calculateAvailabilityFlag(sequence);
long bufferAddress = (index * SCALE) + BASE;
return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;
}
七、总结
Sequencer组织结构:
- RingBuffer是环形队列,作为数据传输的容器
- Sequence用于追踪生产者申请的最新槽位,以及消费者消费到的最大槽位,并用于同步生产者和消费者之间的动作。
- Sequencer维护生产者的Sequence,生产者通过Sequencer.next申请空闲槽位,同Sequencer.publish声明槽位可消费
- BatchEventProcessor对于一个消费者线程,当无槽位可消费时,阻塞等待,否则获取对应槽位的Event对象,回调EventHandler接口
- SequenceBarrier用于维护消费者之间的依赖关系,当上层消费者消费过慢时,阻塞进行等待。
Disruptor高效的秘密
- RingBuffer预分配内存,避免无谓的垃圾回收
- 对Sequence的value字段,RingBuffer字段,以及RingBuffer的entries数组进行了缓冲行填充,避免缓冲伪共享
- 采用无锁的CAS算法,采用CPU自旋等待,尽量避免使用锁以及阻塞线程
只有为了避免生产者生产速率过低,默认使用了BlockingWaitStrategy,在这里使用了Lock以及Condition.await()/signalAll()。如果确定生产者速度和消费者速度匹配,也可以采用其他的WaitStrategy实现。