一 应用场景描述
最近线上业务的Tomcat总是崩溃停止服务。使用jstat命令查看Java进程的JVM内存信息。但是使用命令jstat只能查看一段时间的数据,不能总是盯着屏幕手动查看,于是想到了将jstat的数据通过zabbix进行绘图展现并报警。同时,一台服务器上可能会有多个Java程序在运行,包括不同的Tomcat,或者是其他Java应用,例如Logstash,Elasticsearch等。这就需要用到Zabbix的Low Level Discovery功能。
二 编写监控脚本
在编写脚本之前需要了解jstat命令的使用,详细使用方法可以参考官方文档或者man手册。还有需要了解JVM虚拟机的内存管理和垃圾回收机制。知道什么是Eden Space,S0 Space,S1 Space和Old Space以及Perm Space等
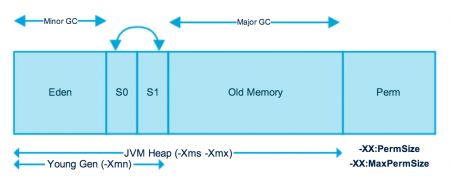
关于Java内存管理和垃圾回收的理论知识可以参考文章
http://www.journaldev.com/2856/java-jvm-memory-model-and-garbage-collection-monitoring-tuning
$ sudo /opt/app/jdk/bin/jstat -gc 30166
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
195904.0 195904.0 19609.5 0.0 1567680.0 561577.4 13769152.0 2668191.5 42944.0 42827.3 8714 345.808 0 0.000 345.808
$ sudo /opt/app/jdk/bin/jstat -gcutil 30166
S0 S1 E O P YGC YGCT FGC FGCT GCT
10.01 0.00 90.27 19.38 99.73 8714 345.808 0 0.000 345.808
$ sudo /opt/app/jdk/bin/jstat -gccapacity 30166
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC PGCMN PGCMX PGC PC YGC FGC
1959488.0 1959488.0 1959488.0 195904.0 195904.0 1567680.0 13769152.0 13769152.0 13769152.0 13769152.0 21248.0 169984.0 42944.0 42944.0 8717 0
-gc 和 -gccapacity显示的大小是KB
显示两行信息
如果通过zabbix agent的方式获取不同字段的值
可以这样
sudo /opt/app/jdk/bin/jstat -gcutil 30166|awk ‘{print $4}’|grep -E ‘1’
如果使用zabbix sender的方式发送数据,可以将显示的结果生成一个python字典
{‘S0’:7.43,‘S1’:0.00,‘E’:86.62’,…}
将这个字典中的数据全部通过zabbix_sender发送到zabbix_proxy或者zabbix_server,需要注意的是zabbix_sender指定的主机名需要和zabbix页面配置的主机名相同
Java服务发现脚本
java_discovery.py
脚本中的发现规则根据情况自己定义,这里定义三个规则,/opt/app/下面所有tomcat-开头的tomcat服务,/opt/logs/logstash/和/opt/app/elasticsearch目录下的规则
#/usr/bin/python
#This script is used to discovery disk on the server
import subprocess
import os
import socket
import json
import glob
java_names_file='java_names.txt'
javas=[]
if os.path.isfile(java_names_file):
# print 'java_names_file exists!'
#####
##### here should use % (java_names_file) instead of using the python variable java_names_file directly inside the ''' ''' quotes
#####
args='''awk -F':' '{print $1':'$2}' %s''' % (java_names_file)
t=subprocess.Popen(args,shell=True,stdout=subprocess.PIPE).communicate()[0]
elif glob.glob('/opt/app/tomcat-*') and not os.path.isdir('/opt/logs/logstash') and not os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen('ls /opt/app/tomcat-*|grep tomcat_',shell=True,stdout=subprocess.PIPE)
elif not glob.glob('/opt/app/tomcat-*') and os.path.isdir('/opt/logs/logstash') and not os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen(''' ls /opt/logs/logstash/|grep -E 'logstash_'|sed 's/.log//g' ''',shell=True,stdout=subprocess.PIPE)
elif not glob.glob('/opt/app/tomcat-*') and not os.path.isdir('/opt/logs/logstash') and os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen(''' ls /opt/app/elasticsearch/config|grep -E 'elasticsearch.yml'| sed 's/.yml//g' ''',shell=True,stdout=subprocess.PIPE)
elif not glob.glob('/opt/app/tomcat-*') and os.path.isdir('/opt/logs/logstash') and os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen(''' ls /opt/logs/logstash /opt/app/elasticsearch/config|grep -E 'logstash_|elasticsearch.yml'| sed 's/.log\|.yml//g' ''',shell=True,stdout=subprocess.PIPE)
elif glob.glob('/opt/app/tomcat-*') and os.path.isdir('/opt/logs/logstash') and not os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen('''ls /opt/app/tomcat-* /opt/logs/logstash/|grep -E 'tomcat_|logstash_'|sed 's/.log//g' ''',shell=True,stdout=subprocess.PIPE)
elif glob.glob('/opt/app/tomcat-*') and os.path.isdir('/opt/logs/logstash') and os.path.isdir('/opt/app/elasticsearch/config'):
t=subprocess.Popen('''ls /opt/app/tomcat-* /opt/logs/logstash/ /opt/app/elasticsearch/config|grep -E 'tomcat_|logstash_|elasticsearch.yml'| sed 's/.log\|.yml//g' ''',shell=True,stdout=subprocess.PIPE)
for java in t.stdout.readlines():
if len(java) != 0:
javas.append({'{#JAVA_NAME}':java.strip('\n')})
print json.dumps({'data':javas},indent=4,separators=(',',':'))
执行结果:
$ python java_discovery.py
{
"data":[
{
"{#JAVA_NAME}":"elasticsearch"
},
{
"{#JAVA_NAME}":"logstash_central"
},
{
"{#JAVA_NAME}":"logstash_shipper"
}
]
}
在模板中的items,graphs,triggers中使用{#JAVA_NAME}这个宏变量
jstat状态信息获取脚本
jstat_status.py
脚本根据https://github.com/gcharot/Zabbix/tree/master/zjstat 这里的代码进行改编
脚本中主要做以下事情:
找到指定Java服务的pid,然后执行jstat命令,然后执行zabbix_sender命令
#!/usr/bin/python
import subprocess
import sys
import os
__maintainer__ = "John Wang"
jps = '/opt/app/jdk/bin/jps'
jstat = '/opt/app/jdk/bin/jstat'
zabbix_sender = "/opt/app/zabbix/sbin/zabbix_sender"
zabbix_conf = "/opt/app/zabbix/conf/zabbix_agentd.conf"
send_to_zabbix = 1
#"{#JAVA_NAME}":"tomcat_web_1"
def usage():
"""Display program usage"""
print "\nUsage : ", sys.argv[0], " java_name alive|all"
print "Modes : \n\talive : Return pid of running processs\n\tall : Send jstat stats as well"
sys.exit(1)
class Jprocess:
def __init__(self, arg):
self.pdict = {
"jpname": arg,
}
self.zdict = {
"Heap_used" : 0,
"Heap_ratio" : 0,
"Heap_max" : 0,
"Perm_used" : 0,
"Perm_ratio" : 0,
"Perm_max" : 0,
"S0_used" : 0,
"S0_ratio" : 0,
"S0_max" : 0,
"S1_used" : 0,
"S1_ratio" : 0,
"S1_max" : 0,
"Eden_used" : 0,
"Eden_ratio" : 0,
"Eden_max" : 0,
"Old_used" : 0,
"Old_ratio" : 0,
"Old_max" : 0,
"YGC" : 0,
"YGCT" : 0,
"YGCT_avg" : 0,
"FGC" : 0,
"FGCT" : 0,
"FGCT_avg" : 0,
"GCT" : 0,
"GCT_avg" : 0,
}
def chk_proc(self):
# ps -ef|grep java|grep tomcat_web_1|awk '{print $2}'
# print self.pdict['jpname']
pidarg = '''ps -ef|grep java|grep %s|grep -v grep|awk '{print $2}' ''' %(self.pdict['jpname'])
pidout = subprocess.Popen(pidarg,shell=True,stdout=subprocess.PIPE)
pid = pidout.stdout.readline().strip('\n')
if pid != "" :
self.pdict['pid'] = pid
# print "Process found :", java_name, "with pid :", self.pdict['pid']
else:
self.pdict['pid'] = ""
# print "Process not found"
return self.pdict['pid']
def get_jstats(self):
if self.pdict['pid'] == "":
return False
self.pdict.update(self.fill_jstats("-gc"))
self.pdict.update(self.fill_jstats("-gccapacity"))
self.pdict.update(self.fill_jstats("-gcutil"))
# print "\nDumping collected stat dictionary\n-----\n", self.pdict, "\n-----\n"
def fill_jstats(self, opts):
# print "\nGetting", opts, "stats for process", self.pdict['pid'], "with command : sudo", jstat, opts, self.pdict['pid'] ,"\n"
jstatout = subprocess.Popen(['sudo', jstat, opts, self.pdict['pid']], stdout=subprocess.PIPE)
stdout, stderr = jstatout.communicate()
legend, data = stdout.split('\n',1)
mydict = dict(zip(legend.split(), data.split()))
return mydict
def compute_jstats(self):
if self.pdict['pid'] == "":
return False
self.zdict['S0_used'] = format(float(self.pdict['S0U']) * 1024,'0.2f')
self.zdict['S0_max'] = format(float(self.pdict['S0C']) * 1024,'0.2f')
self.zdict['S0_ratio'] = format(float(self.pdict['S0']),'0.2f')
self.zdict['S1_used'] = format(float(self.pdict['S1U']) * 1024,'0.2f')
self.zdict['S1_max'] = format(float(self.pdict['S1C']) * 1024,'0.2f')
self.zdict['S1_ratio'] = format(float(self.pdict['S1']),'0.2f')
self.zdict['Old_used'] = format(float(self.pdict['OU']) * 1024,'0.2f')
self.zdict['Old_max'] = format(float(self.pdict['OC']) * 1024,'0.2f')
self.zdict['Old_ratio'] = format(float(self.pdict['O']),'0.2f')
self.zdict['Eden_used'] = format(float(self.pdict['EU']) * 1024,'0.2f')
self.zdict['Eden_max'] = format(float(self.pdict['EC']) * 1024,'0.2f')
self.zdict['Eden_ratio'] = format(float(self.pdict['E']),'0.2f')
self.zdict['Perm_used'] = format(float(self.pdict['PU']) * 1024,'0.2f')
self.zdict['Perm_max'] = format(float(self.pdict['PC']) * 1024,'0.2f')
self.zdict['Perm_ratio'] = format(float(self.pdict['P']),'0.2f')
self.zdict['Heap_used'] = format((float(self.pdict['EU']) + float(self.pdict['S0U']) + float(self.pdict['S1U']) + float(self.pdict['OU'])) * 1024,'0.2f')
self.zdict['Heap_max'] = format((float(self.pdict['EC']) + float(self.pdict['S0C']) + float(self.pdict['S1C']) + float(self.pdict['OC'])) * 1024,'0.2f')
self.zdict['Heap_ratio'] = format(float(self.zdict['Heap_used']) / float(self.zdict['Heap_max'])*100,'0.2f')
self.zdict['YGC'] = self.pdict['YGC']
self.zdict['FGC'] = self.pdict['FGC']
self.zdict['YGCT'] = format(float(self.pdict['YGCT']),'0.3f')
self.zdict['FGCT'] = format(float(self.pdict['FGCT']),'0.3f')
self.zdict['GCT'] = format(float(self.pdict['GCT']),'0.3f')
if self.pdict['YGC'] == '0':
self.zdict['YGCT_avg'] = '0'
else:
self.zdict['YGCT_avg'] = format(float(self.pdict['YGCT'])/float(self.pdict['YGC']),'0.3f')
if self.pdict['FGC'] == '0':
self.zdict['FGCT_avg'] = '0'
else:
self.zdict['FGCT_avg'] = format(float(self.pdict['FGCT'])/float(self.pdict['FGC']),'0.3f')
if self.pdict['YGC'] == '0' and self.pdict['FGC'] == '0':
self.zdict['GCT_avg'] = '0'
else:
self.zdict['GCT_avg'] = format(float(self.pdict['GCT'])/(float(self.pdict['YGC']) + float(self.pdict['FGC'])),'0.3f')
# print "Dumping zabbix stat dictionary\n-----\n", self.zdict, "\n-----\n"
def send_to_zabbix(self, metric):
#### {#JAVA_NAME} tomcat_web_1
#### UserParameter=java.discovery,/usr/bin/python /opt/app/zabbix/sbin/java_discovery.py
#### UserParameter=java.discovery_status[*],/opt/app/zabbix/sbin/jstat_status.sh $1 $2 $3 $4
#### java.discovery_status[tomcat_web_1,Perm_used]
#### java.discovery_status[{#JAVA_NAME},Perm_used]
key = "java.discovery_status[" + self.pdict['jpname'] + "," + metric + "]"
if self.pdict['pid'] != "" and send_to_zabbix > 0:
# print key + ":" + self.zdict[metric]
try:
subprocess.call([zabbix_sender, "-c", zabbix_conf, "-k", key, "-o", self.zdict[metric]], stdout=FNULL, stderr=FNULL, shell=False)
except OSError, detail:
print "Something went wrong while exectuting zabbix_sender : ", detail
else:
print "Simulation: the following command would be execucted :\n", zabbix_sender, "-c", zabbix_conf, "-k", key, "-o", self.zdict[metric], "\n"
accepted_modes = ['alive', 'all']
if len(sys.argv) == 3 and sys.argv[2] in accepted_modes:
java_name = sys.argv[1]
mode = sys.argv[2]
else:
usage()
#Check if process is running / Get PID
jproc = Jprocess(java_name)
pid = jproc.chk_proc()
if pid != "" and mode == 'all':
jproc.get_jstats()
jproc.compute_jstats()
FNULL = open(os.devnull, 'w')
for key in jproc.zdict:
jproc.send_to_zabbix(key)
FNULL.close()
print pid
else:
print 0
执行这个脚本之前需要使zabbix agent账号具有执行jstat的sudo权限
echo -e "zabbixagent ALL=(root) NOPASSWD:/usr/bin/jstat,/opt/app/jdk/bin/jstat" >>/etc/sudoers
sed -i 's/Defaults requiretty/Defaults !requiretty/' /etc/sudoers
调试结果如下:
$ sudo python jstat_status.py elasticsearch all
java.discovery_status[elasticsearch,Perm_ratio]:99.73
java.discovery_status[elasticsearch,GCT_avg]:0.040
java.discovery_status[elasticsearch,S1_max]:200605696.00
java.discovery_status[elasticsearch,Heap_max]:16106127360.00
java.discovery_status[elasticsearch,Perm_used]:43855155.20
java.discovery_status[elasticsearch,Perm_max]:43974656.00
java.discovery_status[elasticsearch,YGCT_avg]:0.040
java.discovery_status[elasticsearch,Old_max]:14099611648.00
java.discovery_status[elasticsearch,S1_ratio]:0.00
java.discovery_status[elasticsearch,FGCT_avg]:0
java.discovery_status[elasticsearch,FGC]:0
java.discovery_status[elasticsearch,Heap_used]:3156421529.60
java.discovery_status[elasticsearch,Eden_max]:1605304320.00
java.discovery_status[elasticsearch,Old_used]:2748808294.40
java.discovery_status[elasticsearch,Eden_used]:392617062.40
java.discovery_status[elasticsearch,YGC]:8794
java.discovery_status[elasticsearch,YGCT]:348.801
java.discovery_status[elasticsearch,Eden_ratio]:25.08
java.discovery_status[elasticsearch,S0_used]:14996172.80
java.discovery_status[elasticsearch,FGCT]:0.000
java.discovery_status[elasticsearch,Old_ratio]:19.50
java.discovery_status[elasticsearch,Heap_ratio]:19.60
java.discovery_status[elasticsearch,S0_ratio]:7.48
java.discovery_status[elasticsearch,S1_used]:0.00
java.discovery_status[elasticsearch,S0_max]:200605696.00
java.discovery_status[elasticsearch,GCT]:348.801
30166
注释掉调试信息:
$ sudo python jstat_status.py elasticsearch all
30166
添加zabbix配置文件
$ cat …/conf/zabbix_agentd.conf.d/discovery_java_status.conf
UserParameter=java.discovery,/usr/bin/python /opt/app/zabbix/sbin/java_discovery.py
UserParameter=java.discovery_status[*],/usr/bin/python /opt/app/zabbix/sbin/jstat_status.py $1 $2
三 添加监控模板
模板参见附件
模板中只有一个item是通过zabbix agent获取,其他的都是通过zabbix sender获取
java.discovery_status[{#JAVA_NAME},all]
zabbix通过zabbix agent获取这个item的值时会调用jstat_status.py这个脚本通过zabbix_sender



欢迎工作一到五年的Java工程师朋友们加入Java高并发: 957734884,群内提供免费的Java架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!
0-9 ↩︎