简介
由于项目中需要使用kafka作为消息队列,并且项目是基于spring-boot来进行构建的,所以项目采用了spring-kafka作为原生kafka的一个扩展库进行使用。先说明一下版本:
- spring-boot 的版本是1.4.0.RELEASE
- kafka 的版本是0.9.0.x 版本
- spring-kafka 的版本是1.0.3.RELEASE
用过kafka的人都知道,对于使用kafka来说,producer的使用相对简单一些,只需要把数据按照指定的格式发送给kafka中某一个topic就可以了。本文主要是针对spring-kafka的consumer端上的使用进行简单一些分析和总结。
kafka的速度是很快,所以一般来说producer的生产消息的逻辑速度都会比consumer的消费消息的逻辑速度快。
具体案例
之前在项目中遇到了一个案例是,consumer消费一条数据平均需要200ms的时间,并且在某个时刻,producer会在短时间内产生大量的数据丢进kafka的broker里面(假设平均1s中内丢入了5w条需要消费的消息,这个情况会持续几分钟)。
对于这种情况,kafka的consumer的行为会是:
- kafka的consumer会从broker里面取出一批数据,�给消费线程进行消费。
- 由于取出的一批消息数量太大,consumer在session.timeout.ms时间之内没有消费完成
- consumer coordinator 会由于没有接受到心跳而挂掉,并且出现一些日志
日志的意思大概是coordinator挂掉了,然后自动提交offset失败,然后重新分配partition给客户端 - 由于自动提交offset失败,导致重新分配了partition的客户端又重新消费之前的一批数据
- 接着consumer重新消费,又出现了消费超时,无限循环下去。
解决方案
遇到了这个问题之后, 我们做了一些步骤:
- 提高了partition的数量,从而提高了consumer的并行能力,从而提高数据的消费能力
- 对于单partition的消费线程,增加了一个固定长度的阻塞队列和工作线程池进一步提高并行消费的能力
- 由于使用了spring-kafka,则把kafka-client的enable.auto.commit设置成了false,表示禁止kafka-client自动提交offset,因为就是之前的自动提交失败,导致offset永远没更新,从而转向使用spring-kafka的offset提交机制。并且spring-kafka提供了多种提交策略:
这些策略保证了在一批消息没有完成消费的情况下,也能提交offset,从而避免了完全提交不上而导致永远重复消费的问题。
分析
那么问题来了,为什么spring-kafka的提交offset的策略能够解决spring-kafka的auto-commit的带来的重复消费的问题呢?下面通过分析spring-kafka的关键源码来解析这个问题。
首先来看看spring-kafka的消费线程逻辑
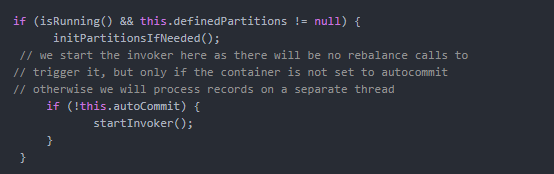
-
上面可以看到,如果auto.commit关掉的话,spring-kafka会启动一个invoker,这个invoker的目的就是启动一个线程去消费数据,他消费的数据不是直接从kafka里面直接取的,那么他消费的数据从哪里来呢?他是从一个spring-kafka自己创建的阻塞队列里面取的。
-
然后会进入一个循环,从源代码中可以看到如果auto.commit被关掉的话, 他会先把之前处理过的数据先进行提交offset,然后再去从kafka里面取数据。
-
然后把取到的数据丢给上面提到的阻塞列队,由上面创建的线程去消费,并且如果阻塞队列满了导致取到的数据塞不进去的话,spring-kafka会调用kafka的pause方法,则consumer会停止从kafka里面继续再拿数据。
-
接着spring-kafka还会处理一些异常的情况,比如失败之后是不是需要commit offset这样的逻辑。
方法二
- 可以根据消费者的消费速度对session.timeout.ms的时间进行设置,适当延长
- 或者减少每次从partition里面捞取的数据分片的大小,提高消费者的消费速度。