文章目录
一: java基本数据类型
java一共有8个基本数据类型,其中4个整型,2个浮点类型,1个布尔类型,1个字符类型.
1.1 整型
- byte 1字节
- short 2字节
- int 4字节 有效位数为9位
- long 8字节
1.2 浮点类型
- float 4字节 有效位数位6~7位
- double 8字节
double 表示这种类型的数值精度是 float 类型的两倍(有人称之为双精度数值)。绝大数情况都是使用double类型,少数情况使用float类型,比如需要单精度操作, 或者存储大量的数据.
- 特殊的浮点数值
- Double_POSITIVE_INFINITY : 正无穷大
- Double.NEGATIVEJNFINITY : 负无穷大
- Double.NaN : 不是一个数字
1.3 char类型
- char类型的字面量值要用单引号括起来
- char类型原本表示单个的字符,现在有些unicode字符可以用一个char值描述,另外一个unicode则需要两个字符描述.
- char类型的值可以表示为16进制,其范围为 \u0000 到 \Uffff,例如: \u2122 表示注册符号
™, \u03C0 表示希腊字母π - 特殊字符的转义序列
| 转义序列 | 名称 | Unicode值 |
|---|---|---|
| \b | 退格 | \u0008 |
| \t | 制表符 | \u0009 |
1.4 Unicode 和 char 类型 (重点)
要想弄清 char 类型, 就必须了解 Unicode 编码机制。Unicode 打破了传统字符编码机制 的限制。在 Unicode 出现之前, 已经有许多种不同的标准:美国的 ASCII、 西欧语言中的 ISO 8859-1 俄罗斯的 KOI-8、 中国的 GB 18030 和 BIG-5 等。这样就产生了下面两个问题: 一个是对于任意给定的代码值,在不同的编码方案下有可能对应不同的字母;二是采用大字 符集的语言其编码长度有可能不同。例如,有些常用的字符采用单字节编码, 而另一些字符 则需要两个或更多个字节。
设计 Unicode 编码的目的就是要解决这些问题。在 20世纪 80 年代开始启动设计工作时, 人们认为两个字节的代码宽度足以对世界上各种语言的所有字符进行编码, 并有足够的空间 留给未来的扩展。在 1991 年发布了 Unicode 1.0, 当时仅占用 65 536 个代码值中不到一半的 部分。在设计 Java 时决定采用 16 位的 Unicode 字符集,这样会比使用 8 位字符集的程序设 计语言有很大的改进。
十分遗憾, 经过一段时间, 不可避免的事情发生了。Unicode 字符超过了 65 536 个,其 主要原因是增加了大量的汉语、 日语和韩语中的表意文字。现在, 16 位的 char 类型已经不 能满足描述所有 Unicode 字符的需要了。
下面利用一些专用术语解释一下 Java语言解决这个问题的基本方法。从 Java SE 5.0 开 始。码点(code point) 是指与一个编码表中的某个字符对应的代码值。在 Unicode 标准中, 码点采用十六进制书写,并加上前缀 U+, 例如 U+0041 就是拉丁字母 A 的码点。Unicode 的 码点可以分成 17 个代码级别(codeplane)。第一个代码级别称为基本的多语言级别(basic multilingual plane), 码点从 U+0000 到 U+FFFF, 其中包括经典的 Unicode 代码;其余的 16 个级另丨 〗码点从 U+10000 到 U+10FFFF, 其中包括一些辅助字符(supplementary character)。
UTF-16 编码采用不同长度的编码表示所有 Unicode 码点。在基本的多语言级别中,每个 字符用 16 位表示,通常被称为代码单元(code unit); 而辅助字符采用一对连续的代码单元 进行编码。这样构成的编码值落人基本的多语言级别中空闲的 2048字节内, 通常被称为替 代区域(surrogate area) [ U+D800 ~ U+DBFF 用于第一个代码单兀,U+DC00 ~ U+DFFF 用 于第二个代码单元]。这样设计十分巧妙,我们可以从中迅速地知道一个代码单元是一个字 符的编码,还是一个辅助字符的第一或第二部分。例如,⑪是八元数集(http://math.ucr.edu/ home/baez/octonions) 的一个数学符号,码点为 U+1D546, 编码为两个代码单兀 U+D835 和 U+DD46。(关于编码算法的具体描述见 http://en.wikipedia.org/wiki/UTF-l6 )
在 Java中,char 类型描述了 UTF-16 编码中的一个代码单。
我们强烈建议不要在程序中使用 char 类型,除非确实需要处理 UTF-16 代码单元。最好 将字符串作为抽象数据类型处理
1.5 boolean类型
- boolean类型有两个值: true 和 false,用来判定逻辑条件,整型值和布尔值之间不能相互转换.
二 : 变量
- 不能使用未初始化的变量.
- 必须初始化.
三 : 常量
- 定义一个常量使用final修饰符修饰.
- 常量被定义后就不能够被修改.
- 常量必须初始化.
- 要大写
四 : 运算符
- +
- -
- *
- /
- 整数被0除会得到一个异常
- 浮点数被零除则会得到
Infinity: 表示无穷
- %
五 : 数学函数与常量
在 Math类中,包含了各种各样的数学函数。在编写不同类别的程序时,可能需要的函 数也不同。
- 计算一个数值的平方根 : Math.sqrt(x)
- 在 Java中,没有幂运算, 因此需要借助于 Math 类的 pow方法
- double y = Math.pow(x, a);
- 比如 3 的 2 次幂是 9.0
- 将 y的值设置为 x 的 a 次幂(xa)。pow方法有两个 double类型的参数, 其返回结果也为 double 类型。
- Math 类提供了一些常用的三角函数:
- Math.sin
- Math.cos
- Math.tan
- Math.atan
- Math.atan2
- 还有指数函数以及它的反函数— —自然对数以及以 10 为底的对数:
- Math.exp
- Math.log
- Math.loglO
- Java 还提供了两个用于表示 π 和 e 常量的近似值:
- Math.PI
- Math.E
- 四舍五入:
- Math_round
不必在数学方法名和常量名前添加前缀“ Math”,只要在源文件的顶部加上下面 这行代码就可以了。
import static java.1ang.Math.*; //静态导入
System.out.println(pow(3,3));
六 : 数值类型之间的转换
6.1 自动转换
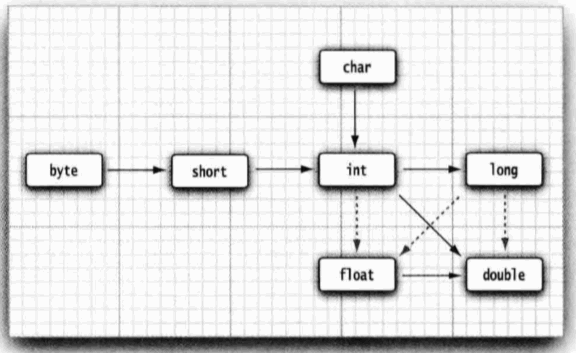
虚线表示会损失精度,实线表示不会损失精度.
- 123 456 789 是一个大整数, 它所包含的位数比 float 类型所能够表达的 位数多。 当将这个整型数值转换为 float 类型时,将会得到同样大小的结果,但却失去了一定 的精度。
int n = 123456789;
float f= n;//f is 1.23456792E8
- 当使用上面两个数值进行二元操作时(例如 n + f,n 是整数,f 是浮点数), 先要将两个操作数转换为同一种类型,然后再进行计算。
如果两个操作数中有一个是 double 类型, 另一个操作数就会转换为 double 类型。
否则,如果其中一个操作数是 float 类型,另一个操作数将会转换为 float 类型。
否则, 如果其中一个操作数是 long 类型, 另一个操作数将会转换为 long 类型。
否则, 两个操作数都将被转换为 int 类型。
6. 2 强制类型转换
- 强制类型转换的语法格式是在圆括号中给出想要转换的目标类型,后面紧跟待转换的变 量名。例如:
double x = 9.997;
int nx = (int) x;
强制类型转换可能会丢失一些信息
7 位运算符
- 处理整型类型时,可以直接对组成整型数值的各个位完成操作。这意味着可以使用掩码 技术得到整数中的各个位。位运算符包括:
& ("and") | ("or") ^ ("XOr") ~("not") - >> 和 <<运算符将位模式左移或右移。需要建立位模式来完成位掩码时, 这 两个运算符会很方便:
int fourthBitFromRight = (n & (1« 3)) » 3; - 最后,>>> 运算符会用 0 填充高位,这与>>不同,它会用符号位填充高位。不存在<<< 运算符。
八 : 枚举类型
- 有时候,变量的取值只在一个有限的集合内。例如: 销售的服装或比萨饼只有小、中、 大和超大这四种尺寸。当然, 可以将这些尺寸分别编码为 1、2、3、4 或 S、 M、 L、X。但 这样存在着一定的隐患。在变量中很可能保存的是一个错误的值(如 0 或 m)。 针对这种情况, 可以自定义枚举类型。枚举类型包括有限个命名的值。 例如,
e_Size {SMALL, MEDIUM, LARGE, EXTRA.LARCE}; - 现在,可以声明这种类型的变量:
Size s = Size.MEDIUM; - Size类型的变量只能存储这个类型声明中给定的某个枚举值,或者 null 值,null 表示这 个变量没有设置任何值。