今天内容:对象流,Properties,随机访问对象,控制台输入输出
功能流
对象序列化的意义
| 在Java中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用此对象。但是,我们创建出来的这些对象都存在于JVM中的堆(stack)内存中,只有JVM处于运行状态的时候,这些对象才可能存在。一旦JVM停止,这些对象也就随之消失; 但是在真实的应用场景中,我们需要将这些对象持久化下来,并且在需要的时候将对象重新读取出来,Java的序列化可以帮助我们实现该功能。 对象序列化机制(object serialization)是java语言内建的一种对象持久化方式,通过对象序列化,可以将对象的状态信息保存未字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式转换成对象,对象的序列化可以很容易的在JVM中的活动对象和字节数组(流)之间进行转换。 在JAVA中,对象的序列化和反序列化被广泛的应用到RMI(远程方法调用)及网络传输中; |
对象流ObjectInputStream & ObjectOutputStream
可以操作所有类型的数据,基本类型,引用类型都可以。对象流中最重要的两个方法就是readObject()和writeObject().
ObjectOutputStream:OOS
- 将对象永久性的存储到某一介质(网络,文件等)中,称之为序列化。
- ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream。可以使用 ObjectInputStream 读取(重构)对象。通过在流中使用文件可以实现对象的持久存储。
- OOS是按照字节数据写入文件的,不能直接操作文件,所以需要使用FileOutputStream写入。
- 注意:是按照字节顺序写入的
-
import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.util.ArrayList; public class Demo2 {//可以操作任意类型数据 public static void main(String[] args) throws IOException { //序列化数据 ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("D:\\aa.txt")); byte by=22;//byte类型数据 int num=10;//int类型数据 char ch='a';//字符类型数据 int[] arr=new int[]{1,2,3};//数据,引用类型 String str="you are my sunshine";//字符串类型 ArrayList<String> list=new ArrayList<>();//集合,引用类型 list.add("aa"); list.add("ATT"); oos.writeByte(by);//写入字节类型数据 oos.writeInt(num);//写入int型数据 oos.writeChar(ch);//写入字符型数据 oos.writeObject(arr);//写入引用型数据-数组 oos.writeUTF(str);//写入字符串-writeUTF oos.writeObject(list);//写入引用型数据 oos.close();//闭流 System.out.println("Done!"); } }
ObjectIntputStream:OIS
- 从某一介质中将对象的信息获取到,称之为 反序列化。
- 只能操作OOS中存储的数据。
- 是按照OOS写入的字节顺序读取文件的,顺序不能乱,否则可能读取乱码。
-
import java.io.FileInputStream; import java.io.IOException; import java.io.ObjectInputStream; import java.util.ArrayList; import java.util.Arrays; public class Demo3 { public static void main(String[] args)throws IOException, ClassNotFoundException { //反序列化数据 ObjectInputStream ois=new ObjectInputStream(new FileInputStream("D:\\aa.txt")); int a=ois.readByte(); int b=ois.readInt(); char c=ois.readChar(); //注意引用类型存入的时候都是以Object类型存入的,读取的时候也要以Object读取,想要看到原始内容就需要进行类型转换 int[] d=(int [])ois.readObject(); String e=ois.readUTF(); @SuppressWarnings("unchecked") ArrayList<String> f=(ArrayList<String>)ois.readObject(); //输出 System.out.println(a); System.out.println(b); System.out.println(c); System.out.println(Arrays.toString(d));//数组不能直接输出,可以调用数组工具类方法 System.out.println(e); System.out.println(f); } }
自定义对象序列化和反序列化
类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
自定义对象想要进行序列化,必须具备序列化功能才可以,即实现Serializable接口,该接口没有方法和字段,成为标记接口,只是起到一个标记的作用。那么为什么普通数据类型和引用数据类型可以直接使用序列化和反序列化呢?--因为他们的类已经实现了这个接口。
@Test
public void test1() throws IOException, ClassNotFoundException{//反序列化
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("D:\\obj.txt"));//创建对象输入流对象
Person p=(Person)ois.readObject();//由于对象输入流读取的都是Object类型,所以要强制转型
System.out.println(p);
ois.close();//一定记得要关流
}
//自定义类
class Person implements Serializable{//自定义类要实现serializable接口才可以实现反序列化
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public String toString() {
return name+"---"+age;
}
}进行反序列化时,易出现EOFException(当输入过程中意外到达文件或流的末尾时,抛出此异常。),表示到达流的末尾,即没有对象可进行反序列化,为了防止异常产生,可以将想要进行序列化的对象都存储到集合中,反序列化该集合即可。为什么使用集合就不会出现异常呢?因为只调用了一次read方法,读取了这个集合,剩下的元素怎么输出就是集合的事情了,不会出现EOFException。
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.ArrayList;
import org.junit.Test;
//自定义对象的序列化
public class Demo4 {
public static void main(String[] args) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\obj.txt"));
ArrayList<Person> list = new ArrayList<>();// 定义一个集合用来存放所有对象,以防反序列化时出现意外到达末尾的异常
list.add(new Person("zhangsan", 20));
list.add(new Person("lisi", 21));
list.add(new Person("wangwu", 22));
list.add(new Person("zhaoliu", 23));
list.add(new Person("张三", 24));
oos.writeObject(list);// 直接将集合序列化就可以了
System.out.println("Done!");
oos.close();
}
@Test
public void test1() throws IOException, ClassNotFoundException {// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("D:\\obj.txt"));// 创建对象输入流对象
// 由于对象输入流读取的都是Object类型,所以要强制转型成序列化时的ArrayList,然后再遍历即可
ArrayList<Person> list = (ArrayList<Person>) ois.readObject();
for (Person p1 : list) {
System.out.println(p1);
}
ois.close();// 一定记得要关流
}
}
// 自定义类
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + "---" + age;
}
}由于class文件默认会有一个版本号,一旦对内容作了修改,就会生成一个新的版本号,如果反序列化时class文件版本号不一致,会出现InvalidClassException,解决办法即让class文件始终使用同一个版本号。即在类定义的时候加上以下信息:
修饰符 static final long serialVersionUID = 常量值即可。

当更改了序列化源类中的信息且没有运行序列化方法时,会报上面的异常。解决办法如下:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.ArrayList;
import org.junit.Test;
//自定义对象的序列化
public class Demo4 {
public static void main(String[] args) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\obj.txt"));
ArrayList<Person> list = new ArrayList<>();// 定义一个集合用来存放所有对象,以防反序列化时出现意外到达末尾的异常
list.add(new Person("zhangsan", 20));
list.add(new Person("lisi", 21));
list.add(new Person("wangwu", 22));
list.add(new Person("zhaoliu", 23));
list.add(new Person("张三", 24));
oos.writeObject(list);// 直接将集合序列化就可以了
System.out.println("Done!");
oos.close();
}
@Test
public void test1() throws IOException, ClassNotFoundException {// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("D:\\obj.txt"));// 创建对象输入流对象
// 由于对象输入流读取的都是Object类型,所以要强制转型成序列化时的ArrayList,然后再遍历即可
ArrayList<Person> list = (ArrayList<Person>) ois.readObject();
for (Person p1 : list) {
System.out.println(p1);
}
ois.close();// 一定记得要关流
}
}
// 自定义类
class Person implements Serializable {
private static final long serialVersionUID = 1L;//修饰符和=号右面的常量值可以改变
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + "---" + age;
}
}
总结:
- 将对象的属性值进行序列化;
- 父类一旦具备了序列化功能,他的子类也就自动具有了序列化功能;
- static修饰的属性不能进行序列化,因为他不参与创建对象,而序列化是针对对象而言的,ObjectOutputstream
- 如果某个成员属性不想进行序列化,可以使用瞬态关键字 transient 来修饰他,这样被修饰的那个成员变量就只能保存在内存中了。
- 与系统有关的对象不能进行序列化,比如System,Thread等。
Properties类:
Properties 类表示了一个持久的属性集。Properties 可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
他本身属于Map集合中的一员(直接继承了Hashtable),但是他又可以和IO流结合使用。Properties类本身存放着key和value这样具有一定个对应关系的数据,当和IO流结合在一起的时候,可以直接将集合中的数据存储在指定的文件中,或者从文件加载数据,当数据加载完成之后,数据就已经被存放在集合中了。
用于永久的存储属性集,属性名=属性值,他俩都必须是字符串。
他既可以将属性集存储到流中,又可以从流中读取属性集。
直接继承了Hashtable,因此存储的属性集,即是key-value,可以使用Hashtable中的put和get方法来进行增加和获取操作,但是不建议使用,因为Properties中的可以和value必须是字符串而Hashtable中的数据可以是任意类型的,所以我们使用Properties中自带的方法:
Object |
setProperty(String key, String value) 调用 Hashtable 的方法 put |
调用 Hashtable 方法 put,使用 getProperty 方法提供并行性。强制要求为属性的键和值使用字符串。返回值是 Hashtable 调用 put 的结果
参数:
key - 要置于属性列表中的键。
value - 对应于 key 的值。
返回:
属性列表中指定键的旧值,如果没有值,则为 null。
String |
getProperty(String key) 用指定的键在此属性列表中搜索属性。 |
用指定的键在此属性列表中搜索属性。如果在此属性列表中未找到该键,则接着递归检查默认属性列表及其默认值。如果未找到属性,则此方法返回 null。
参数:
key - 属性键。
返回:
属性列表中具有指定键值的值。
构造方法:
Properties() 创建一个无默认值的空属性列表。 |
Properties(Properties defaults) 创建一个带有指定默认值的空属性列表。 |

遍历:类似于Map中的keySet()方法,先获得key然后再遍历,也可以直接使用Map中的keySet遍历。
Enumeration<?> |
propertyNames() 返回属性列表中所有键的枚举,如果在主属性列表中未找到同名的键,则包括默认属性列表中不同的键。 |
import java.util.Enumeration;
import java.util.Iterator;
import java.util.Properties;
import java.util.Set;
public class Demo5 {
public static void main(String[] args) {
Properties prop=new Properties();
prop.setProperty("张三", "20");
prop.setProperty("李四", "22");
System.out.println(prop);
System.out.println(prop.getProperty("张三"));
//遍历
//propertyNames()方法获取所有的key值,是一个Enumeration枚举
Enumeration<String> keys=(Enumeration<String>)prop.propertyNames();
while(keys.hasMoreElements()){
String key=keys.nextElement();//获取key值
String value=prop.getProperty(key);//用prop.getProperty()方法获取对应的value值
System.out.println(key+"---"+value);
}
//也可以用Hashtable中的keySet方法
Set<Object> set=(Set<Object>)prop.keySet();
Iterator<Object> it=set.iterator();//注意迭代器不要和for-each遍历搞混淆
while(it.hasNext()){
String key=(String)it.next();
String value=prop.getProperty(key);//prop.getProperty()方法通过key获取value值
System.out.println(key+"---"+value);
}
}
}import java.util.Enumeration;
import java.util.Iterator;
import java.util.Properties;
import java.util.Set;
public class Demo5 {
public static void main(String[] args) {
Properties prop=new Properties();
prop.setProperty("张三", "20");
prop.setProperty("李四", "22");
System.out.println(prop);
System.out.println(prop.getProperty("张三"));
//遍历
//propertyNames()方法获取所有的key值,是一个Enumeration枚举
Enumeration<String> keys=(Enumeration<String>)prop.propertyNames();
while(keys.hasMoreElements()){
String key=keys.nextElement();//获取key值
String value=prop.getProperty(key);//用prop.getProperty()方法获取对应的value值
System.out.println(key+"---"+value);
}
//也可以用Hashtable中的keySet方法
Set<Object> set=(Set<Object>)prop.keySet();
Iterator<Object> it=set.iterator();//注意迭代器不要和for-each遍历搞混淆
while(it.hasNext()){
String key=(String)it.next();
String value=prop.getProperty(key);//prop.getProperty()方法通过key获取value值
System.out.println(key+"---"+value);
}
}
}store()和load()方法:
store(字节输出流/字符输出流,"注释"):将属性存储到流中;
load(字节输入流/字符输入流):将流中的属性加载到Properties
注意:
- 与流关联的文件建议使用properties作为文件后缀名,存储是如果有中文会显示对应的Unicode码值而不会显示中文
- key和value以及"="中间不能出现空格,因为空格也是字符
void |
store(OutputStream out, String comments) 以适合使用 load(InputStream) 方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。 |
void |
load(InputStream inStream) 从输入流中读取属性列表(键和元素对)。 |
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
//store方法演示
public class Demo6 {
public static void main(String[] args) throws IOException {
//store
Properties prop=new Properties();
prop.setProperty("张三", "20");
prop.setProperty("李四", "22");
prop.store(new FileOutputStream("D:\\aaa.prop"), "you are mine ATT");
System.out.println("Done!");
}
}
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
import org.junit.Test;
//store和load方法演示
public class Demo6 {
public static void main(String[] args) throws IOException {
//store
Properties prop=new Properties();
prop.setProperty("张三", "20");
prop.setProperty("李四", "22");
prop.store(new FileOutputStream("D:\\aaa.prop"), "you are mine ATT");
System.out.println("Done!");
}
@Test
public void loadDmeo() throws IOException{
Properties prop=new Properties();
prop.load(new FileInputStream("D:\\aaa.prop"));
System.out.println(prop);//prop调用了load方法,他加载到了这个属性文件,拥有了他的信息,所以输出prop就能看到想要看到的信息了
}
}![]() 加载后输出的是默认的格式
加载后输出的是默认的格式
随机访问流对象RandomAccessFile
不属于IO体系,是操作文件的,该对象既可以读取数据又可以写入数据。
此类的实例支持对随机访问文件的读取和写入。随机访问文件的行为类似存储在文件系统中的一个大型 byte 数组。存在指向该隐含数组的光标或索引,称为文件指针;输入操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针。如果随机访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针。写入隐含数组的当前末尾之后的输出操作导致该数组扩展。该文件指针可以通过 getFilePointer 方法读取,并通过 seek 方法设置。
文件都有读写模式,所以构造方法提供了读写模式的选择,只读:r,读写:rw
RandomAccessFile(File file, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。 |
RandomAccessFile(String name, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件具有指定名称。 |
import java.io.IOException;
import java.io.RandomAccessFile;
//随机访问对象
public class Demo7 {
public static void main(String[] args) throws IOException {
RandomAccessFile raf=new RandomAccessFile("abc.txt", "rw");
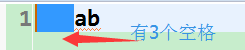
//写入一个int类型的数据,一个int占用4个8位(4个字节),而97只占一个8位,也就是最低的8位,
//所以前面会有3个空格
raf.writeInt(97);
raf.write(98);//write是直接写入一个字节,所以直接写入没有空格
raf.close();
}
}
import java.io.IOException;
import java.io.RandomAccessFile;
//随机访问对象
public class Demo7 {
public static void main(String[] args) throws IOException {
RandomAccessFile raf=new RandomAccessFile("abc.txt", "rw");
raf.write(97);
System.out.println(raf.getFilePointer());//获取指针位置,返回1,因为写入一个数据指针后移了
raf.close();
}
}import java.io.IOException;
import java.io.RandomAccessFile;
//随机访问对象
public class Demo7 {
public static void main(String[] args) throws IOException {
RandomAccessFile raf=new RandomAccessFile("abc.txt", "rw");
raf.write(97);
System.out.println(raf.getFilePointer());//获取指针位置,返回1,因为写入一个数据指针后移了
raf.seek(5);//将光标设置到5的位置
raf.write(98);
raf.close();
}
}
方法:
writeXxx():写基本类型数据
writeUTF():写字符串,也可以按照字节流中写字节数据的方式写入数据
readXxx():读取基本类型数据
readUTF():读取字符串,也可以按照字节流中读取字节数据的方式进行读取数据
控制台输入
InputStream=System.in
OutputStream=Syste.out
public class Demo8 throws Exception{
Scanner in = new Scanner(new File("obj.txt"));
Scanner in = new Scanner(System.in);
Scanner in = new Scanner("abcedffffff");
while(in.hasNext()){ //hasNext方法,可以实现输出所有内容
String s = in.next();
System.out.println(s);
}
InputStream is = System.in;//new FileInputSream(File)换成等待键盘录入
int ch = is.read();
System.out.println((char)ch);
}//实现一直在控制台输入,知道输入指定字符
InputStream is = System.in;
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String s = br.readLine();
while(s != null){
System.out.println(s);
s = br.readLine();
if(s.equals("886"))
break;
}
打印流:printStream和PrintWriter,这两个方法基本列通,除了write方法外,主要是增加了print,printf 和 println方法,这三个方法是打印流特有的。
构造方法:
PrintStream(File),PrintStream(OutputStream),PrintStream(String name),
PrintWriter(File),PrintWriter(OutputStream),PrintWriter(String name),PrintWriter(Writer)
PrintWriter(OutputStream,boolean autoFlush)和PrintWriter(Writer ,boolean autoFlush)对于这两个构造方法,第二个参数为是否开启自动刷新,如果开启(true)支队println,printf,format中的方法有效,其他方法都需要手动刷新。
内存输出流ByteArrayOutputStream
该对象没有真正实现数据读写操作,但是可以完成写的操作,只不过该方法操作是在内存中完成。
原理:内部创建一个byte数组,这个数据会根据数据的写入而改变大小,该对象不需要关闭,即使关闭了也不影响该对象,该对象可以继续使用。
toString()方法:返回ByteArrayOutputStream内部维护的byte数组(缓冲区)中存储的数据的字符串形式。
byte[] toByteArray():返回byte数组(缓冲区)。
IO异常处理:jdk1.7之后的新特性,这样的语法结构可以省略关流操作。
try(流对象创建语句;){
编写流的操作语句;
}catch(异常名){ //可以有多个
处理异常的语句;
}