一、管道之容量与缓冲区
1. 进程间通信(IPC)
每个进程各自有不同的进程地址空间,任何一个进程的全局变量在另一个进程中都看不见。所有进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区读走数据,内核提供的这种机制就是进程间通信(IPC),管道是最基本的IPC机制。
2. 管道容量
管道容量的大小由:·pipe buf和缓冲条目的数目来共同决定其pipe capacity容量。
pipe buf定义的是内核管道缓冲区的容量,这个值由`内核设定。我们可以通过ulimit -a命令来查看:
[root@localhost ~]# ulimit -a
pipe size (512 bytes, -p) 8
ulimit -a查看到的pipe size一次原子写入为:512 bytes * 8 = 4096 bytes。(一页)
当然另外一个与之对应的就是缓冲条目的个数:它存在于/usr/src/kernels/内核版本/include/linux/pipe_fs_i.h中。当然缓冲条目的个数与linux的内核版本是有关联的,在我的3.10.0-862.el7.x86_64内核上,其缓冲条目个数为:16。
[root@localhost linux]# pwd
/usr/src/kernels/3.10.0-862.el7.x86_64/include/linux
[root@localhost linux]# cat pipe_fs_i.h
#define PIPE_BUFFERS (16)
因此就可以得到管道的容量为:16 * 4096 bytes = 65536 bytes。
真正的管道容量即(pipe capacity)。如果你对上述不大理解,我们也可以使用代码来计算管道容量。
当管道满时:
O_NONBLOCK discable: write调用阻塞,直到有程序读走数据。
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN。
管道是一块内存缓冲区,可写下面程序测试管道的容量pipe capacity:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main()
{
int _pipe[2];
int count = 0;
if(pipe(_pipe) < 0)
{
printf("pipe error\n");
return -1;
}
while(1)
{
write(_pipe[1],"a",sizeof(char));
printf("count = %d\n",++count);
}
return 0;
}
count = 1
count = 2
.
.
.
count = 65534
count = 65535
count = 65536
结果也是不言而喻的,当我们一直对管道进行写操作,最后停止的时候即是管道的容量。65536也因此印证了我之前的第一种方法的正确性。
3. 管道缓冲区
在linux中,管道的实现并没有专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个file结构指向同一个临时的VFS索引节点,而这个索引节点又指向一个物理页面而实现。如下图所示:
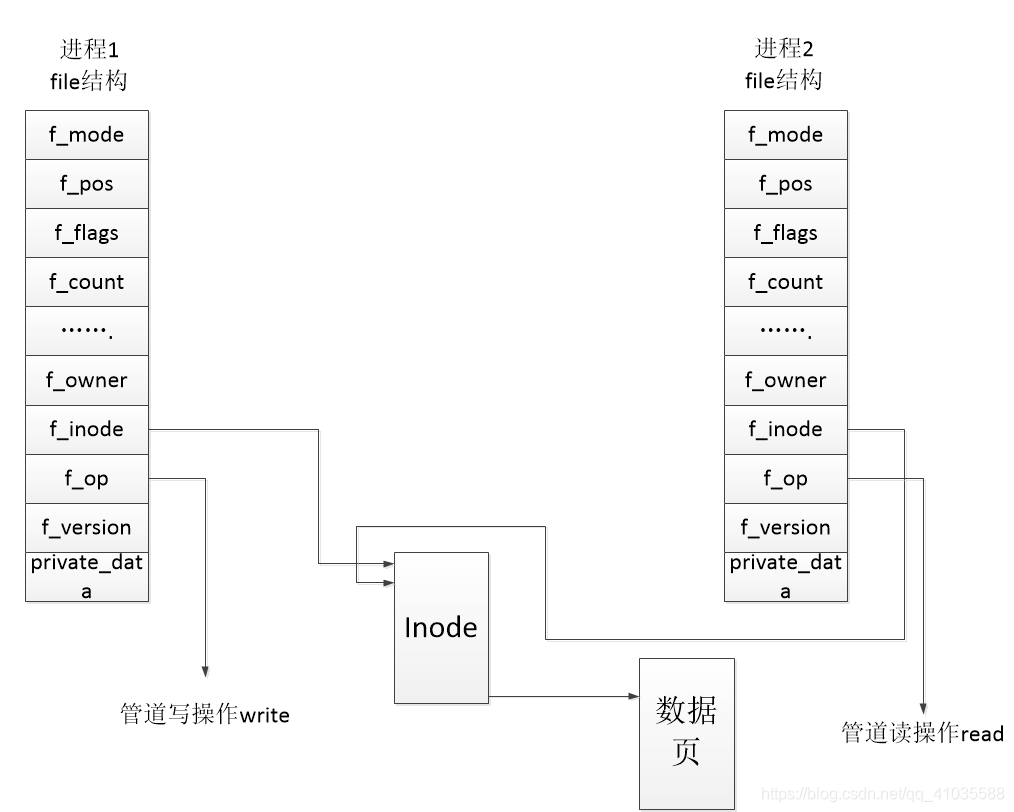
两个file数据结构定义文件操作例程地址是不同的,其中一个是向管道写入数据的例程地址,而另一个是从管道读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。一个普通的管道仅可供具有共同祖先的两个进程之间共享,并且这个祖先已经建立了供他们使用的管道。
注意,在管道中的数据始终以和写数据相同的次序来进行读,这表示lseek()系统调用对管道不起作用。
二、管道之匿名与命名
从物理上分,可以将管道分为同主机的进程之间的通信和不同主机间的进程之间的通信。从通信方式上来分,管道又可以分为匿名管道和命名管道。下面就匿名管道与命名管道的特性作以阐述。
1. 匿名管道(pipe)
[含义]:管道是一个进程的数据流到另一个进程的通道,即一个进程的数据的输出作为另一个进程的数据的输入,管道起到了桥梁的作用。
比如:当我们输入:ls -l | cat test.cc .其中ls和cat是两个进程,|代表管道,意思是执行ls -l进程,并将输出结果作为cat test进程的输入,cat进程将输入的结果打印在屏幕上:
ls -l | cat test.cc

[本质]:匿名管道之所以可以通信的本质在于,父进程fork子进程,父子进程各自拥有一个文件描述符表,但是两者的内容是一样的,既然内容一致,那么指向的就是同一个管道,即父子进程看到了同一份公共资源。
[管道的创建]:管道是一种最基本的IPC机制,由pipe函数创建:
#include<unistd.h>
int pipe(fd[2]);
fd[2]:表示管道的输入与输出端。输出端数据经过管道流到输入端,函数执行完后,会将这个数组赋值:
fd[0]:表示管道输入端的文件描述符。
fd[1]:表示管道输出端的文件描述符。
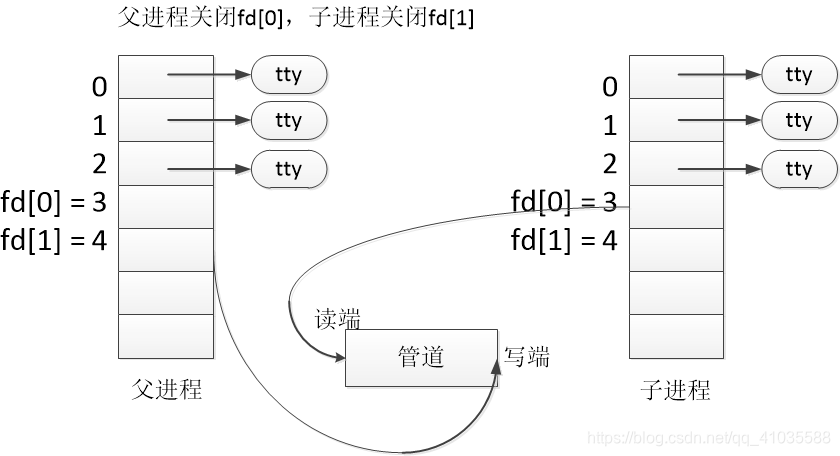
[进程间通信示意图]:我们让父进程关闭管道读端,子进程关闭管道写端。父进程可以给管道里面写,子进程可以从管道里面读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
int fd[2];
int ret = pipe(fd);
if(ret == -1){
printf("creat pipe error!\n");
return 1;
}
pid_t id = fork();
if(id < 0){
printf("fork child error!\n");
return 2;
}
else if(id == 0)//child
{
close(fd[0]);//close read
int i = 0;
char* str = NULL;
while(i < 100)
{
str = "i am child";
write(fd[1],str,strlen(str)+1);
sleep(1);
i++;
}
}
else //father
{
close(fd[1]);//close write
char msg[100];
int j = 0;
while(j < 100)
{
memset(msg,'\0',sizeof(msg));
read(fd[0],msg,sizeof(msg));
printf("%s \n",msg);
++j;
}
}
return 0;
}
[root@localhost Testpipe]# ./mypipe
i am child
i am child
i am child
i am child
i am child
i am child
使用管道是有一些限制的,两个进程通过一个管道只能实现单向通信。比如上述例子,父进程写,子进程读,如果需要子进程写父进程读,就必须另开一个管道。
[匿名管道的5大特性]
- ①匿名管道只能单向通信。
- ②管道只能进行有血缘关系的进程间通信,通常用于父子进程。
- ③管道通信依赖于文件系统,即管道的生命周期随进程。
- ④管道的通信被称为面向字节流,与通信格式没有关系。
- ⑤自带同步机制,保证读写顺序一致。
[思考题]:如果只开一个管道,但是父进程不关闭读端,子进程不关闭写端,双方都保留读写端,为什么不能实现双向通信?
解析:管道的读写端是通过打开的文件描述符来传递的,因此要通信的两个进程必须从他们的公共祖先那里继承管道的文件描述符。
[匿名管道的4种特殊情况]
假设都是阻塞I/O操作,没有设置O_NONBLOCK标志。
-
1)如果所有指向管道
写端的文件描述符都关闭了(管道写端的引用计数为0),而仍然有进程从管道的读端读数据,那么管道中剩余的数据被读取后,再次read会返回0,就像读到文件末尾一样。 -
2)如果有指向管道
写端的文件描述符没关闭(管道写端的引用计数大于0),而持有管道写端的进程也没用向管道中写数据,这时有进程从管道读端读数据,那么管道中剩余的数据被读取后,再次read会阻塞,直到管道中有数据可读了才读取数据并返回。 -
3)如果所有指向管道
读端的文件描述符都关闭了(管道读端的引用计数等于0),这时有进程向管道的写端write,那么该进程会收到信号SIGPIPE,通常会导致进程异常终止。 -
4)如果有指向管道
读端的文件描述符没有关闭(管道读端的引用计数大于0),而持有管道读端的进程也没有从管道中读取数据,这是有进程向管道的写端写入数据,那么在管道被写满时,再次write会阻塞,直到管道中有空位置了才写入数据并返回。
2. 命名管道(FIFO)
[本质]:命名管道在某种程度上可以看做是匿名管道 ,但他打破了匿名管道只能在有血缘关系的进程间的通信。命名管道之所以可以实现进程间通信在于通过同一个路径名而看到同一份资源,这份资源以FIFO的文件形式存在于文件系统中。
值得注意的是,FIFO总是按照先入先出的原则工作,第一个被写入的数据将首先从管道读出。
[管道的创建]:我们可以使用下列函数之一来创建命名管道。
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char* filename,mode_t mode);
int mknod(const char* filename,mode_t mode | S_IFIFO,(dev_t)0);
这两个函数都可以创建一个FIFO文件,注意是创建一个真实存在于文件系统中的文件。
[filename]:指定了文件名。
[mode]:指定了文件的读写权限。
mknod是比较老的函数,而是要mkfifo函数更加简单和规范,所以建议在可能的情况下,尽量使用mkfifo而不是mknod。
[作用]:在文件系统中创建一个文件,该文件用于提供FIFO功能,即命名管道。对文件系统来说,匿名管道是不可见的,它的作用仅限于在父进程与子进程之间的通信。而命名管道是一个可见的文件,因此,它可以用于任何两个进程之间的通信。