一、随机梯度下降算法
之前了解的梯度下降是指批量梯度下降;如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:
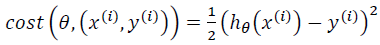
随机梯度下降算法为:首先对训练集随机“洗牌”,然后:
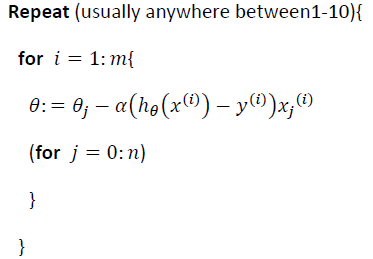
下面是随机梯度下降算法的过程以及和批量梯度下降算法的异同:

随机梯度下降算法是先只对第1个训练样本计算一小步的梯度下降,即这个过程包括调参过程,然后转向第2个训练样本,对第2个训练样本计算一小步的梯度下降,这个过程也包括调参,接着转向第3个训练样本.......
批量梯度下降和随机梯度下降算法的收敛过程是不同的,实际上,随机梯度下降是在某个靠近全局最小值的区域内徘徊,而不是真的逼近全局最小值并停留在那个点,不过其最终也会得到一个很接近全局最小值的参数。这对于绝大多数的实际应用的目的来说,已经足够了。
随机梯度下降算法收敛比较快。
二、小批量梯度下降算法
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的一个算法。
- 批量梯度下降算法:每次迭代中使用所有(m个)样本
- 随机梯度下降算法:每次迭代中使用1个样本
- 小批量梯度下降算法:每次迭代中使用b个样本(b在2~100之间)
假设b取10,则小批量梯度下降算法如下:
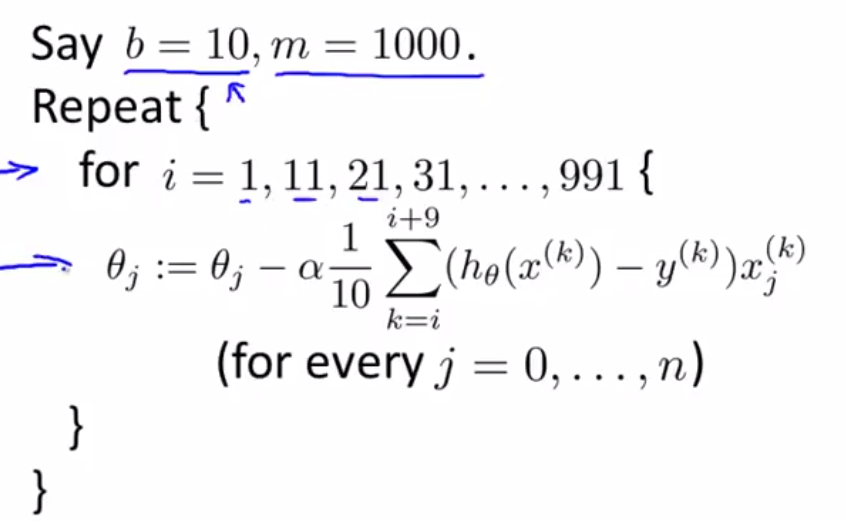
使用小批量梯度下降算法,在处理了前10个样本之后,就可以开始优化参数θ,因此不需要扫描整个训练集,因此小批量梯度下降算法比批量梯度下降算法快。
小批量梯度下降算法在有好的向量化实现时,比随机梯度下降算法好,在这种情况下,10个样本求和可以使用一种更向量化的方法实现,允许部分并行计算10个样本的和。