微服务的部署需要三步走
第一步:服务的docker容器化,把服务(应用或者是对应功能模块)在docker容器内运行。
第二步:创建docker镜像仓库,把docker容器化的镜像推送到仓库中。
第三步:搭建高可用的集群环境(kubernetes容器编排工具),并可以对已经容器化的服务进行启动、停止、扩容等操作
第一步:服务的docker容器化
一、服务为什么要docker容器化
1、把所有服务docker容器化,意思是让所有服务能够在指定容器中运行。
2、把服务docker容器化,可以让服务有一个适合、隔离、相对安全的运行环境,这个运行环境可以理解为是基础镜像。
3、服务运行在指定docker容器下,各个服务(功能模块)之间可以相互隔离,互不影响,又相互交融协同工作。如果一个服务运行出现了问题,并不会影响其它服务的使用。
二、基于Java语言环境的微服务的Docker容器化部署
1、从镜像仓库(官方、国内各镜像站、公司私有镜像库)拉取Java环境所需的镜像,这里以docker pull openjdk:7-jre 为例,作为Java运行的环境以及基础镜像
2、把服务部署到这个Java基础镜像中去。
这里需要注意的是:不能把一些基础配置(比如:数据源的配置等等)的相关参数写死,因为写死会导致每次服务地址的变更都要重新再去构建镜像,这样子很繁琐也很麻烦。所以为了减少这种构建镜像的过程繁琐,一些配置参数一般不要写死,比如数据库的访问地址经常会变,因此就不要把地址写死,可以把数据库地址的localhost写成变量的形式:“${mysql.address}”。
3、当我们的服务运行在docker容器之后,服务的IP是随时变化的,所以配置的地址不要写死在配置文件里。
这里需要思考的问题是:服务该以什么样的形式去运行于docker容器中或者服务器中
4、把服务打包成jar包,利用dockerfile自定义镜像构建服务的镜像
示例:vim Dockerfile 进入vim文本编辑器中
FROM openjdk:7-jre
MAINTAINER [email protected]
COPY target/user-thrift-service-1.0-SNAPSHOT.jar /user-service.jar
ENTRYPOINT ["java","-jar","/user-service.jar"]
.........................................
...................................省略
5、进入到dockerfile存放的文件夹路径,利用docker build -t user-service:latest .构建该服务的镜像,该镜像名为user-service
注意:为了简化构建过程,可以自定义一个名为build.sh的脚本文件,
每次运行该脚本的时候都把maven工程package(打包)一遍,
再执行docker build -t user-service:latest。
脚本示例:#!/use/bin/env bash
mvn package
docker build -t user-service:latest
6、再把该user-service服务的镜像启动起来,docker run -it user-service:latest - -mysql.address=本主机的IP地址
这里需要注意的是:地址不能写成127.0.0.1和localhost,因为服务运行在容器中,写成上面提到的地址根本访问不到。所以要写成本主机的IP地址
三、服务容器化运行之后,如何建立各服务容器化运行之间的通信
有三种通信方式:
1、直接通信:通过服务所在容器的IP:端口号进行通信。这种方式使用的很少,因为docker容器的IP不稳定,当容器重新启动或者发生变化的时候,容器的IP也随之发生变化
2、服务把端口映射出去,就是把容器的端口转换成主机的端口,然后依赖它的容器去访问主机的IP:端口即可。
3、使用docker的link机制,link到一个容器之后,直接通过名字去访问
这里需要思考的问题是:以上三种通信方式采用哪一种比较合适?除了容器间通信,还有Redis、数据库等中间件的通信问题
- 开发的那些微服务使用第三种方式,link的方式根据名字去访问对应服务
- 而这里我们依赖的基础环境、数据库、redis等我们要使用第二种方式来实现。通过容器端口的映射来访问主机的IP:端口
四、运行于独立容器中的各个微服务之间如何建立依赖关系,也就是link关系
1、可以使用docker compose,也可以写命令来link每一个服务。使用docker compose是比较好的方式,建立各服务之间的通信依赖就更清晰明了。
2、新建一个docker-compose.yml的配置文件来建立服务间的依赖,并构建服务间的通信交互,如图

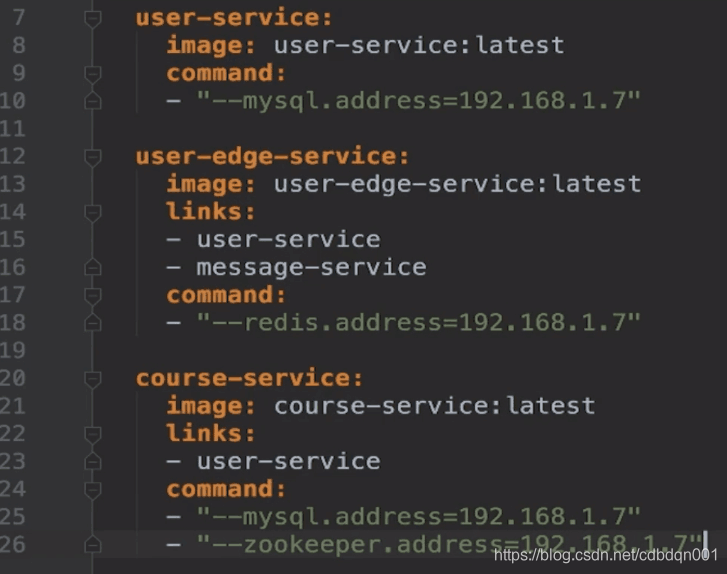
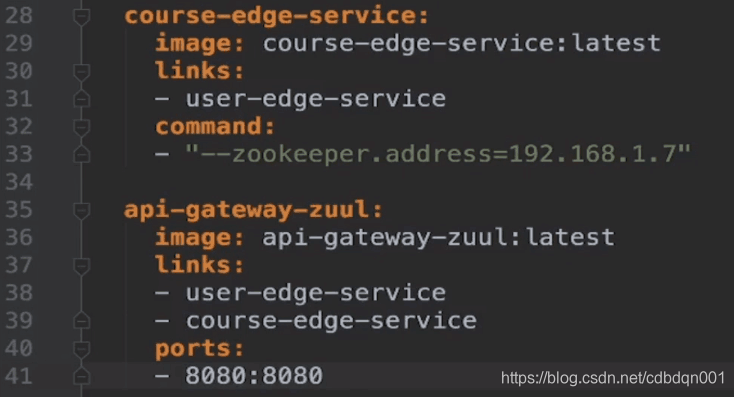
3、配置文件写完之后,启动对应的服务。比如mysql、redis等中间件,再通过docker-compose up -d 后台启动已经建立通信的运行于容器中的各项服务
第二步:构建私有镜像仓库
构建镜像仓库,最常用的git harbor来存放镜像
1、git harbor官网去下载相应版本的harbor,如图所示:
2、把下载到本地的git harbor拷贝到指定目录下,如图:

3、拷贝到指定目录之后,解压缩文件,如图:

4、解压之后,进入到harbor的文件夹,其中有一个harbor.cfg的配置文件,需要vim harbor.cfg进入文本编辑器中进行修改,:8080这里我们先修改hostname=hub.kc.com(这里的域名是自定义),其它的配置修改根据实际情况依需进行修改
5、修改完成harbor.cfg配置文件之后,如果是非mac系统,就可以运行命令:./install.sh文件去完成包括镜像的构建、配置的生效以及harbor所有的docker服务启动起来。
注意:如果是mac系统,由于harbor使用了许多的目录挂载,而mac系统有很多目录是不可以挂载的,因此我们需要vim docker-compose.yml进入到配置文件中修改所有的挂载(找到对应的volumes)
6、./install.sh命令执行成功后会出现之前配置好的hostname镜像仓库域名:hub.kc.com:8080用以在浏览器中访问构建好的harbor私有镜像仓库
7、push推送本地镜像到创建的私有harbor镜像仓库,如图:

8、推送完基础镜像之后,再push推送微服务到harbor私有镜像仓库
第三步:搭建高可用的kubernetes集群环境
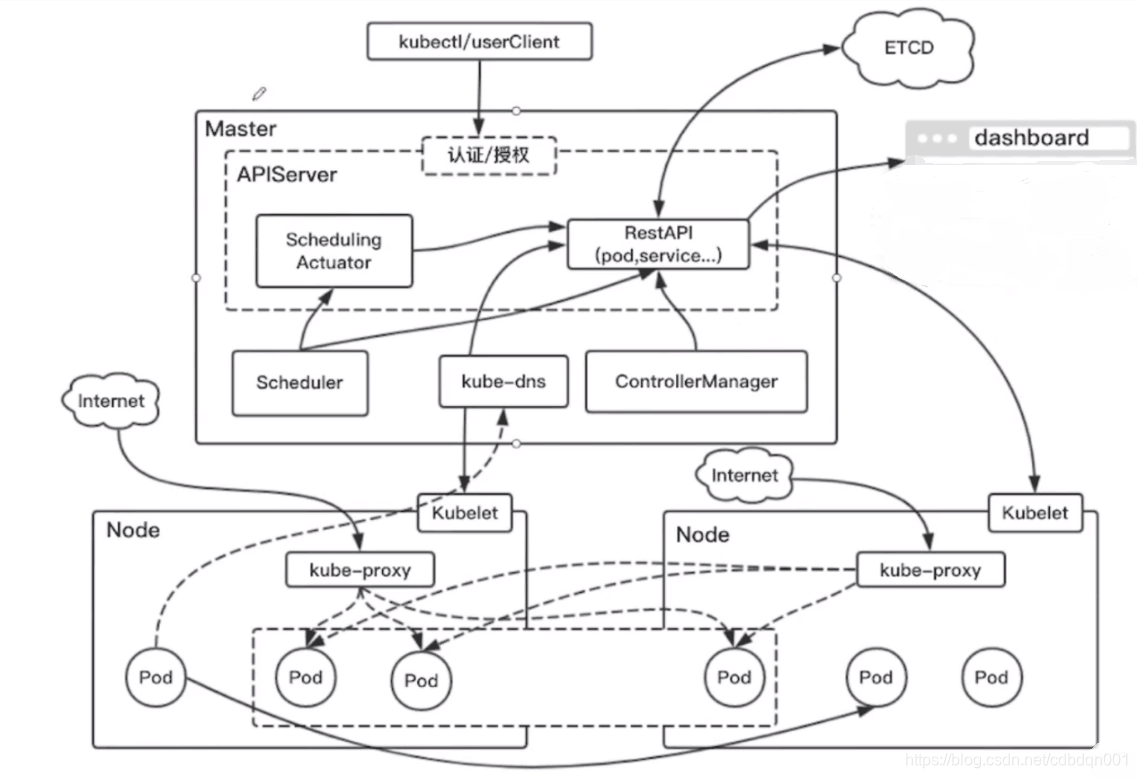
1、上图由一个masters主节点、两个node从节点组成
2、masters主节点里面部署的都是kubernetes集群的核心组件,其中虚线代表的APIservice,它提供了资源操作的唯一的入口,并且提供认证、授权以及kubernetes集群的访问控制。我们可以通过kubectl(相当于用户访问集群客户端)通过http的请求,通过restAPI的形式去访问APIserver,从而实现对整个集群的控制。controllerManager负责维护整个集群的运行状态,比如说故障检测、扩缩容、滚动更新等等;Scheduler是负责整个集群的资源调度,按照预定的调度策略把pod调度到相应的node节点上;etcd主要是用作一次性存储,保存了pod、service以及集群的一些状态等等的一些信息,简单的说集群中的数据需要持久化存储的数据都保存在etcd中;kube-dns负责整个集群的DNS服务(不一定必须得有),如果不需要名字去访问的话,可以不安装这个组件,一般都会选择安装;dashboard负责集群相关数据的展示和操作,提供一个数据可视化的界面
3、每一个node节点都有一个kubelet,它负责维护当前这个node节点上容器的生命周期,也负责维护当前node节点的网络等等的管理;在每个node上都运行了kube-proxy,它负责service提供内部的服务发现和负载均衡,相当于为service服务这个概念提供了一个落地的方法
4、部署的过程是:用户执行kubectl→向APIserver发起一个请求,请求通过认证之后→Scheduler进行资源的调度得到一个目标node节点,反馈给APIserver→然后APIserver就会请求对应的node,比如请求到一个node的kubelet→通过kubelet把这个node节点的pod运行起来→然后APIserver还会将对应node节点的pod信息存储到etcd中持久化保存起来→pod运行起来之后,controllerManager就会管理当前运行中pod的状态,如果当前运行的pod挂掉了,那么controllerManager会重新创建一个一样的pod,而pod的扩容等都是由controllerManager来管理的;此时运行中的pod会有一个IP地址,我们就可以在整个集群内使用这个IP地址来访问当前节点正在运行中的pod了,pod的IP是会变化的,比如异常重启的时候、服务升级的时候pod的IP都会改变;还有就是有多个实例的时候我们也不可能把pod的每个IP都实时的关注去访问,这就有了service(下面node节点用长方形虚线圈起的部分),service里面有三个pod,不在虚线内的pod是单独存在的并没有提供service服务的入口;完成service服务工作的具体模块就是kube-proxy,在每个node节点上都会有kube-proxy,在任何一个节点上访问service的虚拟IP(kube-proxy会给service分配一个IP)都可以访问到service里面的任何一个pod;所以说这两个node节点对应的一个service都会有一个IP的指向,负载均衡的访问pod
5、service的IP是可以在集群中访问到的,但是在集群之外如何访问集群内的一个服务如何操作呢?可以把当前服务的端口暴露在当前的node节点上,然后集群外的请求通过暴露的端口就可以访问到这个service了
6、集群中可以通过名字实现pod之间的互相访问,这个问题的处理是kube-dns要解决的事情,kube-dns提供了整个集群的DNS服务,让每个pod都可以通过名字来访问对方,意思就是集群中的一个pod可以通过名字访问到另外的pod
kubernetes的网络
1、CNI(container network interface)就是容器网络接口,用于实现容器间网络通讯。Flannel、Calico、Weave网络插件就可以实现CNI容器间通讯,用户可以选择适合自己方案
2、不管选择哪种网络插件方案,docker网络本身只能访问当前node节点上的容器,而没有办法跨主机去访问其它node节点上的容器,kubernetes集群会保障整个集群内的每个pod都可以互联互通
kubernetes pod的通讯
pod之间的通讯方式
1、pod的内部通讯:就是同一个pod中的容器之间进行通讯。同一个pod运行在主机上(Linux虚拟机),容器共享网络空间,因此一个pod内的多个容器可以通过localhost:端口号互相访问。
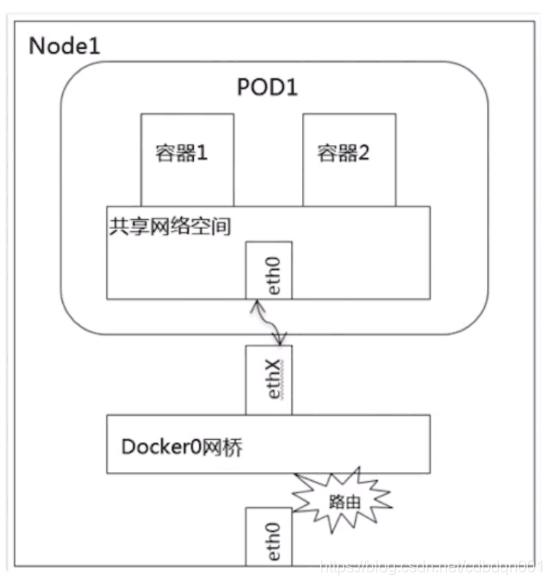
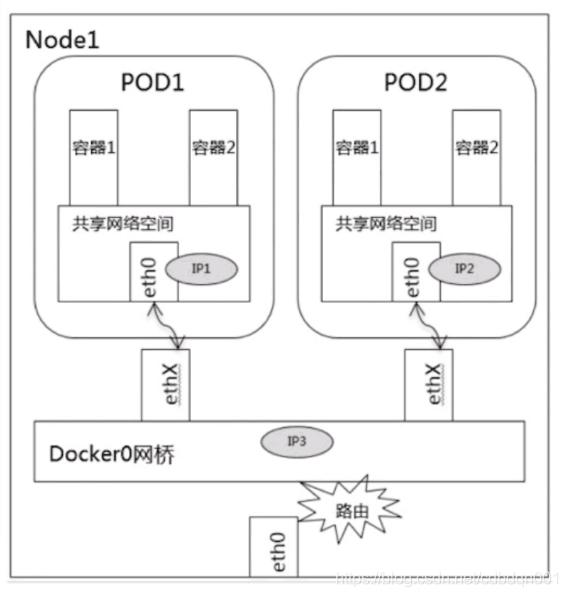
2、同一个node节点中不同pod之间的通讯:同一个node节点中pod的它的默认的路由都是docker0,由于它们都关联在同一个网桥docker0上,地址网段都是相同的,因此pod之间可以通过网桥进行通讯。可以通过pod的IP地址进行访问
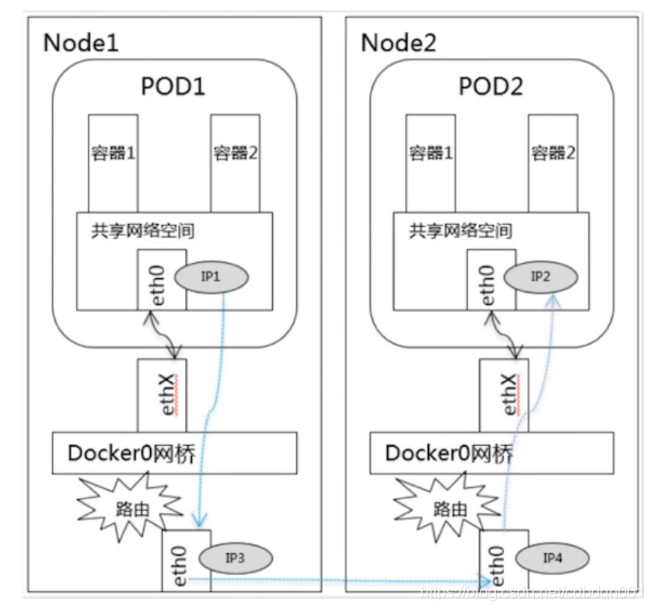
3、不同node节点以及不同pod间的通讯:这种通讯方式必须满足以下条件,首先pod的IP不能冲突,不能有相同的IP;其次node节点的IP要与pod的IP关联起来,通过这个关联可以让不同节点内的pod相互访问
kubernetes的服务发现
服务发现主要有两个组件:一个是kube-proxy,另一个是kube-dns。而kube-prox分为两种类型:一个kube-proxy(ClusterIP-集群IP),它会给相应的pod分配一个虚拟的IP,会把虚拟IP的流量重定向到后端服务的一个集合,这个虚拟的IP只能在集群内部访问,并且是固定的。只要service不删除,这个虚拟的IP是不变的。另一个是kube-proxy(NodePort):就是在每一个node上都启动一个监听端口,相当于是把服务暴露在node节点上,这样可以让集群外部的服务通过node节点的IP:端口号访问到集群内的服务;还有一种是kube-DNS:它是kubernetes的一个插件,负责集群内部的DNS域名解析,其目的是为了让集群内部的pod可以通过名字相互访问
以上就是微服务部署的三步走,通过纯理论的分析,我们基本了解了微服务的部署过程,方便我们加深对微服务的理解和认识。