- 类 TAG 的分析,推荐 TAG = “XXXActivity”字符串的形式,避免使用 TAG = XXXActivity.class.getSimpleName()的形式,有如下几个优点:
- 代码简洁,在后期项目大了之后,对于代码减包很可观(字节码层面比较)
- 内存方面,static final TAG = “XXXActivity”会直接进入常量池,不会占用堆内存。
- 效率方面,TAG = XXXActivity.class.getSimleName()源码上经过中间的一些逻辑处理之后,最终调用的是类的getName(),类似于toString(),然后通过subString()截取类名那一部分,比如,BaseActivity.class.getSimpleName() == "com.xx.BaseActivity$Companion@4e5a001",然后把“BaseActivity”截取出来。虽然两者最后显示的结果是一样的,但是很明显,XXXActivity.class.getSimleName()莫名增加了很多不必要的字符串操作。(可查看getSimleName()源码)
下面看一个简单的测试, 下图2是TAG = “XXXActivity”的字节码,下图3是TAG = XXXActivity.class.getSimpleName()的字节码,很明显后者多了一些指令,从而导致APK包大小增大。

(图1)

(图2)
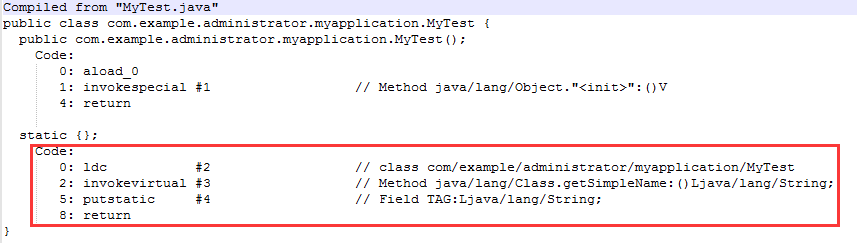
(图3)
综上,在内存使用,运行效率,代码减包等方面前者均优于后者。
- 类成员变量去除冗余初始化赋值,怎么理解呢?就是说,在你确认这个类成员变量是一个默认零值的时候,那么不要手动给他赋值。比如,你定义了一个字符串类型 private String text; 但是不推荐你写成 private String text = null; 为何?因为JVM会在类加载阶段给默认零值的成员变量赋一个系统零值,而手动赋默认值会增加APK包大小和降低类加载与对象创建的效率,除此之外,没有任何好处。简单从字节码层面看一个例子。(下图2为非手动赋值的字节码指令,图3为手动赋值的字节码指令)

(图1)
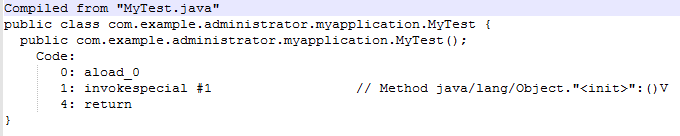
(图2)
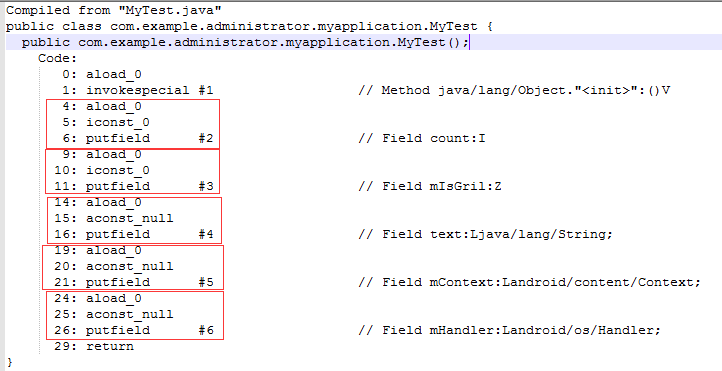
(图3)
可以看出,每一个多余的赋值,都会增加3条字节码指令(加载->读取->赋值),这难道不是增加了APK包大小和降低类加载的效率吗?所以,对于默认零值的类成员变量最好不要手动给它赋零值,但是final 修饰的变量除外,因为fianl 修饰的变量必须在声明的时候赋值。
- 我们知道,APK包大小里面图片资源占大头,所以这里强烈建议大家提交图片资源到项目之前,务必要经过压缩后再提交,如果是png图片,个人推荐用 https://tinypng.com/ 这个网站进行图片无损压缩,我随便找了我们项目的几个图片,大家随意感受下(因为是无损压缩,其实还可以压了再压)

- dp 和 sp 傻傻分不清。在TextView中,很多人习惯用dp来设置textSize,虽然一般情况下,从显示结果来看好像也挺正常的,但是,当用户在手机设置中把字体调大调小的时候,那么dp修饰的textSize看起来就不一样了。也就是说在TextView中设置sp单位时字体大小会跟随着用户配置系统字体而变化,dp则不会。想象一下,家里的老年人在用手机的时候总是喜欢设置大号字体,那么如果你在项目中用的是dp,你这个字体看起来还是小的,这样就会带来差的用户体验,所以字体单位是sp,sp,sp。昨天我在编译项目的时候也看到了我们的lint检查,这样的问题还是很多的。

- HashMap 中 keySet()和entrySet()两者遍历方式的比较,简单来说,keySet()拿到的是key的集合,然后再通过key去value的集合中查找,相当于遍历了两遍,而entrySet()返回的是key-value的键值对,一次遍历就能获取到value。所以如果不关心key,只想得到value的话,推荐使用entrySet()。(entrySet() 的效率是 keySet()的一倍以上)
- 多个字符串的拼接不要再用 + 啦,+ 连接符占用大量的内存和带来极差的效率,推荐使用StringBuilder或StringBuffer。(特别是在打log语句中很多同学习惯 + 拼接)
- 小技巧,字符串判空推荐直接用api TextUtils.isEmpty(str) 而不是 "str == null” 或 “str == null || " ".equals(str) " ,TextUtils 里面还有很多对字符串操作比较方便的api。
- 枚举类替换。枚举Enum在java中是一个完整的类, 而枚举中的每一个值在枚举类中都是一个对象,所以使用枚举的值将比静态常量消耗更多的内存,因此我们没有必要为了使用几个常量就去使用枚举,而且在Android开发上,枚举也是不推荐使用的,这里我们可以使用“注解+静态常量“ 的方式代替作用类似于常量的枚举。(这里的注解和枚举一样可以保证类型安全)

(枚举)
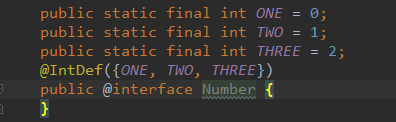
(注解+静态常量)
- 简化版 findViewById。利用泛型和简短符号来简化findViewById方法,减少冗余代码和类型转换。你也可能会问,项目里已经有ButterKnife代替findViewById了,为什么还要用这个呢?ButterKnife作为依赖注入框架其实是有副作用的:1.@BindView注解的原理是在项目的编译期通过搜索每个文件中的注解标注,从而在相应的位置注入代码,当项目中大量使用注解之后,会明显增加编译时间。2.每一个使用了注解的类都会生成XXX$$ViewBinder的中间类,增加了包大小。3.需要被注解的变量或方法不能是private或static修饰的,这样就一定程度上破坏了代码的封装性。注解的使用主要是用来提升开发效率,减少书写冗余代码,在这里$()也可以做到,而且没有副作用,还能提高逼格。当然,这里只是建议,ButterKnife还是非常强大的。(另外,最新的api当中,findViewById其实也是使用了泛型,无需做类型强转,也还算方便)

(简化版findviewbyid)
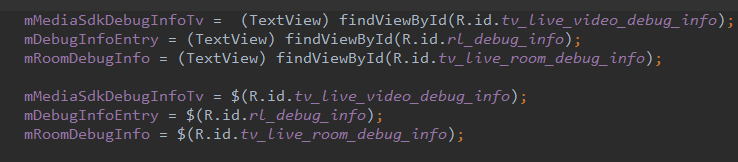
(与传统findviewbyid使用上的区别)
- IO操作性能比较。效率上FileChannel > BufferedXXXStream > FileXXXStream,所以能用FileChannel 就用FileChannel ,比如在文件拷贝上面FileChanner就有着明显的效率差距。再者,能使用BufferedXXXStream 就使用BufferedXXXStream ,BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file)); buffer最优大小应该是8K。另外,OKHttp的OKio也具有很好的性能,推荐使用,总之,尽量避免只使用最原始的FileXXXStream,效率较低。