6.10 codecs:字符串编码和解码
codecs模块提供了流接口和文件接口来完成文本数据不同表示之间的转换。通常用于处理Unicode文本,不过也提供了其他编码来满足其他用途。
6.10.1 Unicode入门
CPython 3.x区分了文本(text)和字节(byte)串。bytes实例使用一个8位字节值序列。与之不同,str串在内部作为一个Unicode码点(code point)序列来管理。码点值使用2字节或4字节表示,这取决于编译Python时指定的选项。
输出str值时,会使用某种标志机制编码,以后可以将这个字节序列重构为同样的文本串。编码值的字节不一定与码点值完全相同,编码只是定义了两个值集之间转换的一种方式。读取Unicode数据时还需要知道编码,这样才能把接收到的字节转换为unicode类使用的内部表示。
西方语言最常用的编码是UTF-8和UTF-16,这两种编码分别使用单字节和两字节值序列表示各个码点。对于其他语言,由于大多数字符都由超过两字节的码点表示,所以使用其他编码来存储可能更为高效。
编码
要了解编码,最好的方法就是采用不同方式对相同的串进行编码,并查看所生成的不同的字节序列。下面的例子使用以下函数格式化字节串,使之更易读。
# codecs_to_hex.py
import binascii
def to_hex(t,nbytes):
"""Format text t as a sequence of nbytes long values
separated by spaces.
"""
chars_per_item = nbytes * 2
hex_version = binascii.hexlify(t)
return b' '.join(hex_version[start:start + chars_per_item]
for start in range(0,len(hex_version),chars_per_item)
)
if __name__ == '__main__':
print(to_hex(b'abcdef',1))
print(to_hex(b'abcdef',2))
这个函数使用binascii得到输入字节串的十六进制表示,在返回这个值之前每隔nbytes字节就插入一个空格。
运行结果:
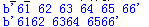
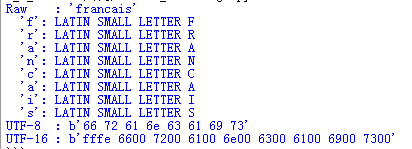
第一个编码示例首先使用unicode类的原始表示来打印文本‘francais’,后面是Unicode数据库中各个字符的名。接下来两行将这个字符串分别编码为UTF-8和UTF-16,并显示编码得到的十六进制值。
import unicodedata
from codecs_to_hex import to_hex
text = 'francais'
print('Raw : {!r}'.format(text))
for c in text:
print(' {!r}: {}'.format(c,unicodedata.name(c,c)))
print('UTF-8 : {!r}'.format(to_hex(text.encode('utf-8'),1)))
print('UTF-16 : {!r}'.format(to_hex(text.encode('utf-16'),2)))
对一个str编码的结果是一个bytes对象。
运行结果:
给定一个编码字节序列(作为一个bytes实例),decode()方法将其转换为码点,并作为一个str实例返回这个序列。
from codecs_to_hex import to_hex
text = 'francais'
encoded = text.encode('utf-8')
decoded = encoded.decode('utf-8')
print('Oruginal :',repr(text))
print('Encoded :',to_hex(encoded,1),type(encoded))
print('Decoded :',repr(decoded),type(decoded))
选择使用哪一种编码不会改变输出类型。
运行结果:
