背景
云服务市场是一块大蛋糕,从如今的各大巨头都纷纷出手想分得一杯羹就能看出。而国内巨头阿里爸爸早在2009年就看准了时机,这里当然少不了要提到阿里云创始人:王坚。破釜沉舟的方式用命换来的成就,阿里每年投入10亿,一投就是10年。不得不服王坚和马云当初的坚持和眼光。
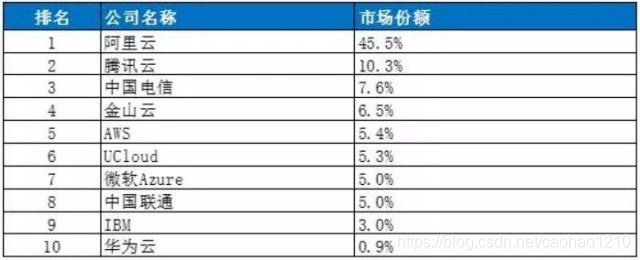
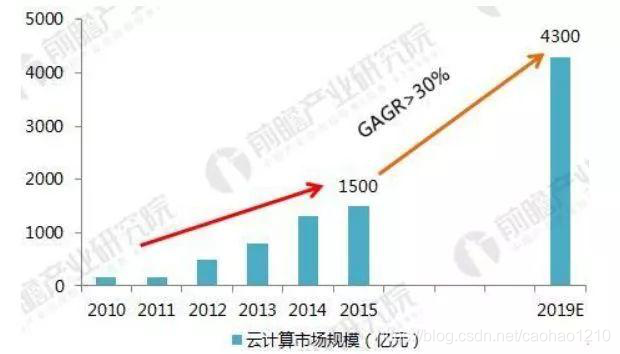
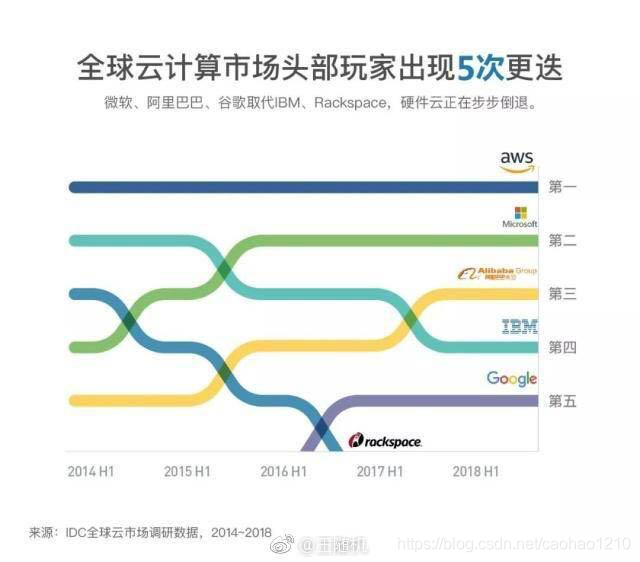
从上面几张图就能看出来,这利润真的是杠杠的。当然也不得不说云计算改变了如今互联网行业服务的环境和运维模式,从传统的主机、服务器到现今的云环境。
事故
云计算这几年可以说是事故不断,各大厂商为了市场吹嘘自己的产品,有多么多么的安全,但从数据我们可以看到云事故发生的时候,恢复和赔偿对客户还是非常不友好的,毕竟是人家制定的规则,怎么玩他说了算。
可以看出选择云服务器,对客户而言,最担心的还是数据、业务的数据安全问题和环境的稳定性问题。
阿里云宕机(IO HANG)
国内云计算龙头,市场占比45%,可能这个数字不够直观。那就说个更恐怖的,国内近40%的网站是部署在阿里云上的。也就是说,加入阿里云全部宕机了就直接导致40%的网站无法访问。不过整体恢复算是响应非常快速的,而且未有数据丢失问题,只是造成故障时段部分网站不可用,影响业务。所以可以说这次事故影响范围非常大,但后果不是很验证。
云环境都尽可能的保证自己的稳定,但如何做好高可用和容灾是云厂商最后的博弈。这里我突然想到了netflix的Chaos Monkey,做出捣蛋者,反向提升自身的高可用和稳定。这不得不说是一种很好的方式,在2018年杭州·云栖大会上阿里云提出类似的概念“混沌工程”,用于打磨云环境的稳定,不过我猜可能工程还不够成熟或者还没到落地生产阶段,否则也不会出现这种大面积事故了。混沌工程