【EDA】实验4:常用元件的 Verilog RTL 代码设计
2018年11月11日 00:17:09 lilei4136619 阅读数:123
【EDA】实验4:常用元件的 Verilog RTL 代码设计
多路选择器
一.实验内容
1.做一个4选1的多路选择器,并进行波形仿真。
2.将4选1多路选择器同2选1多路选择器对比,观察资源消耗的变化。
二.实验步骤
1.创建项目
创建项目的过程与前几篇文章相同,不再赘述。
2.添加Verilog HDL文件
3.编写Verilog HDL代码
具体代码如下:
// module top, 选择器(mux)的代码,
module top(
IN0 , // input 1
IN1 , // input 2
IN2 , // input 3
IN3 , // input 4
SEL , // select
OUT ); // out data
input [15:0] IN0, IN1, IN2, IN3;// 选择器的输入数据信号
input [1:0] SEL; // 通道选通的控制信号
output[15:0] OUT; // 选择器的输入数据信号
reg [15:0] OUT;
// 生成组合逻辑的代码
always @ (IN0 or IN1 or IN2 or IN3 or SEL) begin
if(SEL==0) // SEL为0 选择输入0
OUT = IN0;
else if(SEL==1) // SEL为1 选择输入1
OUT = IN1;
else if(SEL==2) // SEL为2 选择输入2
OUT = IN2;
else if(SEL==3) // SEL为3 选择输入3
OUT = IN3;
end
endmodule
// endmodule top
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.编译代码
5.添加并配置Vector Waveform File
添加Vector Waveform文件并配置仿真输入波形的方法在之前的文章已说明过了,此处直接展示仿真的结果。
从仿真波形中可以看到:当SEL端的信号变化时,输出端会选择相应的输入信号进行输出。
6.4选1多路选择器的RTL结构
对于Quartus工具,可以按照如下路径找到RTL Viewer:Tools -> Netlist Viewer -> RTL Viewer
本实验代码生成的RTL结构如下图:
第一页:
第二页:
7.2选1多路选择器的RTL结构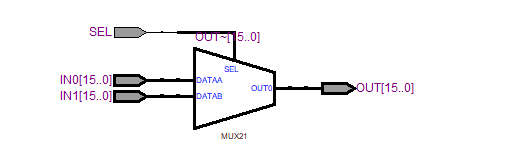
8.两种多路选择器的资源消耗对比
2选1多路选择器:
4选1多路选择器:
可见4选1多路选择器相比2选1多路选择器消耗更大的硬件资源。
交叉开关
一.实验内容
1.编写一个4X4路交叉开关的Verilog代码,然后编译,进行波形仿真。
2.观察RTL View,比较2x2路交叉开关与4x4路交叉开关之间消耗资源的区别。
二.实验步骤
1.编写Verilog HDL代码
// module top, a 4x4 crossbar switch circuit
module top(
IN0 , // input 1
IN1 , // input 2
IN2 , // input 3
IN3 , // input 4
SEL0 , // select the output0 source
SEL1 , // select the output1 source
SEL2 , // select the output2 source
SEL3 , // select the output3 source
OUT0 , // output data 0
OUT1 , // output data 1
OUT2 , // output data 2
OUT3 ); // output data 3
input [15:0] IN0, IN1, IN2, IN3;
input [1:0] SEL0, SEL1, SEL2, SEL3;
output[15:0] OUT0, OUT1, OUT2, OUT3;
reg [15:0] OUT0, OUT1, OUT2, OUT3;
// get the OUT0
always @ (IN0 or IN1 or IN2 or IN3 or SEL0) begin
if(SEL0==0)
OUT0 = IN0;
else if(SEL0==1)
OUT0 = IN1;
else if(SEL0==2)
OUT0 = IN2;
else if(SEL0==3)
OUT0 = IN3;
end
// get the OUT1
always @ (IN0 or IN1 or IN2 or IN3 or SEL1) begin
if(SEL1==0)
OUT1 = IN0;
else if(SEL1==1)
OUT1 = IN1;
else if(SEL1==2)
OUT1 = IN2;
else if(SEL1==3)
OUT1 = IN3;
end
// get the OUT2
always @ (IN0 or IN1 or IN2 or IN3 or SEL2) begin
if(SEL2==0)
OUT2 = IN0;
else if(SEL2==1)
OUT2 = IN1;
else if(SEL2==2)
OUT2 = IN2;
else if(SEL2==3)
OUT2 = IN3;
end
// get the OUT3
always @ (IN0 or IN1 or IN2 or IN3 or SEL3) begin
if(SEL3==0)
OUT3 = IN0;
else if(SEL3==1)
OUT3 = IN1;
else if(SEL3==2)
OUT3 = IN2;
else if(SEL3==3)
OUT3 = IN3;
end
endmodule
// endmodule top
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
2.波形仿真
3.查看4×4交叉开关的RTL结构
第一页:
第二页:
第三页:
第四页:
第五页:
第六页:
4.查看2×2交叉开关的RTL结构*
5.两种交叉开关的资源消耗对比
2×2交叉开关的资源消耗:
4×4交叉开关的资源消耗:
可见,4×4交叉开关的逻辑单元消耗是2×2交叉开关的4倍。
优先编码器
一.实验内容
1.编写一个8输入的优先编码器,然后编译,查看RTL View。
二.实验步骤
1.编写Verilog HDL代码
// module top, 8 input priority encoder with zero input check
module top(
IN , // input
OUT ); // output
input [7:0] IN;
output[3:0] OUT;
reg [3:0] OUT;
// get the OUT
always @ (IN) begin
if(IN[7]) // 第一优先级
OUT = 4'b111;
else if(IN[6]) // 第二优先级
OUT = 4'b110;
else if(IN[5]) // 第三优先级
OUT = 4'b101;
else if(IN[4]) // 第四优先级
OUT = 4'b100;
else if(IN[3]) // 第五优先级
OUT = 4'b011;
else if(IN[2]) // 第六优先级
OUT = 4'b010;
else if(IN[1]) // 第七优先级
OUT = 4'b001;
else if(IN[0]) // 第八优先级
OUT = 4'b000;
else // 什么都没有检测到
OUT = 4'b1111; // 输出值可自定义,不和上面的输出值混淆即可
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.波形仿真
3.查看RTL View
多路译码器
一.实验内容
1.编写一个4-16的译码器,编译,仿真。
2.查看RTL View,并和3-8译码器对比资源开销。
二.实验步骤
1.编写Verilog HDL代码
// module top, 4-16 decoder
module top(
IN , // input
OUT ); // output
input [3:0] IN;
output[15:0] OUT;
reg [15:0] OUT;
// get the OUT
always @ (IN) begin
case(IN)
4'b0000: OUT = 16'b0000_0000_0000_0001;
4'b0001: OUT = 16'b0000_0000_0000_0010;
4'b0010: OUT = 16'b0000_0000_0000_0100;
4'b0011: OUT = 16'b0000_0000_0000_1000;
4'b0100: OUT = 16'b0000_0000_0001_0000;
4'b0101: OUT = 16'b0000_0000_0010_0000;
4'b0110: OUT = 16'b0000_0000_0100_0000;
4'b0111: OUT = 16'b0000_0000_1000_0000;
4'b1000: OUT = 16'b0000_0001_0000_0000;
4'b1001: OUT = 16'b0000_0010_0000_0000;
4'b1010: OUT = 16'b0000_0100_0000_0000;
4'b1011: OUT = 16'b0000_1000_0000_0000;
4'b1100: OUT = 16'b0001_0000_0000_0000;
4'b1101: OUT = 16'b0010_0000_0000_0000;
4'b1110: OUT = 16'b0100_0000_0000_0000;
4'b1111: OUT = 16'b1000_0000_0000_0000;
// full case 不需要写default,否则一定要有default
endcase
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2.波形仿真
3.查看RTL View
4-16译码器: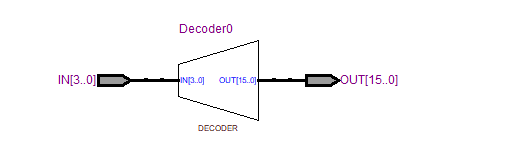
3-8译码器: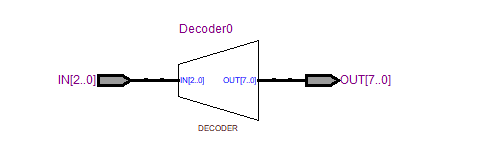
4.对比资源开销
3-8译码器:
4-16译码器:
4-16译码器的资源消耗约为3-8译码器的2倍。
加法器
无符号加法器
一.实验内容
1.把加法器的输入信号和输出信号都改成4比特位宽,编译,波形仿真。观察输出结果,说出输出和输入的对应关系。
2.把加法器的输入信号改成8比特位宽,编译,波形仿真。观察加法器的输出延迟,和4比特输入位宽的情况对比。
二.实验步骤
1.编写Verilog HDL代码
module top(
IN1 ,
IN2 ,
OUT );
input[3:0] IN1, IN2;
output[3:0] OUT;
reg[3:0] OUT;
always@(IN1 or IN2) begin // 生成组合逻辑的always 块
OUT = IN1 + IN2;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.仿真波形
由上图可知,当加法器的输入信号和输出信号位宽相同时加法器得到的结果可能会丢失最高位的进位,即所得结果溢出,导致计算结果出错。当最高位无进位时输出等于两个输入的和,而当最高位有进位时则输出比两个输入的和小16(24)。
3.输入信号为8位宽的加法器的Verilog HDL代码
module top(
IN1 ,
IN2 ,
OUT );
input[7:0] IN1, IN2;
output[8:0] OUT;
reg[8:0] OUT;
always@(IN1 or IN2) begin // 生成组合逻辑的always 块
OUT = IN1 + IN2;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.8位宽加法器仿真波形
从以上两张波形图可以看出4位宽加法器和8位宽加法器的输出延迟差别不大,基本都在8ns左右。
补码加法器
一.实验内容
1.把加法器的输出信号改成4比特位宽,编译,波形仿真。观察输出结果,观察输出结果在什么时候是正确的?
2. 把加法器的输入信号改成8比特位宽,编译,波形仿真。观察加法器的输出延迟,和4比特输入位宽的情况对比。
二.实验步骤
1.编写4比特位宽输出加法器的Verilog HDL代码
module top(
IN1 ,
IN2 ,
OUT );
input signed [3:0] IN1, IN2;
output signed [3:0] OUT;
reg signed [3:0] OUT;
always@(IN1 or IN2) begin // 生成组合逻辑的always 块
OUT = IN1 + IN2;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.仿真结果波形
从仿真结果可知,当两个输入信号的和大于7或小于-8时计算结果会出错,这是由于次高位进位使得符号位变化导致的。
3.编写8比特位宽输出加法器的Verilog HDL代码
module top(
IN1 ,
IN2 ,
OUT );
input signed [7:0] IN1, IN2;
output signed [8:0] OUT;
reg signed [8:0] OUT;
always@(IN1 or IN2) begin // 生成组合逻辑的always 块
OUT = IN1 + IN2;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.仿真结果波形
由仿真波形可知,4位补码加法器和8位补码加法器的延迟时间相差不多,基本都是8ns。
带流水线的加法器
一.实验内容
1.不改变流水线的级数,把加法器的输入信号改成8比特位宽,编译,波形仿真,和不带流水线的情况对比一下,你有什么结论?
2.在8比特输入位宽的情况下,在输入上再添加一级流水线,观察编译和仿真的结果,你有什么结论?
二.实验步骤
1.编写8位输入带一级流水线的加法器的Verilog HDL代码
module top(
IN1 ,
IN2 ,
CLK ,
OUT );
input [7:0] IN1, IN2;
input CLK;
output [8:0] OUT;
reg [7:0] in1_d1R, in2_d1R;
reg [8:0] adder_out, OUT;
always@(posedge CLK) begin // 生成D触发器的always块
in1_d1R <= IN1;
in2_d1R <= IN2;
OUT <= adder_out;
end
always@(in1_d1R or in2_d1R) begin // 生成组合逻辑的always 块
adder_out = in1_d1R + in2_d1R;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.仿真结果波形
带有流水线的加法器相较于没有流水线的加法器拥有更短的毛刺,但输出延时更长。
3.RTL View
4.编写8位输入带两级级流水线的加法器的Verilog HDL代码
module top(
IN1 ,
IN2 ,
CLK ,
OUT );
input [7:0] IN1, IN2;
input CLK;
output [8:0] OUT;
reg [7:0] in1_d1R, in2_d1R, in1_d2R, in2_d2R;
reg [8:0] adder_out, OUT;
always@(posedge CLK) begin // 生成D触发器的always块
in1_d1R <= IN1;
in1_d2R <= in1_d1R;
in2_d1R <= IN2;
in2_d2R <= in2_d1R;
OUT <= adder_out;
end
always@(in1_d2R or in2_d2R) begin // 生成组合逻辑的always块
adder_out = in1_d2R + in2_d2R;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5.仿真结果波形
增加一级流水线后使得毛刺的时间长度进一步减小,但是输出延迟变得更大。
6.RTL View
乘法器
一.实验内容
1.改变乘法器的输入位宽为8比特,编译,波形仿真,观察信号毛刺的时间长度。
2.选一款没有硬件乘法器的FPGA芯片(例如Cyclone EP1C6)对比8比特的乘法器和加法器两者编译之后的资源开销(Logic Cell的数目)
3.编写一个输入和输出都有D触发器的流水线乘法器代码,编译后波形仿真,观察组合逻辑延迟和毛刺的时间,和不带流水线的情况下对比。
二.实验步骤
1.编写8位输入的乘法器的Verilog HDL代码
//////////////////// 有符号的2补码乘法器 /////////////////////////
module top(
IN1 ,
IN2 ,
OUT );
input signed[7:0] IN1, IN2;
output signed [15:0] OUT;
reg signed[15:0] OUT;
always@(IN1 or IN2) begin // 生成组合逻辑的always 块
OUT = IN1 * IN2;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.仿真结果波形
从图中可得,毛刺信号约占4ns。
3.没有硬件乘法器的FPGA芯片的8比特加法器和乘法器的资源开销对比
加法器资源开销:
乘法器硬件开销:
由上图可见,乘法器相较加法器更加消耗资源。
4.输入和输出都有D触发器的流水线乘法器的Verilog HDL代码
//////////////////// 带有流水线的补码乘法器 /////////////////////////
module top(
IN1 ,
IN2 ,
CLK ,
OUT );
input signed[7:0] IN1, IN2;
input CLK;
output signed [15:0] OUT;
reg signed[15:0] OUT;
reg signed[7:0] in1_d1R, in2_d1R;
reg signed[15:0] mul_out;
always@(posedge CLK) begin // 生成D触发器的always块
in1_d1R <= IN1;
in2_d1R <= IN2;
OUT <= mul_out;
end
always@(in1_d1R or in2_d1R) begin // 生成组合逻辑的always 块
mul_out = in1_d1R * in2_d1R;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5.仿真结果波形
有仿真波形可得:带有流水线的乘法器的组合逻辑延迟和毛刺的时间约为2ns,相比不带流水线的乘法器要减少了一半。
计数器
一.实验内容
1.设计一个最简单的计数器,只有一个CLK输入和一个Overflow输出,当计数到最大值的时钟周期CLK输出1
2.设计复杂的计数器,和本例相似,带有多种信号,其中同步清零CLR的优先级最高,使能EN次之,LOAD最低。
二.实验步骤
1.编写简单计数器的Verilog HDL代码
//////////////////// 计数器代码 /////////////////////////
module top(
CLK , // 时钟,上升沿有效
OV );// 计数溢出信号,计数值为最大值时该信号为1
input CLK ;
output OV;
reg OV;
reg [3:0] CNTVAL, cnt_next;
// 电路编译参数,最大计数值
parameter CNT_MAX_VAL = 9;
// 组合逻辑,生成cnt_next
always @(CNTVAL) begin
if(CNTVAL < CNT_MAX_VAL) begin // 未计数到最大值, 下一值加1
cnt_next = CNTVAL + 1'b1;
end
else begin // 计数到最大值,下一计数值为0
cnt_next = 0;
end
end
// 时序逻辑 更新下一时钟周期的计数值
// CNTVAL 会被编译为D触发器
always @ (posedge CLK) begin
CNTVAL <= cnt_next;
end
// 组合逻辑,生成OV
always @ (CNTVAL) begin
if(CNTVAL == CNT_MAX_VAL)
OV = 1;
else
OV = 0;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2.仿真结果波形
如波形图所示,当经过9个周期的时钟信号后OV端口输出一个高电平的溢出信号。
3.编写复杂计数器的Verilog HDL代码
//////////////////// 计数器代码 /////////////////////////
module top(
RST , // 异步复位, 高有效
CLK , // 时钟,上升沿有效
EN , // 输入的计数使能,高有效
CLR , // 输入的清零信号,高有效
LOAD , // 输入的数据加载使能信号,高有效
DATA , // 输入的加载数据信号
CNTVAL, // 输出的计数值信号
OV );// 计数溢出信号,计数值为最大值时该信号为1
input RST , CLK , EN , CLR , LOAD ;
input [3:0] DATA ;
output [3:0] CNTVAL;
output OV;
reg [3:0] CNTVAL, cnt_next;
reg OV;
// 电路编译参数,最大计数值
parameter CNT_MAX_VAL = 9;
// 组合逻辑,生成cnt_next
// 1st clr ,2nd en , 3rd load
always @(EN or CLR or LOAD or DATA or CNTVAL) begin
if(CLR) begin // 清零有效
cnt_next = 0;
end
else begin // 清零无效
if(EN) begin // 使能有效
if(LOAD) begin // 加载有效
cnt_next = DATA;
end
else begin // 加载无效,正常计数
// 使能有效,清零和加载都无效,根据当前计数值计算下一值
if(CNTVAL < CNT_MAX_VAL) begin // 未计数到最大值, 下一值加1
cnt_next = CNTVAL + 1'b1;
end
else begin // 计数到最大值,下一计数值为0
cnt_next = 0;
end
end // else LOAD
end // EN
else begin // 使能无效,计数值保持不动
cnt_next = CNTVAL;
end // else EN
end //else CLR
end
// 时序逻辑 更新下一时钟周期的计数值
// CNTVAL 会被编译为D触发器
always @ (posedge CLK or posedge RST) begin
if(RST)
CNTVAL <= 0;
else
CNTVAL <= cnt_next;
end
// 组合逻辑,生成OV
always @ (CNTVAL) begin
if(CNTVAL == CNT_MAX_VAL)
OV = 1;
else
OV = 0;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
4.仿真结果波形
由仿真结果可知,计数器按照同步清零CLR的优先级最高,使能EN次之,LOAD最低的设置工作。
状态机
一.实验内容
1.设计一个用于识别2进制序列“1011”的状态机
基本要求:
电路每个时钟周期输入1比特数据,当捕获到1011的时钟周期,电路输出1,否则输出0
使用序列101011010作为输出的测试序列
扩展要求:
给你的电路添加输入使能端口,只有输入使能EN为1的时钟周期,才从输入的数据端口向内部获取1比特序列数据。
二.实验步骤
1.绘制状态跳转逻辑表
| 当前状态 | IN | EN | 次态 |
|---|---|---|---|
| ST_0 | 0 | 0 | ST_0 |
| ST_0 | 0 | 1 | ST_0 |
| ST_0 | 1 | 0 | ST_0 |
| ST_0 | 1 | 1 | ST_0 |
| ST_1 | 0 | 0 | ST_1 |
| ST_1 | 0 | 1 | ST_2 |
| ST_1 | 1 | 0 | ST_1 |
| ST_1 | 1 | 1 | ST_1 |
| ST_2 | 0 | 0 | ST_2 |
| ST_2 | 0 | 1 | ST_0 |
| ST_2 | 1 | 0 | ST_2 |
| ST_2 | 1 | 1 | ST_3 |
| ST_3 | 0 | 0 | ST_3 |
| ST_3 | 0 | 1 | ST_2 |
| ST_3 | 1 | 0 | ST_3 |
| ST_3 | 1 | 1 | ST_4 |
| ST_4 | X | X | ST_0 |
2.绘制输出逻辑表
| 当前状态 | 输出 |
|---|---|
| ST_0 | 0 |
| ST_1 | 0 |
| ST_2 | 0 |
| ST_3 | 0 |
| ST_4 | 1 |
3.编写Verilog HDL代码
//////////////////// 三段式状态机代码 /////////////////////////
module top(
CLK , // clock
RST , // reset
IN , // input
EN , // EN
OUT ); // output
input CLK ;
input RST ;
input EN ;
input IN ;
output OUT ;
parameter ST_0 = 0;
parameter ST_1 = 1;
parameter ST_2 = 2;
parameter ST_3 = 3;
parameter ST_4 = 4;
reg [2:0]stateR ;
reg [2:0]next_state ;
reg OUT ;
// calc next state
always @ (IN or EN or stateR) begin
case (stateR)
ST_0 :begin if(IN==0&&EN==0) next_state = ST_0 ; else if(IN==0&&EN==1) next_state = ST_0; else if(IN==1&&EN==0) next_state = ST_0; else if(IN==1&&EN==1) next_state = ST_1; end
ST_1 :begin if(IN==0&&EN==0) next_state = ST_1 ; else if(IN==0&&EN==1) next_state = ST_2; else if(IN==1&&EN==0) next_state = ST_1; else if(IN==1&&EN==1) next_state = ST_1; end
ST_2 :begin if(IN==0&&EN==0) next_state = ST_2 ; else if(IN==0&&EN==1) next_state = ST_0; else if(IN==1&&EN==0) next_state = ST_2; else if(IN==1&&EN==1) next_state = ST_3; end
ST_3 :begin if(IN==0&&EN==0) next_state = ST_3 ; else if(IN==0&&EN==1) next_state = ST_2; else if(IN==1&&EN==0) next_state = ST_3; else if(IN==1&&EN==1) next_state = ST_4; end
ST_4 :begin next_state = ST_0; end
endcase
end
// calc output
always @ (stateR) begin
if(stateR == ST_4)
OUT = 1'b1;
else
OUT = 1'b0;
end
// state DFF
always @ (posedge CLK or posedge RST)begin
if(RST)
stateR <= ST_0;
else
stateR <= next_state;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
4.仿真结果波形
移位寄存器
一.实验内容
设计一个带加载使能和移位使能的并入串出的移位寄存器,电路的RTL结构图如下图图所示。
二.实验步骤
1.编写移位寄存器代码
///////////////////////////////PISO WITH EN_LOAD AND EN_SHIFT////////////////////////////////
module top(
CLK , //时钟信号
RST , //复位信号输入
EN_LOAD , //加载输入数据使能
EN_SHIFT , //移位使能
IN , //并行输入数据
OV , //一组数据完全移出提示
OUT );//穿行输出
input RST, CLK, EN_LOAD, EN_SHIFT;
input [7:0] IN;
output OUT,OV;
reg shift_R,OV;
reg [7:0] shift_V;
reg [3:0] n;//移位次数计数
assign OUT = shift_R;//最右端移出数据
always @ (posedge CLK or posedge RST) begin
if(RST) begin
shift_R <= 0;
shift_V <= 0;
n <= 0;
end
else begin
if(EN_SHIFT) begin
if(EN_LOAD) begin
shift_V <= IN;并行输入载入
end
else begin
shift_R <= shift_V[0];
shift_V[6:0] <= shift_V[7:1];
shift_V[7] <= 0;//一次移位完成
n <= n + 1;//移位次数+1
end
end
else begin
shift_R <= shift_R;//未使能移位,保持不动
end
end
end
always @ (n) begin
if(n==8) //当移完一组(8bit)数据后OV端口输出1提示
OV = 1;
else
OV = 0;
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2.仿真结果波形