首先,先简单解释一下笛卡尔积。
现在,我们有两个集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的结果集就可以分别表示为以下这种形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
以上A×B和B×A的结果就可以叫做两个集合相乘的‘笛卡尔积’。
从以上的数据分析我们可以得出以下两点结论:
1,两个集合相乘,不满足交换率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数;
数据库表连接数据行匹配时所遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
比如现在数据库中有两张表,student表和 student_subject表,如下所示:
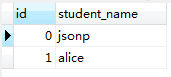
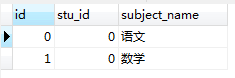
我们执行以下的sql语句,只是纯粹的进行表连接。
SELECT * from student JOIN student_subject;
SELECT * from student_subject JOIN student;看一下执行结果:
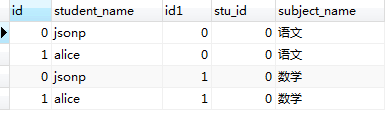
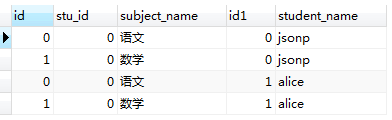
表1.0 表1.1
从执行结果上来看,结果符合我们以上提出的两点结论(红线标注部分);
以第一条sql语句为例我们来看一下他的执行流程,
1,from语句把student表 和 student_subject表从数据库文件加载到内存中。
2,join语句相当于对两张表做了乘法运算,把student表中的每一行记录按照顺序和student_subject表中记录依次匹配。
3,匹配完成后,我们得到了一张有 (student中记录数 × student_subject表中记录数)条的临时表。 在内存中形成的临时表如表1.0所示。我们又把内存中表1.0所示的表称为‘笛卡尔积表’。
针对以上的理论,我们提出一个问题,难道表连接的时候都要先形成一张笛卡尔积表吗,如果两张表的数据量都比较大的话,那样就会占用很大的内存空间这显然是不合理的。所以,我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN。
因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用 FROM table1,table2 WHERE xxx 的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。
根据(https://blog.csdn.net/wplblog/article/details/86686132)文章的解说,及本篇博客的分析,我们可以总结出一条查询sql语句的执行流程。
From
ON
JOIN
WHERE
GROUP BY
SELECT
HAVING
ORDER BY
LIMIT