目录
题目来源:牛客网
1.以下哪个是常见的时间序列算法模型
A.RSI
B.MACD
C.ARMA
D.KDJ
解析
时间序列是时间间隔不变的情况下收集的不同时间点数据集合,这些集合被分析用来了解长期发展趋势及为了预测未来。
常用的时间序列模型有
AR模型(Autoregressive model:自回归模型)、
MA模型(moving average model:滑动平均模型)、
ARMA模型(Auto-Regressive and Moving Average Model:自回归滑动平均模型)
ARIMA模型(Autoregressive Integrated Moving Average Model:自回归积分滑动平均模型)等
相对强弱指数 (RSI, Relative Strength Index) 是通过比较一段时期内的平均收盘涨数和平均收盘跌数来分析市场买沽盘的意向和实力 , 从而作出未来市场的走势
移动平均聚散指标 (MACD, Moving Average Convergence Divergence), 是根据均线的构造原理 , 对股票价格的收盘价进行平滑处理 , 求出算术平均值以后再进行计算 , 是一种趋向类指标
随机指标 (KDJ) 一般是根据统计学的原理 , 通过一个特定的周期 ( 常为 9 日 ,9 周等 ) 内出现过的最高价 , 最低价及最后一个计算周期的收盘价及这三者之间的比例关系 , 来计算最后一个计算周期的未成熟随机值 RSV, 然后根据平滑移动平均线的方法来计算 K 值 , D 值与 J 值 , 并绘成曲线图来研判股票走势
参考
算法模型---时间序列模型(可以详细阅读一下)
题目下‘嘻嘻兔’及‘伊利殺白’的解答
2.下列不是SVM核函数的是:
A.多项式核函数
B.logistic核函数
C.径向基核函数
D.Sigmoid核函数
解析
SVM核函数包括线性核函数、多项式核函数、径向基核函数、高斯核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数
参考
牛客‘忆梦&....’的答案
3.统计模式分类问题中,当先验概率未知时,可以使用()
A.最小最大损失准则
B.最小误判概率准则
C.最小损失准则
D.N-P判决
4.以下()不属于线性分类器最佳准则?
A.感知准则函数
B.贝叶斯分类
C.支持向量机
D.Fisher准则
解析
线性分类器:模型是参数的线性函数,分类平面是(超)平面
典型的线性分类器有:感知机、SVM支持向量机(线性核)、LDA线性判别分析(Fisher准则)
非线性分类器:模型的分界面可以是曲面或者超平面的组合
典型的非线性分类器:朴素贝叶斯(特定的某些朴素贝叶斯分类器本质上是线性分类器)、KNN、决策树、SVM支持向量机(非线性核)
参考
5.下列哪些方法可以用来对高维数据进行降维:
A.主成分分析法-PCA
B.线性判别法-LDA
C.LASSO
D.聚类分析
E.小波分析法
F.拉普拉斯特征映射
解析
降维的目的:便于计算和可视化;有利于提取有效信息、摈弃无用信息
降维的主要方法:线性映射和非线性映射
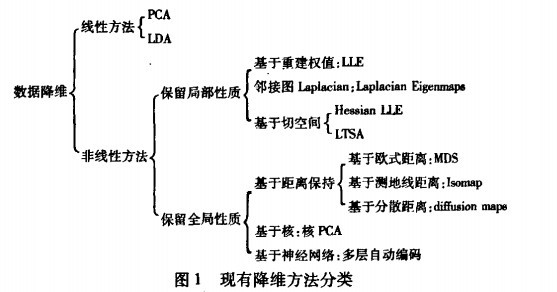
PCA主成分分析,是一种使用最广泛的数据压缩算法。是一种非监督学习算法。
LDA线性判别法,将有标签的数据点,通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分。(高内聚,低耦合)
LASSO,一种压缩估计,它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,得到可以解释的模型。lasso通过参数缩减达到降维的目的
聚类分析,将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。
小波分析法
拉普拉斯特征映射,它的直观思想是希望相互间有关系的点(在图中相连的点)在降维后的空间中尽可能的靠近
参考
机器学习降维方法概况(可以详细阅读一下)
高纬数据的降维方法(图片来源)
6.机器学习中做特征选择时,可能用到的方法有?
A.卡方
B.信息增益
C.平均互信息
D.期望交叉熵
解析
特征提取算法分为特征选择和特征抽取两大类
特征选择
常采用特征选择方法。常见的六种特征选择方法:
1、DF(Document Frequency) 文档频率
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性
2、MI(Mutual Information) 互信息法
互信息法用于衡量特征词与文档类别直接的信息量。
如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向”低频”的特征词。
相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3、(Information Gain) 信息增益法
通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
4、CHI(Chi-square) 卡方检验法
利用了统计学中的”假设检验”的基本思想:首先假设特征词与类别直接是不相关的
如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。
5、WLLR(Weighted Log Likelihood Ration)加权对数似然
6、WFO(Weighted Frequency and Odds)加权频率和可能性
特征抽取(降维(见上一题))
参考
牛客‘chen尾巴’的答案