版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013700358/article/details/83963626
今天在使用pandas时,使用了类似如下的代码片段:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime
from matplotlib.ticker import FuncFormatter
l = [[1, '1', 'c dd', 2], [11, '11', 'cc ddd', 22], [111, '111', 'ccc dddd', 222]]
p = pd.DataFrame(l, columns=['c1', 'c2', 'c3', 'c4'])
print(p)
print('---------------------------')
y1 = p[p['c3'].str.contains('cc')]
print(y1)
print(type(y1))
print(y1.loc['c3'])
出现了如下的错误:
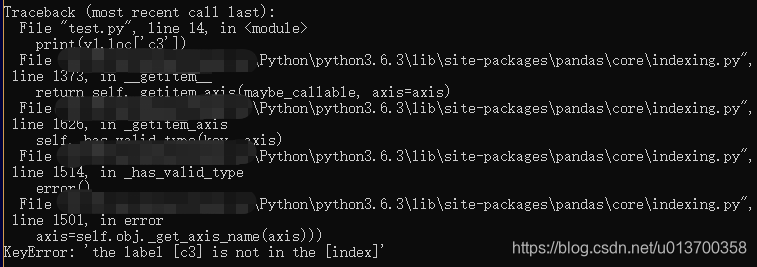 具体定位到的语句即
具体定位到的语句即print(y1.loc['c3']),这时候有些奇怪,之前也这么使用过,但没报错,会看之前的使用,为:
y3 = p.iloc[1, ]
y4 = y3.loc['c1']
输出第二种的y3:
c1 11
c2 11
c3 cc ddd
c4 22
Name: 1, dtype: object
看到使用iloc时,已经将DataFrame转换成了Series这时候才回想起来,loc是按照行名进行索引,因此第一种报错的c3是列名,很明显行名是不包含c3的,因此报错。若要按列名索引,则直接y1['c3']即可,由此所得依旧是一个Series,若要取出该Series中的某个值,可先将其转换为list,如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime
from matplotlib.ticker import FuncFormatter
l = [[1, '1', 'c dd', 2], [11, '11', 'cc ddd', 22], [111, '111', 'ccc dddd', 222]]
p = pd.DataFrame(l, columns=['c1', 'c2', 'c3', 'c4'])
print(p)
print('---------------------------')
y1 = p[p['c3'].str.contains('cc')]
print(y1)
print(type(y1))
yL = list(y1['c3'])
print(yL[1])
运行结果如下
c1 c2 c3 c4
0 1 1 c dd 2
1 11 11 cc ddd 22
2 111 111 ccc dddd 222
---------------------------
c1 c2 c3 c4
1 11 11 cc ddd 22
2 111 111 ccc dddd 222
<class 'pandas.core.frame.DataFrame'>
ccc dddd
问题解决。
最后说一下,代码中p[p['c3'].str.contains('cc')]函数表示从第c3列中选取所有包含cc的数据,最后所得依旧是一个DataFrame类型
而通过loc其实也可以根据列来取出数据,如:
yy = p.loc[p['c3'] >= 'cc']
print(yy)
将会输出c3列的数据中>='cc'的行,即:
c1 c2 c3 c4
1 11 11 cc ddd 22
2 111 111 ccc dddd 222