堆排序
堆就是一个完全二叉树, 可以用数组来实现;
大根堆:任何一棵子树最大的是子树的头部;
建立大根堆的过程 O(n), 顺序遍历数组,每个元素作为 index, index 只与父节点比较,直到 <= 父节点。整个建立大根堆的过程可以简单理解为大数上浮
排序(小数下沉):将根节点(此时为最大值)与末尾交换(此时末尾部分有序),末尾的小数交换到 root, 然后执行小数下沉的过程,再筛选出无序部分的最大值放到 root。再循环,直到所有部分有序。
堆排序的主要时间花在初始建堆期间,建好堆后,堆这种数据结构以及它奇妙的特征,使得找到数列中最大的数字这样的操作只需要O(1)的时间复杂度,维护需要logn的时间复杂度。堆排序不适宜于记录数较少的文件
性能:时间复杂度O(nlohn), 空间复杂度O(1)
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int i = 0; i < arr.length; i++) { //建大根堆
heapInsert(arr, i);
}
int size = arr.length;
swap(arr, 0, --size); //交换根与末尾节点, 小数下沉(更新根)
while (size > 0) {
heapify(arr, 0, size);
swap(arr, 0, --size);
}
}
//保证父节点大于子节点, 大数上浮
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
//小数下沉
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; //左孩子
while (left < heapSize) { //存在左孩子时执行 (下沉)
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ?
left + 1 : left;
largest = arr[largest] > arr[index] ? largest : index;
if (index == largest) {
break;
}
//此时 index < 左右子树最大值, 下沉
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
过程图
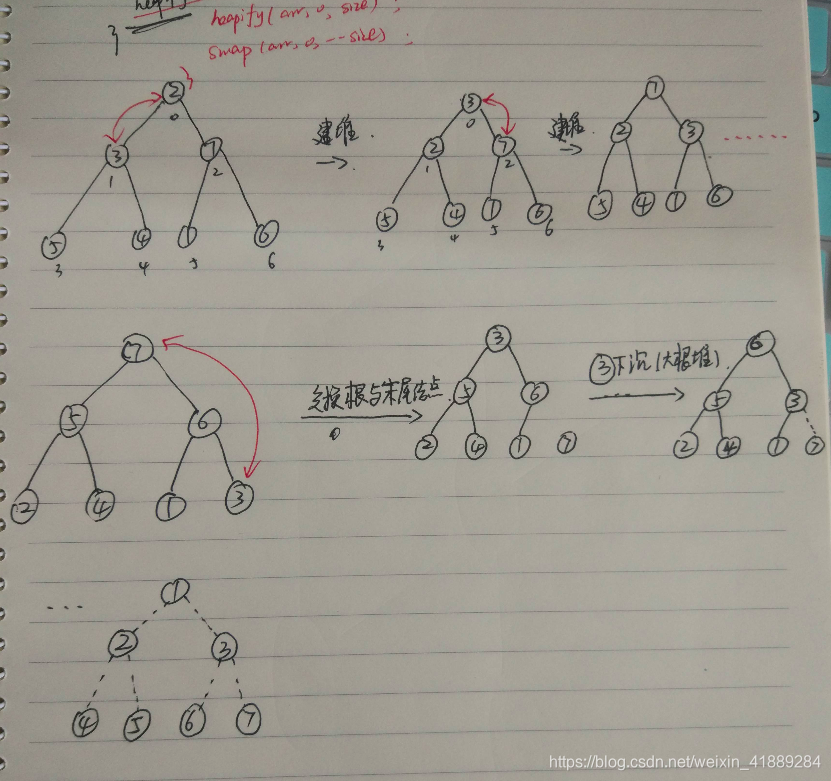
为什么堆排序是不稳定的?
如下图,两种不同结构可以建成一样的堆,但是结构2在建堆的过程中稳定性被破坏。

二叉树排序
- 若左子树不空, 则左子树上所有节点都小于根节点
- 若右子树不空, 则右子树上所有节点都大于根节点
- 中序 (中根) 遍历后是增序。
排序时间复杂度为, O(nlogn), 构建二叉树需要额外的 O(n) 的存储空间。
相同元素如果放在其右子树,可以保证中序遍历的稳定性, 所以二叉树排序是稳定的。
//二叉树的构建
public void insert(TreeNode root, TreeNode newNode) {
if (root == null || newNode == null) return;
//TreeNode node = root; //当前树根
if (newNode.value < root.value) { //相等时放到右子树可以保证稳定性
if (root.lchild == null) { //当前 node 为叶子
newNode.parent = root;
root.lchild = newNode;
} else {
insert(root.lchild, newNode);
}
} else {
if (root.rchild == null) { //root 无右子树
newNode.parent = root;
root.rchild = newNode;
} else { //有右子树, 递归插入
insert(root.rchild, newNode);
}
}
}
//中序遍历
public void midPrint(TreeNode root) {
if (root != null) {
midPrint(root.lchild);
System.out.println(root.value);
midPrint(root.rchild);
}
}
//测试用例
public static void main(String[] args) {
Tree tree = new Tree();
TreeNode root = new TreeNode(7);
tree.insert(root, new TreeNode(3));
tree.insert(root, new TreeNode(99));
tree.insert(root, new TreeNode(1));
tree.insert(root, new TreeNode(0));
tree.insert(root, new TreeNode(5));
tree.insert(root, new TreeNode(1));
tree.midPrint(root);
}

希尔排序
希尔排序的基本思想是通过设置一个增量,将需要排序的序列划分成若干个较小的子序列,对子序列进行插入排序。 通过插入排序能够使原来序列部分有序。然后再通过减小增量,对跨度更小的子序列进行排序,进而越来越有序。
应用增量的好处是尽可能的减少了移动和比较的次数。
不稳定,时间复杂度不确定, 空间复杂度 O(1)
public static void shellSort(int[] arr) {
if (arr == null || arr.length < 2) return;
//设置增量
int increment = arr.length >> 1;
while (increment >= 1) {
for (int i = 0; i < arr.length - increment; i++) { //一种增量的循环
//到 length -increment
int j = i;
while (j >= 0 && arr[j] > arr[j + increment]) { //回跳
swap(arr, j, j + increment);
j -= increment;
}
}
increment = increment >> 1;
}
}
排序总结
稳定
| sort | 最差时间 | 最好时间 | 平均时间 | 稳定 | 空间复杂度 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | 稳定 | O(1) |
| 插入排序 | O(n^2) | O(n) | O(n^2) | 稳定 | O(1) |
| 二叉树排序 | O(n^2) | O(nlogn) | O(nlogn) | 稳定 | O(n) |
| 归并排序l | O(nlogn) | O(nlogn) | O(nlogn) | 稳定 | O(n) |
不稳定
| sort | 最差时间 | 最好时间 | 平均时间 | 稳定 | 空间复杂度 |
|---|---|---|---|---|---|
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | 不稳定 | O(1) |
| 快排 | O(n^2) | O(nlogn) | O(nlogn) | 不稳定 | O(logn ~ O(n)) |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | 不稳定 | O(1) |
| 希尔排序 | 不稳定 | O(1) |
注:空间复杂度O(1)为原地排序