1. 数据流分析的相关概念
基于结构测试的方案还有一种测试方法,就是数据流分析测试。 数据流分析测试是指变量 定义(赋值)与使用位置的 一种基于程序结构性的测试方法。该分析方法重点关注变量的定义与使用。在选定的一组代码中搜索某个变量所有的定义、使用位置,并检查在程序运行时该变量的值将会如何变化,从而分析是否是 Bug 的产生原因。
数据流分析与路径测试的区别在于:路径测试基本上是从数学(控制流图)角度来分析的,而数据流测试则是利用了变量之间的关系,通过定义-使用路径和程序片,得到一系列的测试指标用于衡量测试的覆盖率。
数据流分析定义
数据流指的是数据对象的顺序和可能状态的抽象表示。 数据对象的状态可以是创建/定义(Creation/Defined)、使用(Use)和清除/销毁(Killed/Destruction)。数据值的变量存在从创建、使用到销毁的一个完整状态。 编码错误导致的变量赋值错误检查是发现代码缺陷或错误的一种有效方法。实际上该方法可认为是路径测试的“真实性”检查,是对基于路径测试的一种改良。
数据流分析的功能作用
数据流分析的作用是用来测试变量设置点和使用点之间的路径。这些路径也 称为“定义-使用对”(definition-use 或 du-pairs)或“设置-使用对”。通过数据流分析而生成的测试集可用来获得针对每个变量的“定义-使用对”的 100%覆盖。但是,要追踪整个程序代码中的每个变量的设置和使用时,并不需在测试时考虑被测对象的控制流。
程序代码路径中首次出现的变量可能存在的状态组合
~d 变量不存在或没定义(通过 ~ 表示),然后定义(d),~d 是正确的。
~u 变量不存在或没定义,然后使用(u), ~u 是错误的,因为变量使用之前必须定义。
~k 变量不存在或没定义,然后撤销(k), ~k 可能是错误的,因在创建变量之前撤销变量可能是一个潜在的编程错误。
d、u、k 的具体含义:
d: 变量声明或定义,且变量已赋值
u: 读取及使用
k: 声明或定义变量,但还未为其赋值或已释放变量(模块或函数 结束时),针对程序代码路径中的变量执行的顺序,变量状态 d、u、k 的组合可能会有 33=9 种情况
dd:变量赋值后再次赋值,可疑的或可能是编程错误。
du:变量赋值后使用,正确。是程序代码中的正常情况。
dk:变量定义后撤销,可疑的或可能是编程错误。
ud:变量使用后再定义,可以接受。
uu:变量使用之后再使用,可以接受。
uk:变量使用之后撤销,可以接受。
kd:变量撤销后再定义,可以接受,变量撤销之后重新定义。
ku:变量未定义或撤销后使用,严重问题,在变量不存在或没有定
义的情况下,使用变量是错误的。
kk:变量未定义或撤销之后再撤销,可能是编程错误。
数据流分析可基于数据流图而展开
数据流图类似于控制流图,描述了测试对象代码的处理过程。同时也详细描 述了代码中变量的创建、使用和撤销的状态。通过检查数据流图来验证测试对象代码中每个变量的状态组合是否正确。
图 1 是一个数据流图的例。

通过分析每个变量的执行顺序状态,可以发现存在的一些问题。 这里,分析例中三个变量 x,y,z,其存在的状态组合如下:
变量 x,其状态的可能组合:
Define x
Use y
Kill z
Define y
Use z
Define x
Use x
Use z
Kill z
Use x
Define z
Use y
Use z
Kill y
Define z
~d:正确的情况
dd:定义之后再定义,可能是编程错误
du:定义之后使用,正确情况
变量 y,其状态的可能组合:
~u: 定义变量之前使用变量,严重错误
ud: 变量使用后再定义,可接受
du: 变量定义之后使用,正确情况
uk:变量使用之后撤销,可接受
dk:变量定义之后撤销,可能是编程错误
变量 z,其状态的可能组合:
~k:定义变量之前撤销变量,可能是编程错误
ku:变量撤销后使用变量,严重错误
uu: 使用变量后再使用变量,正确情况
ud:变量使用之后再定义,可接受
kk:撤销变量后再撤销,可能是编程错误
kd:变量撤销后再定义,可接受
du:变量定义之后使用变量,正常情况
因此,针对本例的数据流分析中可得出存在着下列问题:(对照前面
的组合状态定义和三个变量的组合状态)
变量 x 存在 dd 的编程错误
变量 y 存在 ~u 和 dk 的编程错误
变量 z 存在 ~k、ku、kk 编程错误
数据流分析方法是基于形式化的 从上可看出,数据流分析测试方法实 际上是形式化的。这样的方式,便于用来构造算法从而能够实现自动化的分析。
这里作如下定义:
- P 代表程序,G(P)为程序数据流图,V 为变量集合,P 的所有路径集合为 PATH(P)。
- 节点 n 是变量 v 的定义节点,记 DEF(v, n)。 输入、赋值、循环语句与 过程调用都是节点定义的实例。如果执行了定义这种语句的节点,那么与该变量关联的存储单元的内容就会改变。
- 节点 n 是变量 v 的使用节点,记 USE(v, n)。 输入、赋值、条件、循环控制语句、过程调用,都是使用节点语句实例。如果执行对应这种语句的节点,那么与该变量关联的存储单元的内容就保持不变。
- 例如 USE(v, n) 是谓词使用 (条件判断语句中),记为 P-use。
- 例如 USE(v, n) 是计算使用 (计算表达式中),记为 C-use。
- 变量 v 的定义-使用路径(define-use path), 记为 du-path。如果 PATH 中的某个路径,定义节点 DEF(v, n) 为该路径的起始节点,使用节点 USE(v, n)为该路径的终止节点,则该路径是 v 的定义-使用路径。
- 变量 v 的定义-清除路径(define-clear path),记为 dc-path。 如果变 量 v 的某个定义-使用路径,除了起始节点之外没有其他定义的节点,则该路径是变量 v 的定义-清除路径。
- 程序片:S (v,n) 指节点 n 之前的所有对 v 中的变量值,做出过‘操作’的所有语句片段的全部。显然,做出操作的一定是上面所述的 USE(v,n),这里的使用路径包括直接和间接的。
举例说明,比如说在结点 n 有个变量 a=a+b+c, 那么很显然,这里影响 a 的值包括 a,b,c, 所以自然要将在结点 n 前影响到值
a,b,c 三个变量的所有结点都要考虑。若出现了一个常量语句,如 b=1230, 即说明对 b 已经没有影响了。 程序片的一个最大使用是用来排除程序片段是否存在问题的。比如现在有两个程序片 p1、p2。一个是第 8 行的 v, 一个是第 10 行的 v,假设第 8 行和第 10行之间没有任何常量对 v 进行赋值,那么 p2= ( p1,9,10), 这里假设第 9 行和第10 行影响了 v 值,那么如果 8 行之前的程序片 p1 中的变量 v 没有发生问题,而第 10 行的程序片 p2 出现了问题,那么变量 v 的异常必定在 p2- p1 这段程
序片上。因此程序片能够很快定位出异常在哪里。 数据流测试常应用于计算密集程序。数据流能方便的描述程序的部分片段的结构,定义使用路径具有和程序片相似的性质,如果 p1 是包含了 p2 的一条定义使用路径,如果 p2 没有出现问题,那么问题必然出现在 p1-p2 这段路径上了。然后片与定义使用路径一个区别在于片并不能很好的反应测试用例,这个也很容易理解,因为片是反应局部状况的,而定义使用路径则是基于路径的,路径是具有结构化性质指标的。这些就是基于数据流测试的全部。
2.数据流覆盖指标(拉普斯-韦约克)
拉普斯-韦约克(Rapps-Weyuker)数据流覆盖层次结构图如图 2 所示。
这个数据流覆盖指标层次结构图描述了数据的“定义-使用”对,找出所有变量的定义-使用路径情况。实际上,这是变量的定义-使用路径情况的检查结构。当每个层次结构都检查完成,则表明针对变量的定义-使用路径达到 100% 的覆盖。 定义-使用路径是一组定义所得到的测试指标,包括全路径、全定义-使用路径、全使用、全计算使用/部分谓词使用、全谓词使用/部分计算使用、全定义、全谓词使用、全边、全节点。

图 2 Rapps-Weyuker 数据流覆盖层次结构图
数据流测试方法是在程序代码经过的路径上检查变量的数据的用法。这主要是为了发现“定义-使用”异常的缺陷。这里异常是指可能会导致程序失效的情形。如发现了数据流异常:“没有初始化就读取了变量的值,或根本没有使用变量的值“。异常可能会触发程序运行的风险,但并非数据流异常都会导致错误的程序行为发生(即失效)。因此对发现的数据流问题,需深入检查确定是否存在定义-使用问题。
2. 数据流分析的测试举例
【例 1】数据流分析举例
某片段程序如下:
1 a=5; //定义 a 并赋值 5
2 while (c1) {
3 if (c2) {
4 b=a*a; //使用 a
5 a=a-1; //定义且使用 a
6 }
7 print(a); //使用 a
8 print(b); } //使用 b 分析过程: 数据流覆盖指标(拉普斯-韦约克)层次结构图来描述上述程序的数据“定义-使用”对,并找出所有变量的“定义-使用“路径,可得到该程序数据流图 G(P) (图 3 所示)的使用路径 du-path 与清除路径 dc-path,定义-使用节点(表 1 所示)和定义-使用路径(表 2 所示),得到路径图 DD(图 4所示)


图 3 程序数据流图 G(P) 图 4 路径图 DD
du-path(使用路径) dc-path(清除路径)
1234 yes
12345 yes
1234567 no
567 yes
表 1 定义/使用节点
| 变量 | 定义节点 | 使用节点 |
| a | 1,5 | 4,5,7 |
| b | 4 | 8 |
表 2 定义/使用路径
| 变量 | 路径(开始、结束)节点 | 是定义清除吗? |
| a | 1,4 1,5 1,7 5,7 |
是 否 否 是 |
| b | 4,8 | 是 |
【例 2】进行给出的下列程序的数据流分析
1 long Add(int a, int b, int c )
2 { a=x+a;
3 while(a<1000 )
{
4 if( b<10||a>5 )
{
5 x=y+b;
}
else
{
6 y=y+a;
}
7 y=x+y;
}
8 return c ;
}
分析: 分析过程与【例 1】基本一致,这里不再赘述。这里主要分析该程序的变量的定义-使用情况:
- -引用未定义的变量;
- -所使用变量未被定义;
- -找出循环内定义的变量;
- -变量的赋值。
结果:
(1) 数据流图 如下图
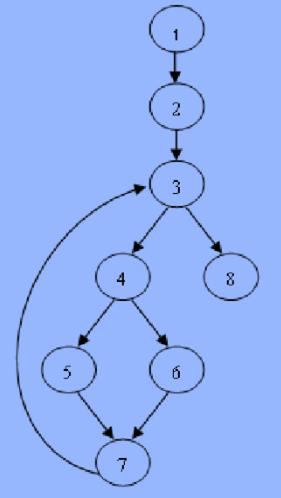
(2)变量的定义-使用 如下表
| 节点 | 被定义变量 | 被使用变量 |
| 1 | a、b、c | |
| 2 | a | x、a |
| 3 | a | |
| 4 | a、b | |
| 5 | x | y、b |
| 6 | y | y、a |
| 7 | y | X、y |
| 8 | c |
主要参考文献
1.《软件测试教程(第 3 版)》,贺平,电子工业出版社,2014
2.《软件测试设计》,马均飞 郑文强,电子工业出版社,2011