--函数与分组查询数据
(一) 系统函数
在SQL Server 2008中系统函数是指在SQL Server 2008中自带的函数,主要分为聚合函数、数据类型转换函数、日期函数、数学函数及其他一些常用的函数。
1 、聚合函数
对一组值进行计算,然后返回一个值。主要包括SUM(求和函数)、AVG(求平均值函数)、MIN(求最小值函数)MAX(求最大值函数)、COUNT(求数量的函数)
(1)SUM函数:主要用来求某一组值的和。
SUM(列名)【例1】求学生信息表中学生的年龄和。
学生信息表(STUINFO)
SELECT SUM(STUAGE)
FROM STUINFO;(2)AVG函数:用来一组值的平均值的。
AVG(列名)【例2】求学生信息表中学生年龄的平均值。
SELECT AVG(STUAGE)
FROM STUINFO;(3)MIN函数:是用来一组值的最小值的。
MIN(列名)【例10.3】求学生信息表中学生年龄中最小值
SELECT MIN (STUAGE)
FROM STUINFO;(4)MAX函数:用来一组值的最大值的
MAX(列名)【例4】求学生信息表中学生年龄的最大值。
SELECT MAX (STUAGE)
FROM STUINFO;(5)COUNT函数:用来求一组值的个数。
COUNT(列名)【例5】求学生信息表中学生的个数。
2、类型转换函数
在SQL Server 2008中,提供了CONVERT()和CAST()两个数据类型转换函数。
(1)CONVERT()函数
CONVERT( datatype[(length)],expression,[style])其中,
● datatype:表示要转换的数据类型,如果要转换成CHAR、VARCHAR、BINARY或VARBINARY数据类型,还要设置数据类型的长度。
● expression:表达式,要进行数据类型转换的值或列名。
● style:用于日期格式的设置。如果要将日期型数据转换为字符型数据,则还可以使用style参数设置日期显示格式。style参数的取值与日期显示格式如下表所示。
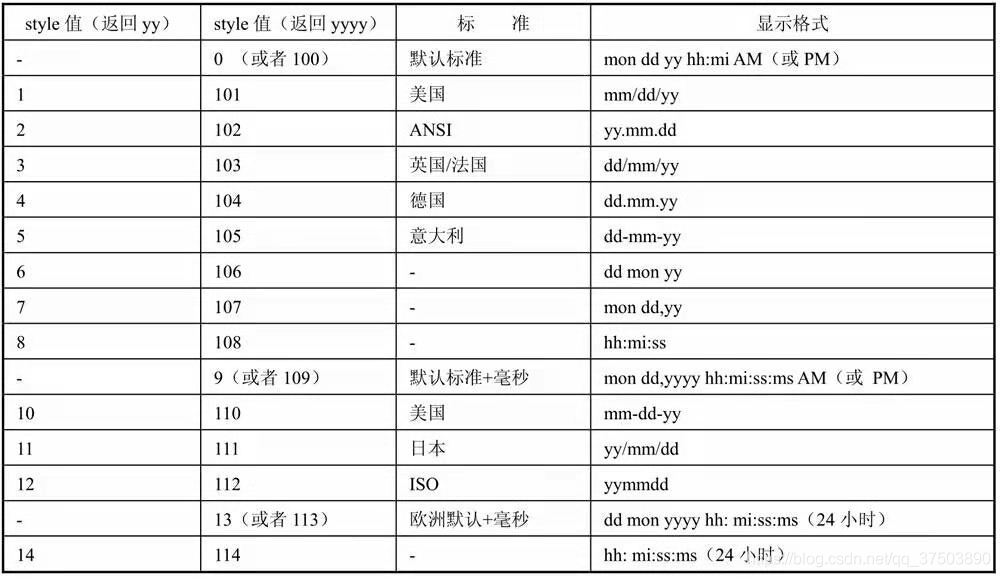
说明:style参数可以取两类值,如果从第一类取值,则返回日期的年份为2位;如果从第二类取值,则返回日期年份为4位。
【例6】把当前数据库的时间转换成字符类型。
获取当前数据库的时间使用的函数是GETDATE()。
SELECT CONVERT(CHAR, GETDATE())【例7】查询学生信息表中学生信息,并把学生的出生日期转换成字符类型。
SELECT STUNNAME,CONVERT(CHAR,STUSTUBIRTH,103)
FROM STUINFO2.CAST()函数
与CONVERT相比,在使用方面更加容易,但是如果要对日期类型转换时却没有CONVERT()函数方便。所以在一般数据类型转换时推荐使用CAST()函数,对于日期类型的转换要使用CONVERT()函数转换。
CAST (expression AS datatype[(length)])其中,
● expression为表达式。
● datatype为数据类型,如果是CHAR、VARCHAR、NUMERIC等数据类型,则可以选择length参数设置长度。
【例8】从STUINFO表中,查询所有学生的姓名、出生日期,并将日期转换为字符串显示。
SELECT STUNAME,CAST(STUSTUBIRTH AS char(10)) AS生日
FROM STUINFO3、日期函数
SQL Server支持的日期函数有GETDATE、DATEADD、DATEDIFF、DATENAME和DATEPART等函数。
(1)GETDATE函数:可获得当前系统时间。
SELECT GETDATE()(2)DATEADD函数:用于在指定日期上增加年、月、日或时间等,其返回值为日期型数据。其格式为:
DATEADD(datepart,number,date)datepart参数规定在日期的哪个部分(如年份、月份等)增加(减)数值。 datepart参数的可用值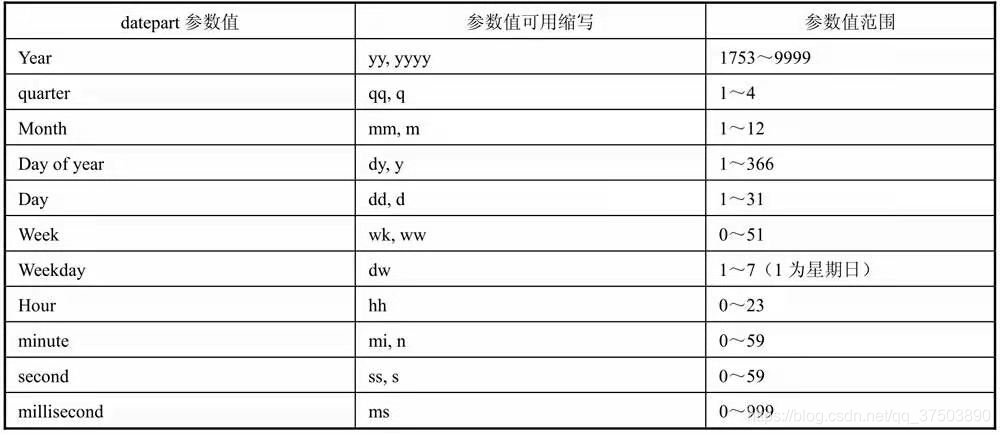
在当前时间的“年”上增加了5年,并返回5年后的日期.
DATEADD(year,5,GETDATE())在当前时间的“月”上增加了5个月,并返回5个月后的日期
DATEADD(month,5,GETDATE())说明:datepart参数值也可以使用缩写,例如,DATEADD(mm,5,GETDATE())也是在当前时间上增加5个月。
【例9】从STUINFO表中查询所有学生的姓名、出生日期、出生后的第8000天和出生后的第500个月。
SELECT STUNAME,
STUBRITH,
DATEADD(DAY,8000, STUBIRTH) AS ‘出生后第8000天’,
DATEADD(MONTH,500, STUBIRTH) AS ‘出生后第500月’
FROM STUINFO(3)DATEDIFF函数:用于获取两个日期间的差,并返回数值数据。
DATEDIFF(datepart,date1,date2)其中,datepart参数的说明同上,date1和date2是日期或日期格式的字符串。
【例10】从STUINFO表中查询所有学生的姓名、出生日期和年龄。
SELECT STUNAME,
STUSTUBIRTH,
DATEDIFF(year, STUSTUBIRTH,GETDATE()) AS年龄
FROM STUINFODATEDIFF(year, STUSTUBIRTH,GETDATE())//返回年份的差距,即年龄。DATEDIFF(month, STUSTUBIRTH,GETDATE())//返回的是当前时间和出生日期之间的月份的差距,即返回相差多少个月。(4)DATENAME函数:用于获取日期的一部份,并以字符串形式返回
DATENAME (datepart,date)其中,datepart参数的说明同上,date是日期或者日期格式的字符串。例如,假设当前日期为2010年2月25日,则DATENAME(month,GETDATE( ))的结果为字符串'02',DATENAME(dd,GETDATE( ))的结果为字符串'25'。
注意:假设当前日期为2010年3月5日,则DATENAME (dd,GETDATE( ))返回的结果为字符串'5',而并非是'05'。
【例11】从STUINFO表中查询每位1号出生的所有学生。
SELECT *
FROM STUINFO
WHERE DATENAME(day,STUSTUBIRTH)='1'注意:DATENAME函数返回的是字符串,因此必须与字符串('1')比较。
(5)DATEPART函数:用于获取日期的一部份,并以整数值返回:
DATEPART (datepart,date)其中,datepart参数的说明同上,date是日期或者日期格式的字符串。例如,假设当前日期为2010 年2 月25 日,则DATEPART (month,GETDATE())的结果为数值2,DATEPART (dd,GETDATE())的结果为数值25。
【例12】从STUINFO表中查询每位1号出生的所有学生。
SELECT *
FROM STUINFO
WHERE DATEPART (day, STUSTUBIRTH)=1注意:DATEPART函数返回的是数值,因此必须与数值(1)比较。
SQL Server中除上述日期时间函数以外,还有YEAR、MONTH、DAY三个函数,分别用于获取日期数据的年份、月份和日期部分,这三个函数的返回值都是数值型。
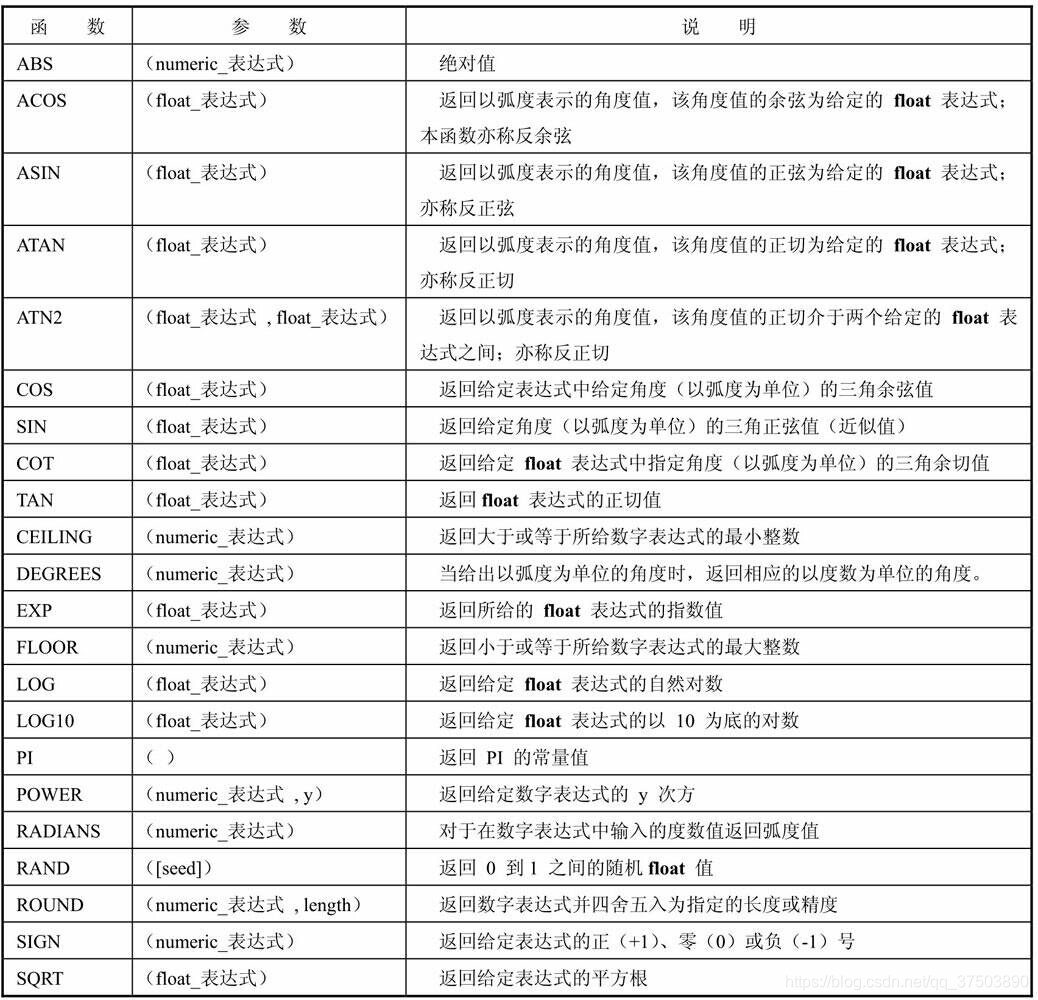
4、 数学函数
常用的SQL Server数学函数及其说明
【例13】使用数学函数,计算30度角的正弦值。
分析:首先应当使用RADIANS函数计算30度角的弧度值,其次对弧度值使用SIN函数求正弦值,最后应当对结果进行四舍五入计算。在查询分析器中输入如下SELECT语句,并运行。
SELECT ROUND(SIN(RADIANS(30.0)),1) AS ‘30度的正弦值’说明:将AS后的别名(30度的正弦值)放入单引号的原因是别名中有数字。
5 、字符函数
字符函数允许操作字符数据。常用的SQL Server字符函数及其说明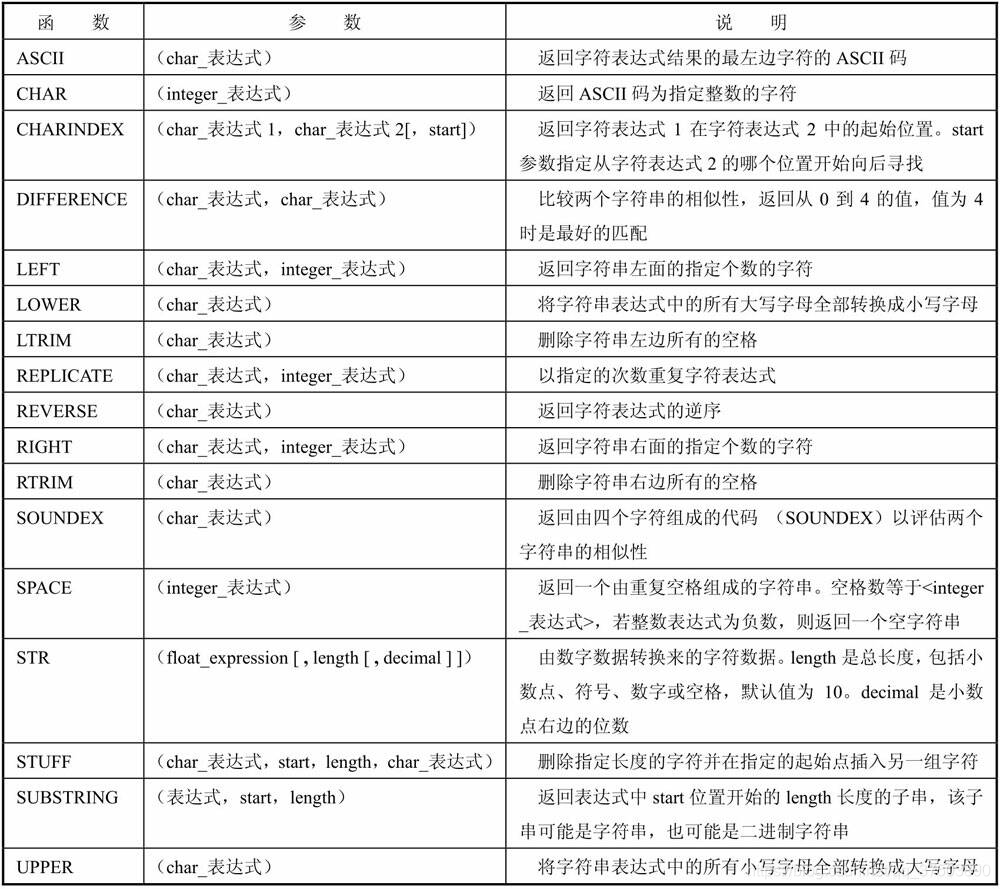
【例14】从STUINFO表中查询名为“Marry Lin”学生的所学专业。
分析:有时,人们经常会忽视英文字母的大小写,例如,将“Marry Lin”写为“marry lin”等,此时,如果数据库管理系统没有自动转换匹配的功能,则会将这两个字符串看做是不同人的姓名,从而导致查询出错。为了解决这类问题,应当将数据库中的字符串的所有字母转换为大写(或小写)字母,然后与大写(小写)字母的字符串比较,例如,下面的SELECT语句:
SELECT STUMAJOR
FROM STUINFO
WHERE UPPER(STUNAME)='MARRY LIN'说明:SQL Server 2008可以自动转换大小写字母进行匹配,但是,为了保险起见,查询英文字符串时,建议使用上述方法进行查询。
6、 其他几个系统函数
(1)文本和图像函数:对文本或图像输入的值或列进行处理,并返回有关该值的信息。
常用的文本和图像函数
(2)配置函数:返回有关配置设置的信息。
常用的配置函数
(3)游标函数:返回有关游标状态的信息。
常用的游标函数
(4)元数据函数:返回数据库和数据库对象的属性信息。元数据是描述数据的数据,通常用于描述数据的结构和意义。
常用的元数据函数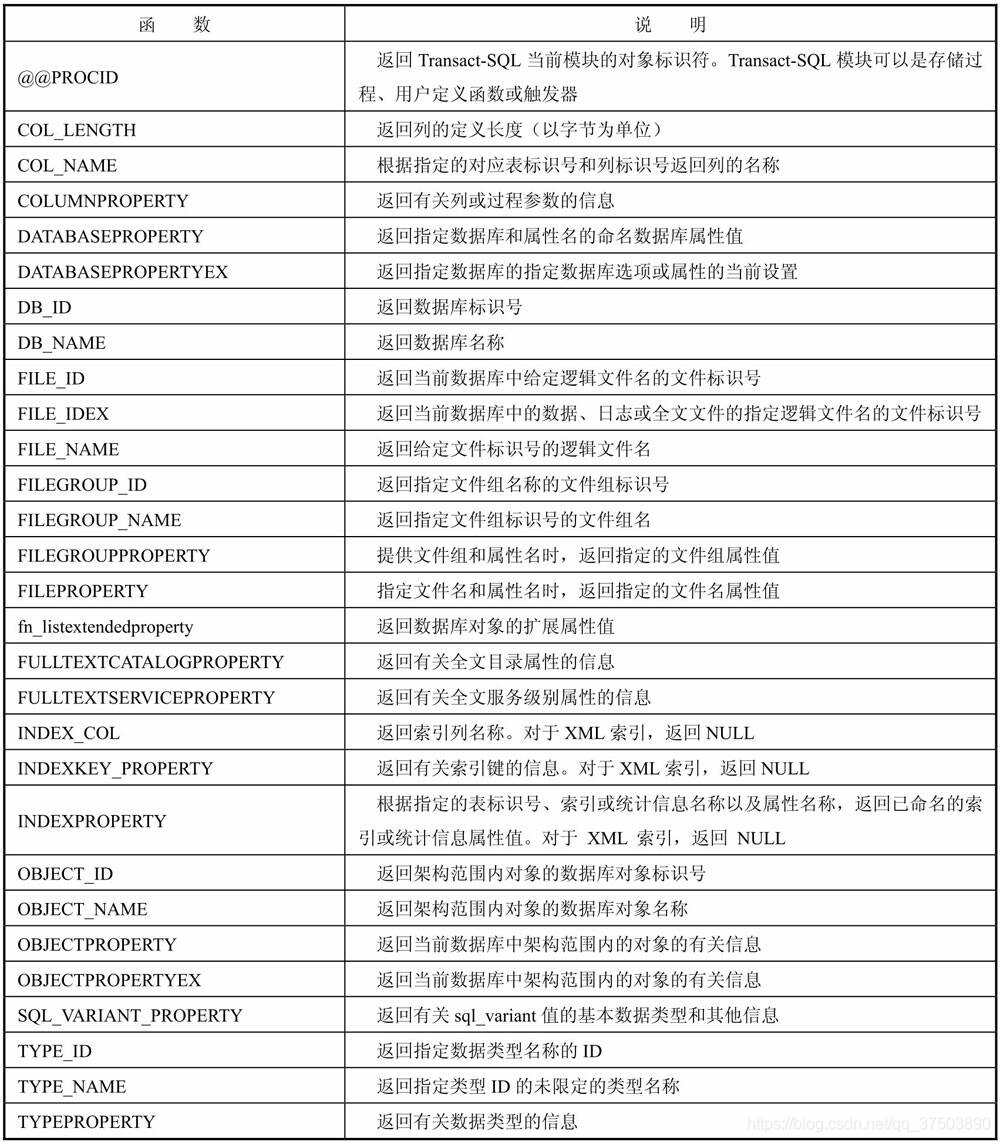
(5)安全函数:返回有关用户和角色的信息。
常用的安全函数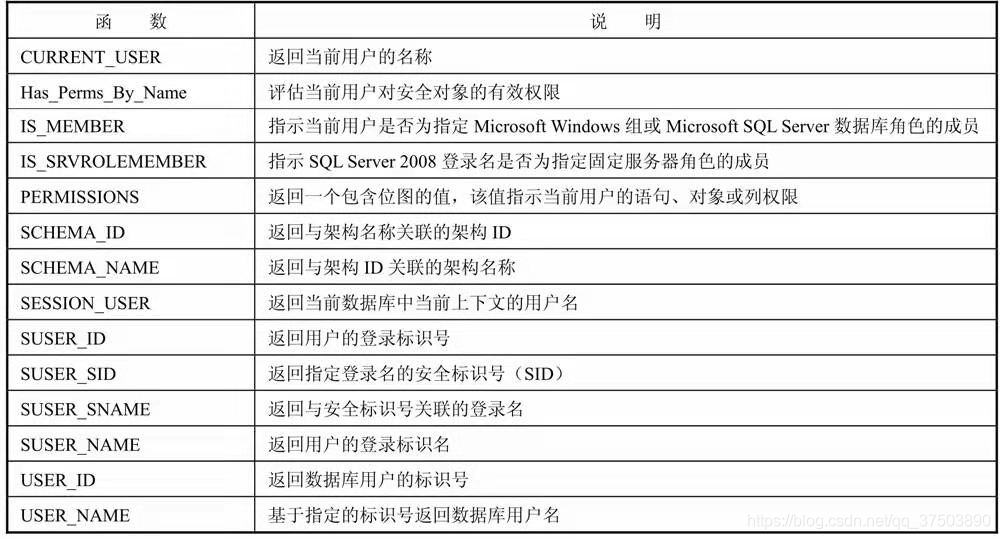
(6)常用的系统函数
常用的系统函数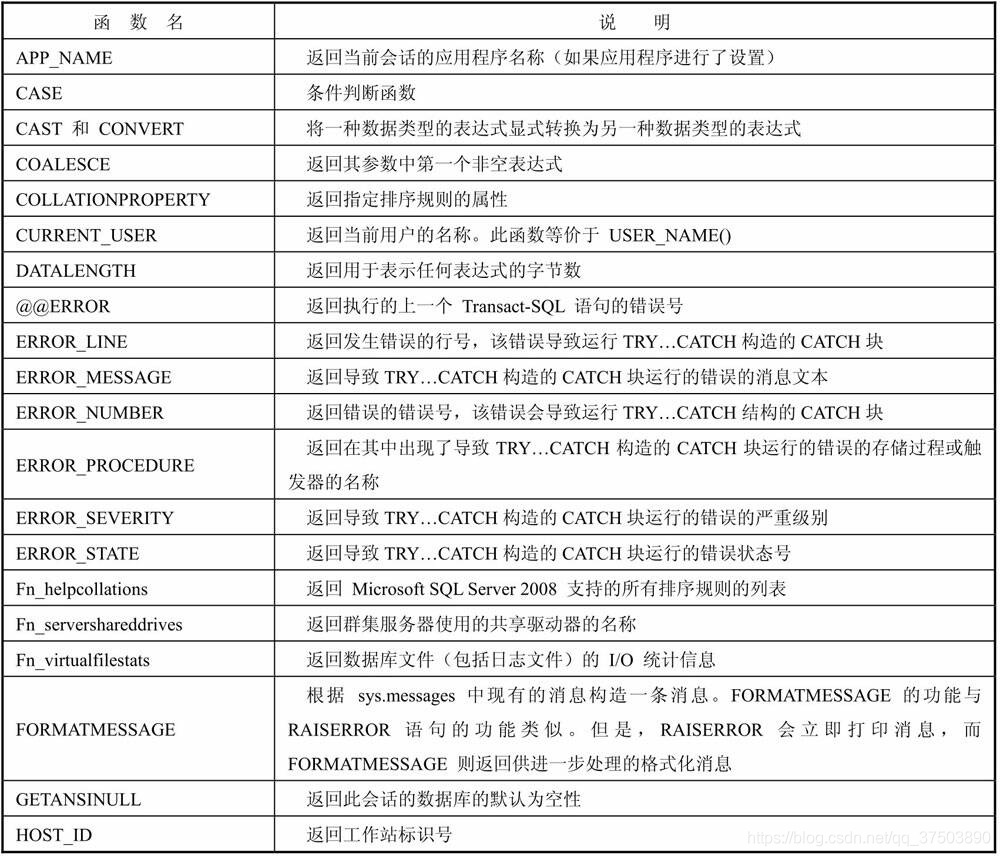
SQL Server中的ISNULL函数可以将NULL值更改为其他值,其语法如下所示。
ISNULL (check_expression , replacement_value )
● check_expression:将被检查是否为NULL值的表达式。check_expression可以是任何类型的。
● replacement_value:当check_expression为NULL值时将返回该表达式。replacement_value必须与check_expresssion具有相同的数据类型。
【例15】使用ISNULL函数。假设有一个数据表TestNull。
其创建语句和插入语句分别如下所示。
CREATE TABLE testnull
(
c1 int,
c2 int
);
INSERT INTO testnull
VALUES (10,NULL);
INSERT INTO testnull
VALUES (20,200);
INSERT INTO testnull
VALUES (NULL,NULL);
下面的语句将C2字段的所有NULL值显示为0。
SELECT c1, ISNULL(c2,0)
FROM testnull;注意:上面的查询语句并不能将C2字段的NULL值更改为0,而只是将NULL值显示为0。
(二) 分组查询
数据分组是指将数据表中的数据按照某种值分为很多组。例如,将STUINFO表中的数据用性别进行分组,会得到两组:所有男生为一组,所有女生为一组。数据分组使用GROUP BY子句,当然,如果想要将满足条件的分组查询出来,还需要HAVING子句的配合。
1、将表内容按列分组
(1)GROUP BY子句:用来对数据分组。分组是根据指定字段的不同值划分的。
【例16】将STUINFO表中的数据,按所属专业字段分组。
SELECT STUMAJOR
FROM STUINFO
GROUP BY STUMAJOR技巧:前面讲过去除相同值,需要使用DISTINCT关键字。但是,使用DISTINCT会严重降低查询效率,为此,使用GROUP BY子句代替DISTINCT是一种非常好的解决方案。
这里需要说明的一点是,如果将上面的SELECT子句字段列表中的“所属院系”改为星号(*),则会产生一系列的错误。
SELECT *
FROM STUINFO
GROUP BY STUMAJOR
通过错误提示可以得到如下启示,如果查询语句带有GROUP BY子句,则:
● SELECT子句中通常不单独使用星号通配符。如果非要单独使用星号通配符,则应当在GROUP BY子句中列出表的所有字段名,字段名之间用逗号分隔。不过这样会使GROUP BY子句失去它的作用。因为,此时并不是按单个字段分组,而是使用GROUP BY后列出的所有字段的组合分组。
● 如果SELECT子句后是字段名列表,而这些字段名又不在聚合函数中,则应当在GROUP BY子句中列出所有这些字段名。此时,需要注意的还有,分组是按GROUP BY后的所有字段的组合分组,而并非是按单个字段分组。例如,“GROUP BY depart,sname”表示只有某几个记录中的所属院系和姓名都相同时才把这些记录分为一组。
2、 聚合函数与分组配合使用
【例17】统计STUINFO表中男生的总人数和女生的总人数。
SELECT STUSEX,COUNT(*)
FROM STUINFO
GROUP BY STUSEX
【例18】统计STUINFO表中每个专业的女生人数。
SELECT STUMAJOR,COUNT(*) AS 女生人数
FROM STUINFO
WHERE STUSEX = '女'
GROUP BY STUMAJOR3、 查询数据的直方图
直方图是表示不同实体之间数据相对分布的条状图。在一个查询语句中使用GROUP BY子句,不仅可以查询数据,而且可以格式化数据生成图表。
【例19】从STUINFO表中,查询一个表示每个专业学生人数的直方图。
SELECT STUMAJOR,
REPLICATE('=',COUNT(*)*5) AS 人数对比图
FROM STUINFO
GROUP BY STUMAJOR
REPLICATE函数是SQL Server的字符函数。作用是以指定的次数重复字符表达式。本例中,它以人数5倍为次数,重复了等号(=)。这里使用人数的5倍是为了让图表更明显一些,如果人数非常多,图表很大,可以用某个常量除人数,例如COUNT(*)/5等。
4、 排序分组结果
如果想排序分组结果,则应当使用ORDER BY子句。ORDER BY子句要放在GROUP BY子句的后面。实际上,ORDER BY子句永远要放在其他子句的后面。
【例20】在STUINFO表中统计每个专业的学生人数,并按学生人数降序排序。
SELECT STUMAJOR,COUNT(*)
FROM STUINFO
GROUP BY STUMAJOR
ORDER BY COUNT(*) DESC
5、 反转查询结果
【例21】从STUINFO表中查询每个专业的男生人数和女生人数。
SELECT STUMAJOR,STUSEX,COUNT(*) AS 人数
FROM STUINFO
GROUP BY STUMAJOR, STUSEX
ORDER BY STUMAJOR上面的查询结果虽然将统计数据查询了出来,但还不够完美。这里由于表中的数据表较少,还看不出太明显的效果,如果要查询出每一个专业中男生是多少人、女生是多少人,在学习SQL语句时要学会灵活运用,CASE表达式和GROUP BY子句联合使用会得到很多有用的数据表示,其中就包括反转查询结果的数据表示,具体语句如下。
SELECT STUMAJOR,
COUNT(CASE
WHEN STUSEX='男' THEN 1
ELSE NULL
END) AS 男生人数,
COUNT(CASE
WHEN STUSEX ='女' THEN 1
ELSE NULL
END) AS 女生人数
FROM STUINFO
GROUP BY STUMAJOR
这样就巧妙地利用了COUNT函数忽略NULL值的规则,将数据反转了过来。
6、 使用HAVING子句设置分组查询条件
查看想要的分组的统计信息,而并不是所有分组的统计信息。
HAVING子句用于设置分组查询条件,即过滤不需要的分组。该子句通常和GROUP BY子句一起使用。单独使用HAVING子句没有太大的意义。
【例22】在STUINFO表中统计计算机专业和会计专业的学生人数,并按学生人数降序排序。
SELECT STUMAJOR,COUNT(*) AS 人数
FROM STUINFO
GROUP BY STUMAJOR
HAVING STUMAJOR IN('计算机','会计')
ORDER BY COUNT(*)
当然,本例也可以用WHERE子句代替HAVING子句:
SELECT STUMAJOR,COUNT(*) AS 人数
FROM STUINFO
WHERE STUMAJOR IN('计算机','会计')
GROUP BY STUMAJOR
ORDER BY COUNT(*)注意:HAVING子句与WHERE子句之后都写条件表达式,而且都会根据条件表达式的结果筛选数据。但它们是有区别的,主要区别如下。
(1)HAVING子句用于筛选组,而WHERE子句用于筛选记录。
(2)HAVING子句中可以使用聚合函数,而WHERE子句中不能使用聚合函数。
(3)HAVING子句中不能出现既不被GROUP BY子句包含,又不被聚合函数包含的字段。而WHERE子句中可以出现任意字段。通常,HAVING子句总是和GROUP BY子句配合使用的,而WHERE子句可以不用任何子句的配合。