一 HBase 缓存简介
HBase提供了2种类型的缓存结构:MemStore & BlockCache。其中
MemStore是写缓存,BlockCache是读缓存。
MemStore: HBase写数据首先写入MemStore之中,并同时写入HLog,待满足一定条件后将MemStore中数据刷到磁盘,可以很大提升HBase的写性能。而且对读也很有提升,如果没有MemStore,读取刚写入的数据需要从文件中通过I/O查找。
BlockCache: HBase会将一次文件查找的Block块缓存到Cache中,以便后续同一请求或者相邻数据查找请求,可以直接从内存中获取,避免昂贵的IO操作。一个HRegionServer只有一个BlockCache,在H
RegionServer启动的时候完成BlockCache的初始化,常用的BlockCache包括LruBlockCache,以及 CombinedBlockCache(Lru
BlockCache + BucketCache)
二 LRUBlockCache
LRUBlockCache 是HBase默认的BlockCache实现方案。实际上就是一个ConcurrentHashMap管理BlockKey到Block的映射关系,缓存Block只需要将BlockKey和对应的Block放入该HashMap中,查询缓存就根据BlockKey从HashMap中获取即可。
2.1 LRUBlockCache 分层策略
Block的数据存储在JVM 堆中,由JVM进行管理。它在逻辑上分为三个区:Single-Access、Multi-Access、In-Memory,分别占整个BlockCache的25%、50%、25%。一次随机读中,一个Block块从HDFS中加载出来之后首先放入Single-Access区,后续如果有多次请求访问到这块数据的话,就会将这块数据移到Multi-Access s区。而In-Memory区表示数据可以常驻内存,一般用来存放访问频繁、数据量小的数据,比如元数据,用户也可以在建表的时候通过设置列族属性IN-MEMORY= true将此列族放入In-Memory区。因此设置数据属性InMemory= true需要非常谨慎,确保此列族数据量很小且访问频繁,否则有可能会将hbase.meta元数据挤出内存,严重影响所有业务性能
这种设计策略类似于JVM中young区、old区以及perm区。无论哪个区,系统都会采用严格的Least-Recently-Used算法,当BlockCache总量达到一定阈值之后就会启动淘汰机制,最少使用的Block会被置换出来,为新加载的Block预留空间。
2.2 LRU淘汰算法实现
系统在每次cache block时将BlockKey和Block放入HashMap后都会检查BlockCache总量是否达到阈值,如果达到阈值,就会唤醒淘汰线程对Map中的Block进行淘汰。
系统设置三个MinMaxPriorityQueue队列,分别对应上述三个分层,每个队列中的元素按照最近最少被使用排列,系统会优先poll出最近最少使用的元素,将其对应的内存释放。可见,三个分层中的Block会分别执行LRU淘汰算法进行淘汰。
2.3 LRUBlockCache的优缺点
优点: LRU方案使用JVM提供的HashMap管理缓存,简单有效。
缺点: 随着热点数据从Single-Access到Multi-Access区,那么这些数据在Single-Access就变成了垃圾数据,相当于内存对象从young区到old区 ,晋升到old区的Block被淘汰后会变为内存垃圾,最终由CMS回收掉,然而这种算法会带来大量的内存碎片,碎片空间一直累计就会产生臭名昭著的Full GC。尤其在大内存条件下,一次Full GC很可能会持续较长时间,甚至达到分钟级别。大家知道Full GC是会将整个进程暂停的。因此长时间Full GC必然会极大影响业务的正常读写请求
三 CombinedBlockCache
CombinedBlockCache是一个LRUBlockCache和BucketCache的混合体。BucketCache是阿里贡献的。LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。因此一次随机读需要首先在LRUBlockCache中查到对应的Index Block,然后再到BucketCache查找对应数据块
BucketCache可以有三种工作模式:heap、offheap、file。heap模式表示这些Bucket是从JVM Heap中申请,offheap模式使用DirectByteBuffer技术实现堆外内存存储管理,而file模式使用类似SSD的高速缓存文件存储数据块。
无论在哪一种工作模式下,BucketCache都会申请许多带有固定大小标签的Bucket,一种Bucket只是一种指定的BlockSize的数据块,初始化的时候申请14个不同大小的Bucket,而且即使在某一种Bucket空间不足的情况下,系统也会从其他Bucket空间借用内存使用,不会出现内存使用率低下的情况。
3.1 BucketCache内存组织形式
HBase在启动的时候,会在内存申请大量的bucket,每一个bucket默认大小是2MB,每一个Bucket都有一个offsetBase属性和size标签,其中offsetBase表示这个bucket在实际物理空间的offset, 所以我们可以根据offsetBase的属性,和block在该bucket的offset确定block实际物理存储地址;size标签表示这个bucket可以存放的block块的大小,比如size 标签是9k, 那么他只能存储8k的block,如果size标签是129k,那么bucket只能存储128k的block,如图示:
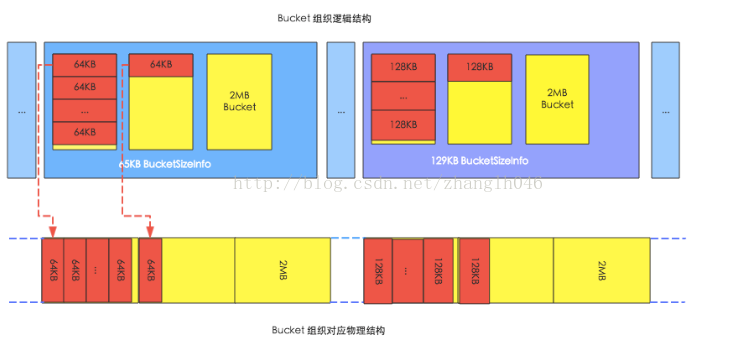
HBase使用BucketAllocator对bucket进行管理, HBase会根据size进行分组,相同size的标签由同一个BucketSizeInfo来管理,如64k的block的由size 标签是65k的BucketSizeInfo来管理, 如128k的block的由size 标签是129k的BucketSizeInfo来管理。
默认标签有(4+1)K、(8+1)K、(16+1)K … (48+1)K、(56+1)K、(64+1)K、(96+1)K … (512+1)K,而且系统会首先从小到大遍历一次所有size标签,为每种size标签分配一个bucket,最后所有剩余的bucket都分配最大的size标签,默认分配 (512+1)K,如下图所示:
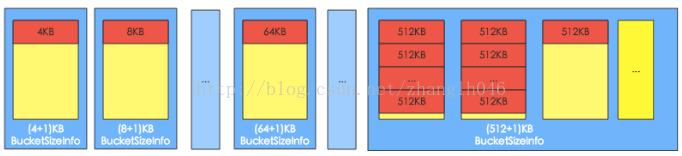
bucket size标签,可以动态调整。比如64K的block数目比较多,65K的bucket被用完了以后,其他size标签的完全空闲的bucket可以转换成为65K的bucket,但是至少保留一个该size的bucket。
3.2 Block缓存写入和读取流程
Map<BlockCacheKey, RAMQueueEntry> ramCache: 存储Block Key和Block对应关系的一个Map
WriteThread: 负责异步写入block到内存空间
BucketAllocator:主要实现对bucket的组织管理,为block分配内存空间
IOEngine:负责存储和读取block data
Map<BlockCacheKey, BucketEntry> backingMap: 存储block的元数据,诸如offset,length等,比如根据block key找到对应的内存地址偏移量
写流程图:

# 将block写入RAMCache。实际实现中,HBase设置了多个RAMCache,系统首先会根据blockkey进行hash,根据hash结果将block分配到对应的RAMCache中
# WriteThead从RAMCache中取出所有的block。和RAMCache相同,HBase会同时启动多个WriteThead并发的执行异步写入,每个WriteThead对应一个RAMCache;
# 每个WriteThead会将遍历RAMCache中所有block数据,分别调用bucketAllocator为这些block分配内存空间
# BucketAllocator会选择与block大小对应的bucket进行存放,并且返回对应的物理地址偏移量offset
# WriteThead将block以及分配好的物理地址偏移量传给IOEngine模块,执行具体的内存写入操作
# 写入成功后,将类似<blockkey,offset>这样的映射关系写入BackingMap中,方便后续查找时根据blockkey可以直接定位
读流程图:

# 首先从RAMCache中查找。对于还没有来得及写入到bucket的缓存block,一定存储在RAMCache中
# 如果在RAMCache中没有找到,再在BackingMap中根据blockKey找到对应物理偏移地址offset
# 根据物理偏移地址offset可以直接从内存中查找对应的block数据
3.3 BucketCache工作模式
BucketCache默认有三种工作模式:heap、offheap和file。这三种工作模式在内存逻辑组织形式以及缓存流程上都是相同的,但是对应的最终存储介质不一样,也可以说对应的IOEngine不一样。
其中heap 和 offheap都是用内存作为最终存储介质,内存分配查询也都使用Java NIO ByteBuffer技术。
heap模式分配内存调用的是ByteBuffer.allocate方法,从JVM提供的heap区分配
offheap调用的是ByteBuffer.allocateDirect()方法,直接从操作系统分配。
这两种内存分配模式会对HBase性能产生一定影响,最大的是GC,和heap相比,offheap模式因为内存属于操作系统,所以基本不会产生CMS GC,也就在任何情况下都不会因为内存碎片导致触发Full GC
除此之外,在内存分配以及读取方面,两者性能也有不同,比如内存分配时heap模式需要先从操作系统分了配内存然后再拷贝到JVM Heap,相比offheap直接从操作系统分配内存更耗时;但是反过来
读取缓存是heap模式可以直接从JVM读取,而offheap需要首先从操作系统拷贝JVM heap在读取,后者显得更耗时
file模式和前面两者不同,它使用Fussion-IO或者SSD等作为存储介质,相比昂贵的内存,这样可以提供更大的存储容量,因此可以极大提升缓存命中
3.4 BucketCache 配置
heap模式
<hbase.bucketcache.ioengine>heap</hbase.bucketcache.ioengine>
//bucketcache占用整个jvm内存大小的比例
<hbase.bucketcache.size>0.4</hbase.bucketcache.size>
//bucketcache在combinedcache中的占比
<hbase.bucketcache.combinedcache.percentage>0.9</hbase.bucketcache.combinedcache.percentage>
offheap模式
<hbase.bucketcache.ioengine>offheap</hbase.bucketcache.ioengine>
<hbase.bucketcache.size>0.4</hbase.bucketcache.size>
<hbase.bucketcache.combinedcache.percentage>0.9</hbase.bucketcache.combinedcache.percentage>
file模式
<hbase.bucketcache.ioengine>file:/cache_path</hbase.bucketcache.ioengine>
//bucketcache缓存空间大小,单位为MB
<hbase.bucketcache.size>10 *1024</hbase.bucketcache.size>
//高速缓存路径
<hbase.bucketcache.persistent.path>file:/cache_path</hbase.bucketcache.persistent.path>
四 缓存方案的选择
在缓存全部命中场景下,LRUBlockCache可谓完胜CombinedBlockCache。因此如果总数据量相比JVM内存容量很小的时候,选择LRUBlockCache
在所有其他存在缓存未命中情况的场景下,LRUBlockCache的GC性能几乎只有CombinedBlockCache的1/3,而吞吐量、读写延迟、IO、CPU等指标两者基本相当,因此建议选择CombinedBlockCache。
之所以在缓存全部命中场景下LRUBlockCache的各项指标完胜CombinedBlockCache,而在缓存大量未命中的场景下,LRUBlockCache各项指标与CombinedBlockCache基本相当,是因为HBase在读取数据的时候,如果都缓存命中的话,对于CombinedBlockCache,需要将堆外内存先拷贝到JVM内,然后再返回给用户,流程比LRU君的堆内内存复杂,延迟就会更高。而如果大量缓存未命中,内存操作就会占比很小,延迟瓶颈主要在于IO,使得LRUBlockCache和CombinedBlockCache两者各项指标基本相当。
一句话:
强烈建议线上配置BucketCache模式。可能很多童鞋都测试过这两种模式下的GC、吞吐量、读写延迟等指标,看到测试结果都会很疑惑,BucketCache模式下的各项性能指标都比LruBlockCache差了好多,笔者也疑惑过,后来才明白:测试肯定是在基本全内存场景下进行的,这种情况下确实会是如此。但是话又说回来,在大数据场景下又有多少业务会是全内存操作呢?