前言
I/O多路复用有很多种实现。在linux上,2.4内核前主要是select和poll,自Linux 2.6内核正式引入epoll以来,epoll已经成为了目前实现高性能网络服务器的必备技术。尽管他们的使用方法不尽相同,但是本质上却没有什么区别。本文将重点探讨将放在EPOLL的实现与使用详解。
为什么会是EPOLL
select的缺陷
 View Code
View Code
图 1.主流I/O复用机制的benchmark

epoll高效的奥秘
epoll精巧的使用了3个方法来实现select方法要做的事:
- 新建epoll描述符==epoll_create()
- epoll_ctrl(epoll描述符,添加或者删除所有待监控的连接)
- 返回的活跃连接 ==epoll_wait( epoll描述符 )
要深刻理解epoll,首先得了解epoll的三大关键要素:mmap、红黑树、链表。
epoll是通过内核与用户空间mmap同一块内存实现的。mmap将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址(不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理地址),使得这块物理内存对内核和对用户均可见,减少用户态和内核态之间的数据交换。内核可以直接看到epoll监听的句柄,效率高。
红黑树将存储epoll所监听的套接字。上面mmap出来的内存如何保存epoll所监听的套接字,必然也得有一套数据结构,epoll在实现上采用红黑树去存储所有套接字,当添加或者删除一个套接字时(epoll_ctl),都在红黑树上去处理,红黑树本身插入和删除性能比较好,时间复杂度O(logN)。
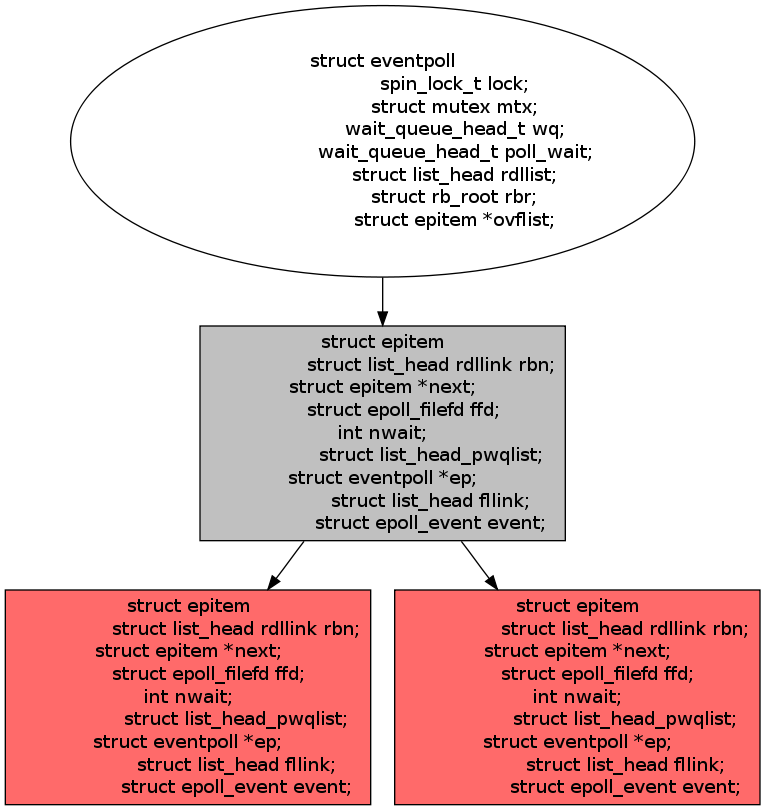
下面几个关键数据结构的定义
View Code
View Code
添加以及返回事件
通过epoll_ctl函数添加进来的事件都会被放在红黑树的某个节点内,所以,重复添加是没有用的。当把事件添加进来的时候时候会完成关键的一步,那就是该事件都会与相应的设备(网卡)驱动程序建立回调关系,当相应的事件发生后,就会调用这个回调函数,该回调函数在内核中被称为:ep_poll_callback,这个回调函数其实就所把这个事件添加到rdllist这个双向链表中。一旦有事件发生,epoll就会将该事件添加到双向链表中。那么当我们调用epoll_wait时,epoll_wait只需要检查rdlist双向链表中是否有存在注册的事件,效率非常可观。这里也需要将发生了的事件复制到用户态内存中即可。


epoll_wait的工作流程:
- epoll_wait调用ep_poll,当rdlist为空(无就绪fd)时挂起当前进程,直到rdlist不空时进程才被唤醒。
- 文件fd状态改变(buffer由不可读变为可读或由不可写变为可写),导致相应fd上的回调函数ep_poll_callback()被调用。
- ep_poll_callback将相应fd对应epitem加入rdlist,导致rdlist不空,进程被唤醒,epoll_wait得以继续执行。
- ep_events_transfer函数将rdlist中的epitem拷贝到txlist中,并将rdlist清空。
- ep_send_events函数(很关键),它扫描txlist中的每个epitem,调用其关联fd对用的poll方法。此时对poll的调用仅仅是取得fd上较新的events(防止之前events被更新),之后将取得的events和相应的fd发送到用户空间(封装在struct epoll_event,从epoll_wait返回)。
小结
表 1. select、poll和epoll三种I/O复用模式的比较( 摘录自《linux高性能服务器编程》)
| 系统调用 |
select |
poll |
epoll |
| 事件集合 |
用哦过户通过3个参数分别传入感兴趣的可读,可写及异常等事件 内核通过对这些参数的在线修改来反馈其中的就绪事件 这使得用户每次调用select都要重置这3个参数 |
统一处理所有事件类型,因此只需要一个事件集参数。 用户通过pollfd.events传入感兴趣的事件,内核通过 修改pollfd.revents反馈其中就绪的事件 |
内核通过一个事件表直接管理用户感兴趣的所有事件。 因此每次调用epoll_wait时,无需反复传入用户感兴趣 的事件。epoll_wait系统调用的参数events仅用来反馈就绪的事件 |
| 应用程序索引就绪文件 描述符的时间复杂度 |
O(n) |
O(n) |
O(1) |
| 最大支持文件描述符数 |
一般有最大值限制 |
65535 |
65535 |
| 工作模式 |
LT |
LT |
支持ET高效模式 |
| 内核实现和工作效率 | 采用轮询方式检测就绪事件,时间复杂度:O(n) | 采用轮询方式检测就绪事件,时间复杂度:O(n) |
采用回调方式检测就绪事件,时间复杂度:O(1) |
行文至此,想必各位都应该已经明了为什么epoll会成为Linux平台下实现高性能网络服务器的首选I/O复用调用。
需要注意的是:epoll并不是在所有的应用场景都会比select和poll高很多。尤其是当活动连接比较多的时候,回调函数被触发得过于频繁的时候,epoll的效率也会受到显著影响!所以,epoll特别适用于连接数量多,但活动连接较少的情况。
LT与ET模式
在这里,笔者强烈推荐《彻底学会使用epoll》系列博文,这是笔者看过的,对epoll的ET和LT模式讲解最为详尽和易懂的博文。下面的实例均来自该系列博文。限于篇幅原因,很多关键的细节,不能完全摘录。
原文连接 https://www.cnblogs.com/lojunren/p/3856290.html