1、数据仓库
数据仓库是数据库的清理和集成,是新型决策管理信息系统的解决方案。
区分OLTP和OLAP:OLTP是联机事务处理,侧重于事务的实时处理,如CUD操作,由数据库辅助完成;OLAP是联机分析处理,支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,快速灵活的处理数据,直观易懂的查询数据结果。
数据仓库一般包括:数据层、应用层(分析、处理、挖掘)、表现层
下面是OLAP的大致过程:

2、·Hive数据仓库
1)功能
ETL功能
数据存储管理
对大数据的查询和分析
2)特点
延时高、高扩展性(自适应机器的数量和数据量的变化)
无数据排序和查询cache功能
不支持在线事务处理
不提供实时的查询和记录更新
良好的容错性
3)数据结构
内部表:hive的存储是建立在hadoop文件系统上,一个表对应一个文件目录,内部表是建立在默认设置的目录中,删除内部表时元数据和数据本身都删除
外部表:外部表的数据不存储在默认设置的目录中,删除外部表时只是删除了元数据,数据本身没有删除
分区:一个分区对应一个目录
桶:根据哈希值切分数据,使每个桶对应一个文件
4)体系结构
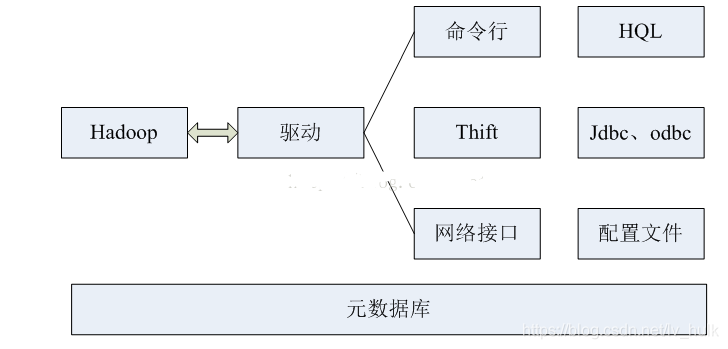
5)执行原理
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译优化以及查询计划生成------查询计划进入HDFS-----MapReduce执行
6)区别于数据库
数据库可以在线应用,hive是数据仓库;
查询语言为HQL类似SQL
数据存储位置:在hdfs中,数据库是在块设备或本地文件系统
数据格式:无专门的数据格式默认textFile/sequenceFile/rcfile
数据跟新:不支持改写和添加
索引:无索引,mapreduce全盘扫描
执行:mapreduce执行
执行的延迟高
可扩展性强,数据规模大
7)常见的应用场景:
主要是用在数据分析系统,大量数据的离线处理;
日志分析
多维度数据分析
低成本的处理,不编写MR程序,从数据导入、分析、结果输出都由HQL完成
关系数据库-------sqoop----Hive-----Hive数据分析-----sqoop-----关系型数据库