版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_43435675/article/details/88380455
0.检查tensorflow环境
import tensorflow as tf
hello = tf.constant('hello world')
session = tf.Session()
session.run(hello)
运行结果:
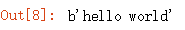
1.准备数据
import numpy as np
X = np.linspace(-1, 1, 300)[:, np.newaxis].astype('float32')#变量a为1维的ndarray对象时,a[:, np.newaxis]与a.reshape(-1, 1)相同。-1代表可以随便取。np.linspace(-1, 1, 300)表示-1到1等间距点取300个。
noise = np.random.normal(0, 0.05, X.shape).astype('float32')#np.random.normal方法初始化符合正态分布的点,第1个参数是正态分布的均值,第2个参数是正态分布的方差,第3个参数是返回值的shape,返回值的数据类型为ndarray对象。
y = np.square(X) - 0.5 + noise#np.square方法对X中的每一个值求平方,- 0.5使用了ndarray对象的广播特性,最后加上噪声noise,将计算结果赋值给变量y。
2.搭建神经网络
import tensorflow as tf
Weights_1 = tf.Variable(tf.random_normal([1, 10]))#定义Weights,它的形状是连接上一层神经元的个数*连接下一层神经元的个数。
biases_1 = tf.Variable(tf.zeros([1, 10]) + 0.1)#定义biases,它是二维矩阵,行数一直为1,列数为连接下一层神经元的个数,即它的形状为1*连接下一层神经元的个数;
Wx_plus_b_1 = tf.matmul(X, Weights_1) + biases_1#表示wx+b的计算结果
outputs_1 = tf.nn.relu(Wx_plus_b_1)#表示在第1个连接的输出结果,经过激活函数relu得出
#上面4行定义神经网络中的输入层到第1隐层的连接
Weights_2 = tf.Variable(tf.random_normal([10, 1]))
biases_2 = tf.Variable(tf.zeros([1, 1]) + 0.1)
Wx_plus_b_2 = tf.matmul(outputs_1, Weights_2) + biases_2
outputs_2 = Wx_plus_b_2#表示在第2个连接的输出结果,因为此连接的下一层是输出层,所以不需要激活函数
#上面4行定义神经网络中的第1隐层到输出层的连接
loss = tf.reduce_mean(tf.square(y - outputs_2))#定义损失函数,等同于回归预测中的MSE,中文叫做均方误差
optimizer = tf.train.AdamOptimizer(0.1)#调用tf.train库中的AdamOptimizer方法实例化优化器对象
train = optimizer.minimize(loss)#调用优化器的minimize方法定义训练方式,参数为损失函数。方法的返回结果赋值给变量train
3.变量初始化
#对于神经网络模型,重要是其中的W、b这两个参数。开始神经网络模型训练之前,这两个变量需要初始化
init = tf.global_variables_initializer()#tf.global_variables_initializer实例化tensorflow中的Operation对象
session = tf.Session()#调用tf.Session方法实例化会话对象
session.run(init)#调用tf.Session对象的run方法做变量初始化
4.模型训练
#模型训练200次,每运行1次代码session.run(train)则模型训练1次。在训练次数为20的整数倍时,打印训练步数、loss值
for step in range(201):
session.run(train)
if step % 20 == 0:
print(step, 'loss:', session.run(loss))
运行结果:
0 loss: 0.040248208
20 loss: 0.011066726
40 loss: 0.004511993
60 loss: 0.0028382281
80 loss: 0.0026794705
100 loss: 0.0026217068
120 loss: 0.0026041507
140 loss: 0.0025921084
160 loss: 0.002581141
180 loss: 0.0025619685
200 loss: 0.0025474937

详细请参考:https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/