[2019BUAA软件工程]结对作业
写在前面
| Tips | Link |
|---|---|
| 作业链接 | [2019BUAA软件工程]结对作业 |
| GitHub地址 | WordChain |
Personal Software Process 记录
以下为对本次作业各部分用时的估计与实际使用情况:
| Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) | |
|---|---|---|---|
| Planning | Estimate | 20 | 20 |
| Total | 20 | 20 | |
| Development | Analysis | 60 | 60 |
| Design Spec | 60 | 50 | |
| Design Review | 40 | 40 | |
| Coding Standard | 20 | 15 | |
| Design | 120 | 300 | |
| Coding | 360 | 600 | |
| Code Review | 120 | 100 | |
| Test | 420 | 600 | |
| Total | 1200 | 1600 | |
| Reporting | Test Report | 90 | 120 |
| Size Measurement | 30 | 40 | |
| Postmortem & Process Improvement Plan | 30 | 40 | |
| Total | 180 | 200 | |
| Total | 1400 | 1820 | |
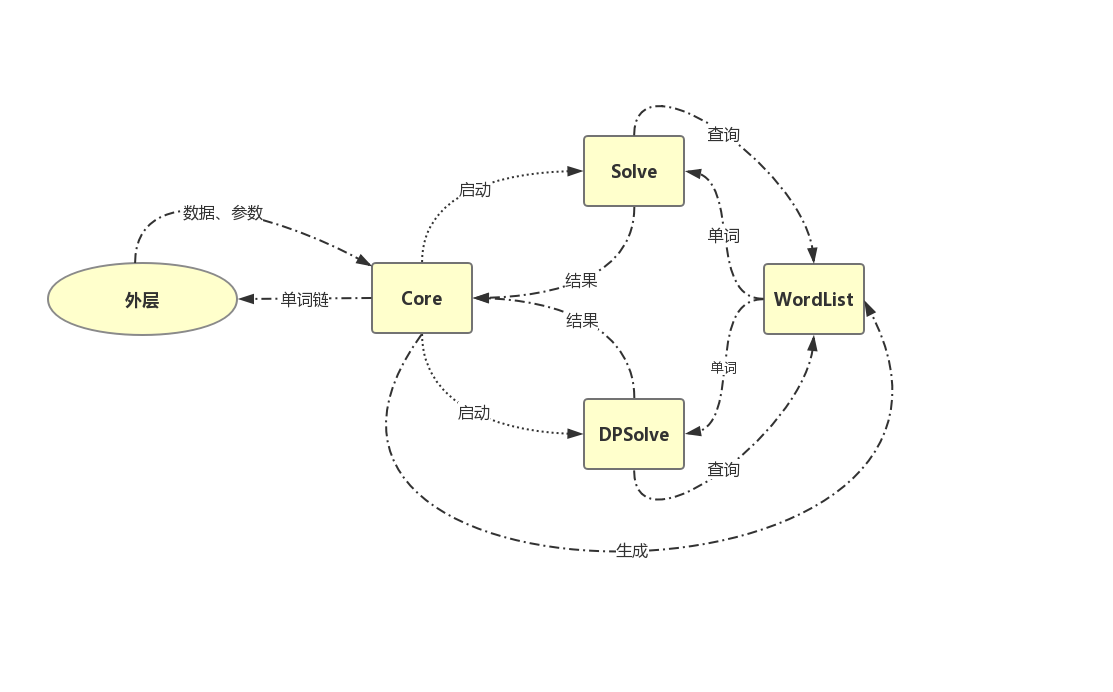
模块化设计思想
信息隐藏(Information Hiding)
In computer science, information hiding is the principle of segregation of the design decisions in a computer program that are most likely to change, thus protecting other parts of the program from extensive modification if the design decision is changed. The protection involves providing a stable interface which protects the remainder of the program from the implementation (the details that are most likely to change).
简而言之,信息隐藏就是在设计与实现模块时,限制其他模块对该模块内包含的特定信息的访问进行限制。满足信息隐藏的模块需要自行维护内部的数据结构和运算逻辑,并且要保证不会因为外部的操作而影响内部的所有逻辑结构的运行,使自身处于在可控制的范围,具有更高的稳定性。
对于整个计算模块Core,外层(控制台、GUI)无法对其中的数据结构进行操作,保证了计算模块与外层的信息隐藏。计算模块Core内部的数据类WordList和运算逻辑类Solve/DPSolve之间也存在信息隔离。数据类没有操作运算逻辑类的权限;运算逻辑类只能通过数据类提供的合法接口间接操作、获取数据。
接口设计(Interface Design)
Good user interface design facilitates finishing the task at hand without drawing unnecessary attention to itself.
对于模块接口的设计应当使外层只关注于模块虽提供的功能、接口的输入以及产生的效果,而非模块内层的实现逻辑。接口的作用体现在对代码进行修改的时候:在修改某一模块的内部逻辑时,只需保证对外接口不变就无需修改外层代码。合适的接口设计提高了工程的可重构性、可延展性,降低了维护的难度。
对于计算模块Core的接口,外层只需考虑输入计算的单词集合以及相应的运算模式参数就能够获得最终结果或者错误提示。对于数据类提供的接口,其他模块只需按照其需要获取的信息选择不同的接口函数并输入参数就能获取到搜索结果。
降低耦合(Loose Coupling)
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components. Subareas include the coupling of classes, interfaces, data, and services.Loose coupling is the opposite of tight coupling.
模块间的耦合度是指模块之间的依赖关系,包括控制关系、调用关系、数据传递关系。耦合的强弱取决于模块间接口的复杂性、调用模块的方式以及通过界面传送数据的多少。模块间联系越多,其耦合性越强,同时表明其独立性越差。
计算模块中的耦合主要体现在运算模块和单词数据存储模块。由于运算模块是基于单词数据模块构建的,运算模块的很多函数需要适应于单词模块提供的接口。运算模块依赖于单词模块是较难避免的。但单词模块对运算模块的依赖就较低。单词模块只需完成自身数据维护和提供查询接口即可,无需依赖其他模块。因而在计算模块中,单词模块的设计使其能复用给两个运算模块作为数据源。
计算模块接口的设计与实现过程
对外接口设计:
- 接口:
int gen_chain_word(char* words[], int len, char* output, char head, char tail, bool enable_loop);
int gen_chain_char(char* words[], int len, char* output, char head, char tail, bool enable_loop);- 参数解释:
- char* words[]:传入单词集合。
- char* output[]:输出单词链。
- int len:输入单词集合长度。
- char head:单词链首字母限制。无限制输入0,有限制则输入相应英文字符。
- char tail:单词链首字母限制。无限制输入0,有限制则输入相应英文字符。
- bool enable_loop:单词环限制。允许存在单词换为true,否则为false。
- 返回值:返回搜得最长单词链长度或错误码。
类功能设计:
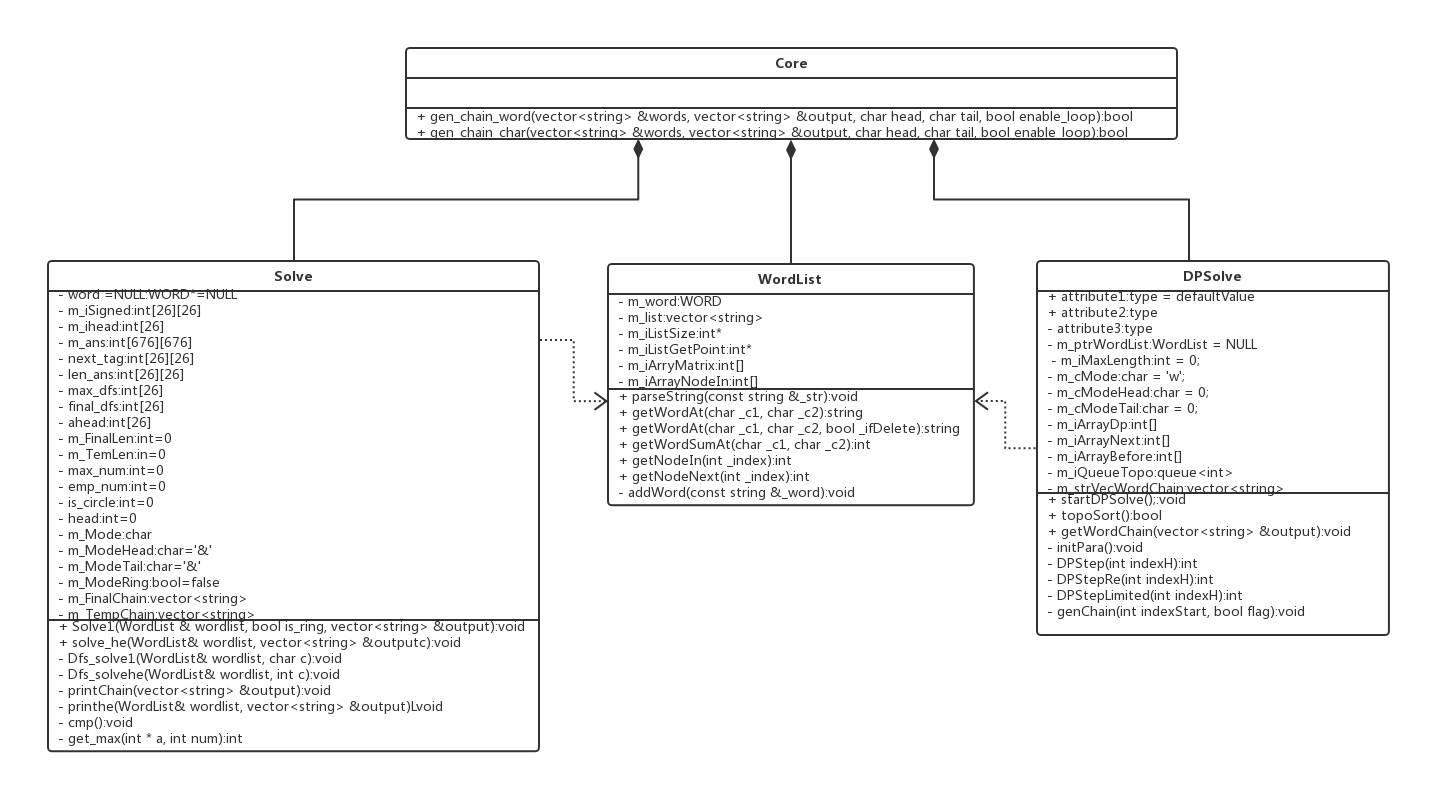
- Core:内外层交互类
- 实现计算模块与外层(Console或GUI模块)交互逻辑。
- 接收外层的原始数据和相应参数。
- 对接收到的原始数据进行预处理:
- 从原始数据中提取出单词。
- 过滤重复单词。
- 将有效单词按首尾字母归类,存入单词库中。
- 更新单词库中单词链接矩阵。
- 按照指定模式组织内层计算逻辑。
- 返回内层计算结果。
- Solve/DPSolve:核心计算类
- 实现对已有单词库搜索单词链的算法。
- 核心算法:优化BFS(有单词环)和动态规划(无单词环)。
- 辅助算法:拓扑排序(检查是否存在单词环)。
- WordList:数据类
- 格式化存储单词。
- 将单词链接关系组织为邻接矩阵。
- 提供相应的查询函数。
类流程关系
- Core获取原始数据与运行参数。
- Core预处理原始数据,生成单词库(WordList)。
- 按照参数启动Solve/DPSolve相应计算函数。
- 完成单词链搜索,Core输出计算结果。
类关键函数设计及实现
- Core:
- 关键函数:
- gen_chain_word():按单词数量搜索单词链时的对外接口。
- gen_chain_char():按单词长度搜索单词链时的对外接口。
- 关键函数:
- WordList:
- 存储结构设计思路:
- 单词表组织:
将消除重复后的单词按照首尾字母进行归类。比如:apple归类为ae类单词。为每一种类的单词建立数组存储,每个数组内的同种单词按照长度降序排列。对存储每一种类单词的数组按照HASH表存储至一维数组中。 - 辅助结构组织:
根据已经建立的单词表,将字母视为节点,单词视为由首字母结点指向尾字母的有向边,则能够将单词表组织为有向图。使用位图(BitMap)存储邻接矩阵,使用HASH数组存储各结点的入度。 - 类中的索引均采用HASH函数:Index = 首字母相对'a'偏移 * 26 + 尾字母相对'a'偏移
- 单词表组织:
- 成员变量:
- m_list:单词表,按照首尾字母的种类对单词进行分组储存,存储采用HASH结构,不存在重复单词,同种类单词按照长度由长至短排列。
- m_iListSize:单词表长度,存储不同首尾字母的单词数量。
- m_iListGetPoint:单词检索索引,存储已检索的单词的索引。
- m_iArryMatrix[]:单词链邻接矩阵。
- m_iArrayNodeIn[]:结点入度数组。
- 关键函数:
- parseString():
- 解析字符串,提取单词。
- 调用私有函数addWord添加单词。
- getWordAt():
- 获取符合首尾条件的单词。
- getWordSumAt():
- 获取符合首尾条件的单词总数量。
- getNodeIn():
- 获取单词链图某一首字母结点的入度。
- getNodeOut():
- 获取单词链图某一首字母结点的出度。
- getNodeNext():
- 获取单词链图某一首字母结点的邻接矩阵项。
- addWord():"private"
- 过滤重复单词,将有效单词添加至单词表相应分类。
- 保证添加后各分类内单词长度降序排列。
- parseString():
- 存储结构设计思路:
- Solve:
- 设计思路
使用深度优先搜索加剪枝策略,解决了头尾限定问题,以及属于单词序列中存在环时得问题。 - 成员变量:
- m_iSigned26: 标记两个字母之间的路径是否以及走过
- m_ihead[26]: 标记每个字母是否以及用过
- m_ans676: 记录单词是否使用的变量
- next_tag26: 储存字母邻接链表
- max_dfs[26]: 记录每个单词距离终点的最大距离
- final_dfs[26] 记录最终的每个字母节点距离其重点的距离
- m_FinalLen: 单词链最终长度
- m_TemLen: 搜索到的当前字符链的长度
- max_num: 单词链个数最大长度
- temp_num 搜索到的单词链表当前个数
- bool is_circle: 判断是否有环
- head: 确定头部字母记录下的头部字母
- char m_Mode: 记录搜索模式的变量
- char m_ModeHead: 记录搜索的时指定的头部
- char m_ModeTail: 记录搜索的时指定的尾部
- bool m_ModeRing: 记录搜索模式是否有环
- vector
m_FinalChain: 最终结果 - vector
m_TempChain: 当前路径
- 关键方法
- Solve1(): 解决允许有环时的搜索问题
- Solve2_he(): 解决无环时的指定头尾的搜索问题
- Dfs_solve1(): 解决允许有环时的搜索问题的搜索函数
- cmp(): 允许有环的时候对当前最大长度的更新函数
- printChain(): 允许有环的时候的输出函数
- Dfs_solvehe(): 指定头尾问题的搜索问题的递归搜索函数
- cmp_he(): 解决头尾指定问题时候 对当前最大长度进行更新的函数
- printhe(): 解决头尾指定问题时候 的输出问题
- 设计思路
- DPSolve:
- 实现思路:
- 使用动态规划解决无单词环情况下除同时限定单词链首尾的问题。根据限制条件的不同采取正向或逆向动态规划。
- 动态规划:
- 正向递推式:F(c1)=max{F(c1)+len(c1ci)}或F(c1)=max{F(c1)+len(c1ci)}
- 逆向递推式:f(c1)=max{f(c1)+len(cic1)}或f(c1)=max{f(c1)+len(cic1)}
- F(c)为由c开始的最长单词链长度。
- f(c)为以c结束的最长单词链长度。
- len(cicj)是以ci为首以cj为尾的最长单词长度。
- 单词环检测:
- 使用拓扑排序算法检测单词环,保证动态规划正确进行。
- 成员变量:
- m_ptrWordList:单词表指针。
- m_cMode:搜索模式,分为按数量和按程度。
- m_cModeHead:头部限定。
- m_cModeTail:尾部限定。
- m_iArrayDp[]:动态规划结果。
- m_iArrayNext[]:存储相应结点的最优后继结点。
- m_iArrayBefore[]:存储相应结点的最优前缀结点。
- m_iQueueTopo:拓扑排序结果。
- m_strVecWordChain:存储计算得到的单词链。
- 关键方法:
- DPSolve():构造函数,传入单词表和各种参数。
- startDPSolve():启动函数。
- topoSort():拓扑排序,检查单词表中是否有环。
- getWordChain():导出计算后的结果。
- DPStep(int indexH):正向动态规划子函数,私有函数。
- DPStepRe(int indexH):逆向动态规划子函数,私有函数。
- 实现思路:
UML设计
计算模块接口部分的性能改进
- 第一阶段:深度搜索实现基本功能
笔者在最初进行程序设计时采取的是使用简洁的方法先实现需求的所有功能,再根据实际运行情况优化算法。根据这样的初衷产生了如下的流程设计。
首先,将所有单词按照首尾字母进行分类。以字母为结点,以单词为有向边(由单词首字母结点指向尾字母节点),将单词表构造成图结构。如此组织单词表可以很好地对需求中的问题进行简化和抽象:无单词环时,很容易证明每个结点间最多单向经过一次。比如'a'、'b'两结点最多仅能有一个有向边。于是便可以将问题转化为在构造的图中搜索最长路径。对于‘-w’功能则是将边权重设置为‘1’;对于‘-c’功能则是将边权重设置为该边对应类型单词中最长的单词长度;而‘-t’和‘-h’功能则是增加了首尾节点的限制。而对于有单词环的情况,每个结点间可经过的方向及其次数等于其所对应种类的单词数量,运用深度搜索也同样能够解决相应的问题。
在搜索阶段,程序对每个节点进行深度搜索,搜索以该结点为首的最长路径,并根据不同的输入参数得出符合要求的单词链。最终通过接口完成结果的输出。
- 第二阶段:动态规划优化部分功能
笔者的小组在较短时间内就完成了基于深度搜索的单词链搜索程序。在通过正确性测试并进行性能测试后,不出意料的出现的运行效率低的问题。运行效率低的主要原因是原始深度遍历不具有记忆和预测功能。这会导致在进行多次遍历时会对以搜索的路径和明显不是最优解的路径进行遍历。会经过分析后,我们决定采取以下方案对程序进行优化。
对于无单词环并且不同时限定首尾的情况,废弃原先的方法转而采用动态规划的方法。这几个搜索最长单词链的问题可以分解为求解与其相连的字母的最长单词链加上两者间距离的最大值。比如正向动态规划时,求解以'a'为首的最长单词链,而'b'、'c'结点可以由'a'结点直接到达,则原问题的最优解为子问题'b'、'c'的最优解分别加上'a'到这些结点的边的权值。用公式表示为:
正向递推式:F(c1)=max{F(c1)+len(c1ci)}*或*F(c1)=max{F(c1)+len(c1ci)}
逆向递推式:f(c1)=max{f(c1)+len(cic1)}*或*f(c1)=max{f(c1)+len(cic1)}
在使用动态规划后,程序将无单词环并且不同时限定首尾的情况的计算压缩至了1s内,基本满足了要求。
- 第三阶段:优化深度搜索
在进行动态规划的优化之后,我们发现,动态规划虽然效率很高,但是并不能处理同时指定头和尾的问题,于是我们仿照动态规划表达式的思想,对于我们的深度优先搜索做了一步剪枝。具体的剪枝思想如下:
在搜索回退的时候,用一个数组,记录下每个字母距离其末尾的最大长度,或者最大单词个数,当第二次搜索到这个字母节点时,直接比较当前长度,当前节点距离末尾的最大长度,如果前者比后者小,直接剪掉这个分支。保证了每条边只搜索了一遍,极大的提高了深度优先搜索的效率。
- 性能测试:
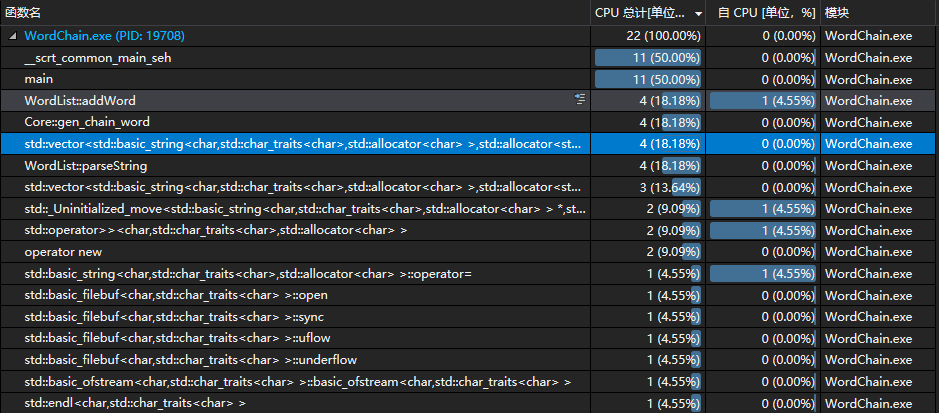
上图为在无单词环的情况下进行的约九千单词量的性能测试结果。由图可知,在进行vector操作上的消耗较多。消耗最多的代码是在addWord函数中将新单词加入至有序单词表的操作时采用了vector的insert函数。这一消耗仅出现在预处理的部分,在保证单词表中的单词是按照长度降序排列的同时还过滤了重复的单词。该操作虽然带来了一定的损耗,但是组织好的单词表更易于计算过程的检索,降低了检索的复杂度,防止递归导致的消耗的放大。计算过程采用的动态规划算法大大减小了该阶段的消耗。
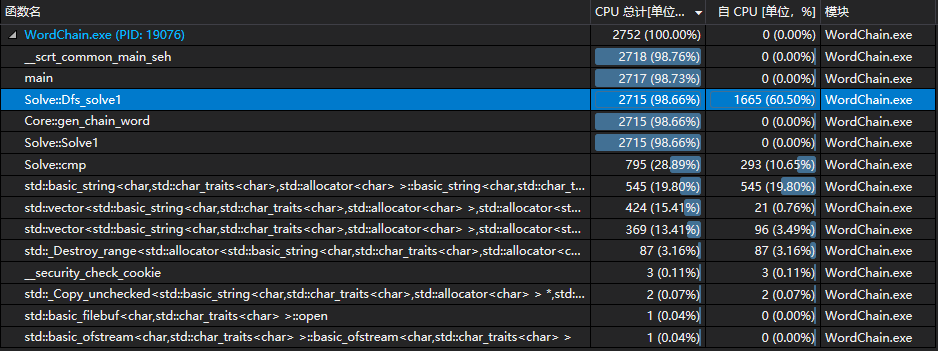
上图为在有单词环的情况下进行的性能测试。CPU的消耗主要出在递归调用的函数Dfs_solve1中。
契约式设计体现
契约式编程 & 防御式编程
提到契约式编程就不能不说防御式编程。在实现某一模块时,对于异常输入的处理一般有以下两种处理方式:
- 兼容处理所有情况,保证程序正确执行完成。
- 识别并抛出不符合要求的情况,告知外层找出错误原因。
前者就是防御是编程思想,后者就是契约式编程思想。契约式编程思想是在每个模块间建立明确的“责任”和“义务”关系。每个模块在使用其他模块的接口时都有责任保证使用的正确性,即符合接口的先验条件等;而在满足了先验条件的情况下,被调用模块有义务保证执行功能的正确性,即满足接口的后验条件和不变式等。契约的内容常体现于以下方面(来自维基百科):
- 可接受和不可接受的值或类型,以及它们的含义
- 返回的值或类型,以及它们的含义
- 可能出现的错误以及异常情况的值和类型,以及它们的含义
- 副作用
- 先验条件
- 后验条件
- 不变条件
- 性能上的保证,如所用的时间和空间
简析契约式编程:
- 优点:
- 简化代码
防御式编程需要在实现正常功能之余,为防御外来的不合法情况进行判断和处理,以保证功能的正常运行。因此需要在每个子功能内增加大量的代码。而契约式编程由于有先验条件,被调用者减少了处理的代码,使每个子功能的逻辑简洁而清晰,实现每个子功能代码的轻量化。 - 增强程序的健壮性
在一定程度上简化代码就能大大减小Bug的出现,尤其是防御代码的Bug。除此之外,契约能够明确地划分系统内各个部分职责,降低各模块的耦合程度,使程序有更好的鲁棒性和可维护性。
- 简化代码
- 缺点:
- 对契约完备性的要求高
在契约式编程带来好处的同时,其对契约的完备性的要求较高。当契约存在漏洞的时候,每个模块不能想防御式编程对异常情况进行兼容式处理,因而极易导致程序出现意想不到的状况。契约式编程的优点成立的前提是有一个完备的契约系统。 - 权责划分难度较大
理想的契约式编程中,调用者和被调用者应当是平等的:各自都有自身的权利和义务,并且模块的权责是均衡的。但在设计阶段对模块的权责进行划分时要保证均衡地为每个模块划分权责的难度较大。这需要对整个程序有较全面的考量,而非从局部功能来设计模块的契约。
- 对契约完备性的要求高
契约式编程的应用
- 单词表接口契约:
其他模块在调用单词表模块的接口使需要保证传入的参数在相应的范围内(先验条件)。在满足先验条件的情况下,单词表模块保证能返回正确的查询结果,同时不破坏现有的单词表。
计算模块部分单元测试展示
笔者对工程中Core类的正确性以及封装后的dll的正确性进行了测试
- Core类测试集
TEST_CLASS(TEST)
{
public:
Core *CORE = NULL;
TEST_METHOD_INITIALIZE(initEnv)
{
CORE = new Core();
}
TEST_METHOD_CLEANUP(cleanWordList)
{
delete CORE;
CORE = NULL;
}
TEST_METHOD(Test_1) // -w
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bd",
"cd",
};
string ans[] = {
"ab", "bc", "cd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for(int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 0, 0, false));
Assert::AreEqual(size_t(3), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
delete lines;
delete chain;
}
TEST_METHOD(Test_2) // -c
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bd",
"cd",
};
string ans[] = {
"accccccccccccccccccccc", "cd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 0, 0, false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_3) // -w -h
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
};
string ans[] = {
"bc", "cd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 'b', 0, false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_4) // -c -h
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
"dd",
};
string ans[] = {
"bdddd", "dd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 7; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 'b', 0, false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_5) // -w -t
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
};
string ans[] = {
"ab", "bc"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 0, 'c', false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_6) // -c -t
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
"cc"
};
string ans[] = {
"accccccccccccccccccccc", "cc"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 7; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 0, 'c', false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_7) // -w -h -t
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"be",
"cd",
"ce",
"de"
};
string ans[] = {
"bc", "cd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 10; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 'b', 'd', false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_8) // -c -h -t
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"be",
"cd",
"ce",
"de",
"dd",
};
string ans[] = {
"bdddd", "dd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 11; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 'b', 'd', false));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_9) // -w but have ring
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"db",
"be",
"cd",
"ce",
"de"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 11; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(-2, CORE->gen_chain_word(*lines, *chain, 0, 0, false));
delete lines;
delete chain;
}
TEST_METHOD(Test_10) // -c but have ring
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"db",
"be",
"cd",
"ce",
"de"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 11; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(-2, CORE->gen_chain_char(*lines, *chain, 0, 0, false));
delete lines;
delete chain;
}
TEST_METHOD(Test_11) // -w have self
{
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bb",
"bc",
"bdddd",
"be",
"cc",
"cd",
"ce",
"dd",
"de"
};
string ans[] = {
"ab", "bb", "bc", "cc", "cd", "dd", "de"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 13; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 0, 0, false));
Assert::AreEqual(size_t(7), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
Assert::AreEqual(ans[3], (*chain)[3]);
Assert::AreEqual(ans[4], (*chain)[4]);
Assert::AreEqual(ans[5], (*chain)[5]);
Assert::AreEqual(ans[6], (*chain)[6]);
delete lines;
delete chain;
}
TEST_METHOD(Test_12){ // -c have self
string words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bb",
"bc",
"bdddd",
"be",
"cc",
"cd",
"ce",
"dd",
"de"
};
string ans[] = {
"accccccccccccccccccccc", "cc", "cd", "dd", "de"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 13; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 0, 0, false));
Assert::AreEqual(size_t(5), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
Assert::AreEqual(ans[3], (*chain)[3]);
Assert::AreEqual(ans[4], (*chain)[4]);
delete lines;
delete chain;
}
TEST_METHOD(Test_13) // -w -r
{
string words[] = {
"ab", "aaaaabbbbbccccc", "aaaaaddddd",
"bc",
"cb", "cd",
};
string ans[] = {
"aaaaabbbbbccccc", "cb", "bc", "cd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 0, 0, true));
Assert::AreEqual(size_t(4), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
Assert::AreEqual(ans[3], (*chain)[3]);
delete lines;
delete chain;
}
TEST_METHOD(Test_14) { // -c -r
string words[] = {
"ab", "aaaccc", "aaaaabbbbbcccccddddd",
"bc",
"cb", "cd",
"dd",
};
string ans[] = {
"aaaaabbbbbcccccddddd", "dd"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 7; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 0, 0, true));
Assert::AreEqual(size_t(2), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
delete lines;
delete chain;
}
TEST_METHOD(Test_15) { // -w -r -h -t
string words[] = {
"ab",
"bccccccccccccccccccccccccccc", "bd",
"cd",
"da", "dc",
};
string ans[] = {
"bd", "dc", "cd", "da"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_word(*lines, *chain, 'b', 'a', true));
Assert::AreEqual(size_t(4), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
Assert::AreEqual(ans[3], (*chain)[3]);
delete lines;
delete chain;
}
TEST_METHOD(Test_16) { // -c -r -h
string words[] = {
"ab",
"bccccccccccccccccccccccccccc", "bd",
"cd",
"da", "dc",
};
string ans[] = {
"bccccccccccccccccccccccccccc","cd", "da"
};
vector<string> *lines = new vector<string>();
vector<string> *chain = new vector<string>();
for (int i = 0; i < 6; i++)
{
lines->push_back(words[i]);
}
Assert::AreEqual(0, CORE->gen_chain_char(*lines, *chain, 'b', 'a', true));
Assert::AreEqual(size_t(3), chain->size());
Assert::AreEqual(ans[0], (*chain)[0]);
Assert::AreEqual(ans[1], (*chain)[1]);
Assert::AreEqual(ans[2], (*chain)[2]);
delete lines;
delete chain;
}- 拓扑排序测试
TEST_METHOD(TEST_TopoSort_1)
{
string str_list[] = {
"aa", "abc" , "cbd", "ddd", "da"
};
for (int i = 0; i < 5; i++)
{
WORDLIST->parseString(str_list[i]);
}
dpSolve = new DPSolve(WORDLIST, 'w');
Assert::AreEqual(false, dpSolve->topoSort());
}
TEST_METHOD(TEST_TopoSort_2)
{
string str_list[] = {
"aa", "abc" , "cbd", "ddd", "db"
};
for (int i = 0; i < 5; i++)
{
WORDLIST->parseString(str_list[i]);
}
dpSolve = new DPSolve(WORDLIST, 'w');
Assert::AreEqual(true, dpSolve->topoSort());
}- dll测试
TEST_METHOD(Test_1) // -w
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bd",
"cd",
};
char* chain[100];
char* ans[] = {
"ab", "bc", "cd"
};
Assert::AreEqual(3, gen_chain_word(words, 6, chain, 0, 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
}
TEST_METHOD(Test_2) // -c
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bd",
"cd",
};
char* chain[100];
char* ans[] = {
"accccccccccccccccccccc", "cd"
};
Assert::AreEqual(2, gen_chain_char(words, 6, chain, 0, 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_3) // -w -h
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
};
char* chain[100];
char* ans[] = {
"bc", "cd"
};
Assert::AreEqual(2, gen_chain_word(words, 6, chain, 'b', 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_4) // -c -h
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
"dd",
};
char* chain[100];
char* ans[] = {
"bdddd", "dd"
};
Assert::AreEqual(2, gen_chain_char(words, 7, chain, 'b', 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_5) // -w -t
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
};
char* chain[100];
char* ans[] = {
"ab", "bc"
};
Assert::AreEqual(2, gen_chain_word(words, 6, chain, 0, 'c', false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_6) // -c -t
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"bc",
"bdddd",
"cd",
"cc"
};
char* chain[100];
char* ans[] = {
"accccccccccccccccccccc", "cc"
};
Assert::AreEqual(2, gen_chain_char(words, 7, chain, 0, 'c', false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_7) // -w -h -t
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"be",
"cd",
"ce",
"de"
};
char* chain[100];
char* ans[] = {
"bc", "cd"
};
Assert::AreEqual(2, gen_chain_word(words, 10, chain, 'b', 'd', false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_8) // -c -h -t
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"be",
"cd",
"ce",
"de",
"dd",
};
char* chain[100];
char* ans[] = {
"bdddd", "dd"
};
Assert::AreEqual(2, gen_chain_char(words, 11, chain, 'b', 'd', false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_9) // -w but have ring
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"db",
"be",
"cd",
"ce",
"de"
};
char* chain[100];
Assert::AreEqual(-4, gen_chain_word(words, 11, chain, 0, 0, false));
}
TEST_METHOD(Test_10) // -c but have ring
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bc",
"bdddd",
"db",
"be",
"cd",
"ce",
"de"
};
char* chain[100];
Assert::AreEqual(-4, gen_chain_char(words, 11, chain, 0, 0, false));
}
TEST_METHOD(Test_11) // -w have self
{
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bb",
"bc",
"bdddd",
"be",
"cc",
"cd",
"ce",
"dd",
"de"
};
char* chain[100];
char* ans[] = {
"ab", "bb", "bc", "cc", "cd", "dd", "de"
};
Assert::AreEqual(7, gen_chain_word(words, 13, chain, 0, 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
Assert::AreEqual(0, strcmp(chain[3], ans[3]));
Assert::AreEqual(0, strcmp(chain[4], ans[4]));
Assert::AreEqual(0, strcmp(chain[5], ans[5]));
Assert::AreEqual(0, strcmp(chain[6], ans[6]));
}
TEST_METHOD(Test_12) { // -c have self
char* words[] = {
"ab",
"accccccccccccccccccccc",
"ad",
"ae",
"bb",
"bc",
"bdddd",
"be",
"cc",
"cd",
"ce",
"dd",
"de"
};
char* chain[100];
char* ans[] = {
"accccccccccccccccccccc", "cc", "cd", "dd", "de"
};
Assert::AreEqual(5, gen_chain_char(words, 13, chain, 0, 0, false));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
Assert::AreEqual(0, strcmp(chain[3], ans[3]));
Assert::AreEqual(0, strcmp(chain[4], ans[4]));
}
TEST_METHOD(Test_13) // -w -r
{
char* words[] = {
"ab", "aaaaabbbbbccccc", "aaaaaddddd",
"bc",
"cb", "cd",
};
char* chain[100];
char* ans[] = {
"aaaaabbbbbccccc", "cb", "bc", "cd"
};
Assert::AreEqual(4, gen_chain_word(words, 6, chain, 0, 0, true));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
Assert::AreEqual(0, strcmp(chain[3], ans[3]));
}
TEST_METHOD(Test_14) { // -c -r
char* words[] = {
"ab", "aaaccc", "aaaaabbbbbcccccddddd",
"bc",
"cb", "cd",
"dd",
};
char* ans[] = {
"aaaaabbbbbcccccddddd", "dd"
};
char* chain[100];
Assert::AreEqual(2, gen_chain_char(words, 7, chain, 0, 0, true));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
}
TEST_METHOD(Test_15) { // -w -r -h -t
char* words[] = {
"ab",
"bccccccccccccccccccccccccccc", "bd",
"cd",
"da", "dc",
};
char* ans[] = {
"bd", "dc", "cd", "da"
};
char* chain[100];
Assert::AreEqual(4, gen_chain_word(words, 6, chain, 'b', 'a', true));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
Assert::AreEqual(0, strcmp(chain[3], ans[3]));
}
TEST_METHOD(Test_16) { // -c -r -h
char* words[] = {
"ab",
"bccccccccccccccccccccccccccc", "bd",
"cd",
"da", "dc",
};
char* ans[] = {
"bccccccccccccccccccccccccccc","cd", "da"
};
char* chain[100];
Assert::AreEqual(3, gen_chain_char(words, 6, chain, 'b', 'a', true));
Assert::AreEqual(0, strcmp(chain[0], ans[0]));
Assert::AreEqual(0, strcmp(chain[1], ans[1]));
Assert::AreEqual(0, strcmp(chain[2], ans[2]));
}以下是测试时代码覆盖率及测试结果。


计算模块部分异常处理说明
- 异常种类:
- 输入输出单词表有效性
- 参数(head、tail)有效性
- 无环情况搜索到环
- 未搜索到单词链
- 异常测试:
- 输入输出单词表有效性测试
TEST_METHOD(Test_1) { char* words[] = { NULL, NULL, "ad", "bc", "bd", "cd", }; char* chain[100]; Assert::AreEqual(-3, gen_chain_word(words, 6, chain, 0, 0, false)); }- 参数有效性测试
TEST_METHOD(Test_2) { char* words[] = { "ab", "accccccccccccccccccccc", "ad", "bc", "bd", "cd", }; char* chain[100]; Assert::AreEqual(-1, gen_chain_word(words, 6, chain, '-', 0, false)); } TEST_METHOD(Test_3) { char* words[] = { "ab", "accccccccccccccccccccc", "ad", "bc", "bd", "cd", }; char* chain[100]; Assert::AreEqual(-2, gen_chain_word(words, 6, chain, 0, '-', false)); }- 环识别测试
TEST_METHOD(Test_6) { char* words[] = { "ab", "accccccccccccccccccccc", "ba", }; char* chain[100]; Assert::AreEqual(-4, gen_chain_word(words, 3, chain, 0, 0, false)); }- 未搜索到单词链测试
TEST_METHOD(Test_4) { char* words[] = { "ab", "accccccccccccccccccccc", "ad", }; char* chain[100]; Assert::AreEqual(-5, gen_chain_word(words, 3, chain, 0, 0, false)); }
界面模块设计
界面模块设计主要采用C++的 QT模块,利用QT creator 先设计好主要的GUI界面之后,导出代码,然后针对每个控件编写相应的响应函数。GUI 实在64位的编译环境下编写,主要支持功能时直接输入框输入单词,和用户交互式的导入文本文件,也支持将程序运行的结果导出到用户指定文件中。
模块主要界面如下:
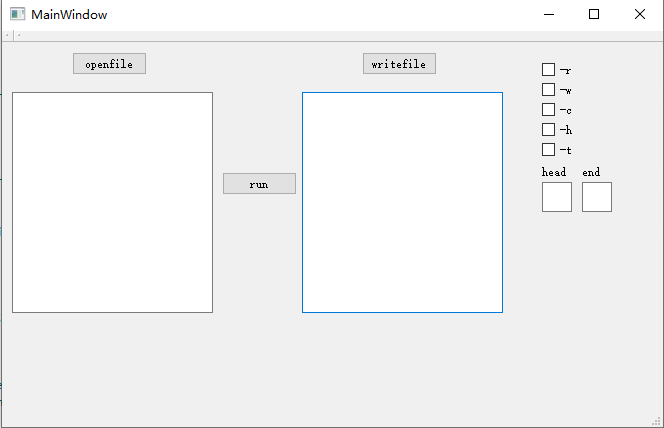
其中主要的功能函数绑定在openfile writefile 以及 run 三个Button 上,界面代码如下:
void gui(QMainWindow *MainWindow)
{
if (MainWindow->objectName().isEmpty())
MainWindow->setObjectName(QStringLiteral("MainWindow"));
MainWindow->resize(661, 397);
centralWidget = new QWidget(MainWindow);
centralWidget->setObjectName(QStringLiteral("centralWidget"));
//centralWidget = MainWindow;
textBrowser = new QTextBrowser(centralWidget);
textBrowser->setObjectName(QStringLiteral("textBrowser"));
textBrowser->setGeometry(QRect(300, 50, 201, 221));
textBrowser_2 = new QTextEdit(centralWidget);
textBrowser_2->setObjectName(QStringLiteral("textBrowser_2"));
textBrowser_2->setGeometry(QRect(10, 50, 201, 221));
checkBox = new QCheckBox(centralWidget);
checkBox->setObjectName(QStringLiteral("checkBox"));
checkBox->setGeometry(QRect(540, 40, 71, 16));
checkBox_2 = new QCheckBox(centralWidget);
checkBox_2->setObjectName(QStringLiteral("checkBox_2"));
checkBox_2->setGeometry(QRect(540, 60, 71, 16));
checkBox_3 = new QCheckBox(centralWidget);
checkBox_3->setObjectName(QStringLiteral("checkBox_3"));
checkBox_3->setGeometry(QRect(540, 80, 71, 16));
checkBox_4 = new QCheckBox(centralWidget);
checkBox_4->setObjectName(QStringLiteral("checkBox_4"));
checkBox_4->setGeometry(QRect(540, 100, 71, 16));
checkBox_5 = new QCheckBox(centralWidget);
checkBox_5->setObjectName(QStringLiteral("checkBox_5"));
checkBox_5->setGeometry(QRect(540, 20, 71, 16));
textEdit = new QLineEdit(centralWidget);
textEdit->setObjectName(QStringLiteral("textEdit"));
textEdit->setGeometry(QRect(540, 140, 30, 30));
textEdit_2 = new QLineEdit(centralWidget);
textEdit_2->setObjectName(QStringLiteral("textEdit_2"));
textEdit_2->setGeometry(QRect(580, 140, 30, 30));
label = new QLabel(centralWidget);
label->setObjectName(QStringLiteral("label"));
label->setGeometry(QRect(540, 120, 31, 20));
label_2 = new QLabel(centralWidget);
label_2->setObjectName(QStringLiteral("label_2"));
label_2->setGeometry(QRect(580, 120, 31, 20));
pushButton = new QPushButton(centralWidget);
pushButton->setObjectName(QStringLiteral("pushButton"));
pushButton->setGeometry(QRect(70, 10, 75, 23));
pushButton_2 = new QPushButton(centralWidget);
pushButton_2->setObjectName(QStringLiteral("pushButton_2"));
pushButton_2->setGeometry(QRect(360, 10, 75, 23));
pushButton_3 = new QPushButton(centralWidget);
pushButton_3->setObjectName(QStringLiteral("pushButton_3"));
pushButton_3->setGeometry(QRect(220, 130, 75, 23));
MainWindow->setCentralWidget(centralWidget);
menuBar = new QMenuBar(MainWindow);
menuBar->setObjectName(QStringLiteral("menuBar"));
menuBar->setGeometry(QRect(0, 0, 661, 23));
MainWindow->setMenuBar(menuBar);
mainToolBar = new QToolBar(MainWindow);
mainToolBar->setObjectName(QStringLiteral("mainToolBar"));
MainWindow->addToolBar(Qt::TopToolBarArea, mainToolBar);
statusBar = new QStatusBar(MainWindow);
statusBar->setObjectName(QStringLiteral("statusBar"));
MainWindow->setStatusBar(statusBar);
retranslateUi(MainWindow);
QMetaObject::connectSlotsByName(MainWindow);
} // setupUiopenfie
该 button 绑定了导入输入文件的函数,可以方便让用户直接导入自己的输入数据,代码实现如下:
void MainWindow::openfile()
{
QString fileName = QFileDialog::getOpenFileName(this,tr("choose log"),"",tr("TXT(*.txt)"));
if (fileName.isEmpty())
return;
QFile file(fileName);
if (file.open(QIODevice::ReadOnly | QIODevice::Text))
{
while (!file.atEnd())
{
QByteArray line = file.readLine();
QString str(line);
//qDebug() << str;;
this->textBrowser_2->insertPlainText(str);
}
file.close();
}
}writefile
该 button 绑定了导入结果数据的函数,可以方便让用户直接导出函数的运行结果,代码实现如下:
void MainWindow::writefile()
{
QString fileName = QFileDialog::getOpenFileName(this,tr("choose log"),"",tr("TXT(*.txt)"));
if (fileName.isEmpty())
return;
QFile file(fileName);
if (file.open(QIODevice::ReadOnly | QIODevice::Text))
{
while (!file.atEnd())
{
QByteArray line = file.readLine();
QString str(line);
//qDebug() << str;;
this->textBrowser_2->insertPlainText(str);
}
file.close();
}
}run
该button绑定的函数调用了Core.dll中的函数,实现了对数据的处理与计算。代码如下:
void MainWindow::run()
{
QLibrary mylib("Core.dll");
mylib.load();
//加载动态库
if (!mylib.isLoaded())
{
qDebug()<<QString("Load Oracle oci.dll failed!\n");
return ;
}
p_gen_chain_word get_chain_word=(p_gen_chain_word)mylib.resolve("gen_chain_word");
p_gen_chain_char get_chain_char=(p_gen_chain_char)mylib.resolve("gen_chain_char");
char head = '\0',end = '\0';
char* words[10000];
char* result[10000];
bool b_w = this->checkBox->isChecked()==true;
bool b_c = this->checkBox_2->isChecked()==true;
bool b_h = this->checkBox_3->isChecked()==true;
bool b_t = this->checkBox_4->isChecked()==true;
bool b_r = this->checkBox_5->isChecked()==true;
if(b_w && b_c)
{
QMessageBox:: information(NULL,"Error","can't choose w and c at the same time");
return;
}
if(!b_w && !b_c)
{
QMessageBox:: information(NULL,"Error","need a w or cs");
return;
}
if(b_h)
{
QByteArray head_text = this->textEdit->text().toLower().toLatin1();
head = head_text.data()[0];
if(!(head>='a' && head <='z'))
{
QMessageBox:: information(NULL,"Error","head must in a-z");
return;
}
}
if(b_t)
{
QByteArray head_text = this->textEdit_2->text().toLower().toLatin1();
end = head_text.data()[0];
if(!(head>='a' && head <='z'))
{
QMessageBox:: information(NULL,"Error","tail must in a-z");
return;
}
}
QStringList text = this->textBrowser_2->toPlainText().split("\n");
int len = 0;
int word_num = String2Char(text,words);
if(b_w)
{
len = get_chain_word(words,word_num,result,head,end,b_r);
}
if(b_c)
{
len = get_chain_char(words,word_num,result,head,end,b_r);
}
if(len<=1)
{
if(len == -4)
{
QMessageBox:: information(NULL,"Error","shouldn't have circles");
return;
}
if(len == -5)
{
QMessageBox:: information(NULL,"Error","Chain don't exist");
return;
}
QMessageBox:: information(NULL,"Error","unkown error! please input valid data");
return;
}
qDebug()<<len;
int i;
this->textBrowser->clear();
for(i = 0;i<len;i++)
{
string a(result[i]);
this->textBrowser->append(QString::fromStdString(a));
qDebug()<<QString::fromStdString(a);
}
}界面模块与计算模块对接
笔者小组同其他小组(16061161-15231112组和16061173-16061135组)进行了计算模块dll的交换。由于两个小组在项目开始前就对接口部分进行了讨论,在接口各参数、返回值以及功能上达成了共识,即计算接口设计部分所述。由于完成所有模块的设计及dll打包后,笔者在本小组的测试程序以及GUI上对dll进行了导入测试,在进入与其他小组对接阶段时并未遇到严重BUG,但在这过程中也遇到了一些小问题。
打包dll和GUI模块所支持处理器不同。
在最初打包dll时未注意X86和X64以及Debug和Release版本间的区别,打包出错误版本的dll,导致GUI无法导入dll。在复核了版本后就解决了这一问题。异常处理问题。
笔者小组采用Qt Creater进行GUI部分的开发,而后端进行Visual Studio进行开发。前者对于dll抛出异常的支持较差,容易导致程序出错。在采用返回值返回错误信息的方式后解决了这一问题。附对接后运行效果

开发过程总览
在结对之前,笔者和结对伙伴就已经认识,但从未在程序开发上进行合作。本次结对编程应当是小组两人第一次合作开发。以下是按照项目开发的里程碑来总览笔者小组开发的历程。
启动题目
在结对题目刚出来时,我们很快就在一起对需求进行了讨论,很快就列出了最初的项目设计以及日程计划,开始了项目的推进。由于其他课程以及实验室任务等原因,我们并没有很多公共的时间进行结对开发,仅有每天晚上用大约6小时左右的时间一同编程。完成初版
在项目启动后约两天,我们就按照最初的设计(设计见性能改进部分)实现了程序的基本功能。在实现的过程中,笔者按照单元测试的编写要求,编写并进行了单元测试,完成了第一版的测试集,供后期回归测试使用。优化算法
由于最初的设计的时间复杂度较高,我们在完成初版的测试后便进入了算法的改进和优化的阶段。笔者将部分的功能改为使用动态规划算法实现,并根据搜索单词链的要求设计了不同的递推式。笔者的搭档将初版的深度搜索进行了优化以补充动态规划未涉及的功能。经过了约4天,我们基本完成了算法的优化,开始了新测试的编写以及进行回归测试。GUI开发和核心代码封装
在算法优化的后半阶段,我们开始了GUI部分的同步开发以及计算模块的封装。这一部分是我们整个开发过程中最为艰难的阶段。我们在Qt环境的配置、dll的打包及使用上遇到了很多困难。主要在于dll类似于黑盒,我们在测试其是否打包成功并加载入Qt是耗费了很多时间。终版完成
最终经过了两周的结对编程,笔者和搭档较好的完成了最长单词链的程序。在这过程中,由于是第一次结对编程前期的效率并不高。直到进入了优化阶段,我们在逐渐找到了结对编程的节奏,最终使用了约2000分钟完成了项目。附结对编程图片


总结
结对编程优缺点
经过长达两周的结对编程,结合《构建之法》中对结对编程的描述以及这两周的亲身经历,笔者对于结对编程的优缺点有了以下的感想。
两人合作,更易解决问题
在编程的过程中,笔者两人一同遇到了许多的困难:从编程语言的使用,到算法的设计,再到代码的实现。相较于单人编程,两人同时对问题进行思考,通过讨论发现两人解决问题的漏洞,互补双方解决问题的方法,有效地解决问题。比如,在笔者同伙伴一起编写单词链搜索函数时对于每个代码分支,递归调用都进行了类似一人推演一人审核的模式,有效地突破了程序中的难点。相互学习,共同进步
在进行结对编程时,每人都有一段时间负责在对方编程的过程中在旁边进行审核。在“旁审”队友编程的过程中,笔者从队友的编程方式吸取了许多有用的部分,比如算法实现的思路,代码编写习惯等。将这些优点融入到自己的编程中,优化了自己的编程方式。同时编程,降低沟通难度
结对编程要求两人同时在一起进行开发。笔者与队友在大多数时间里是按照结对编程的要求一同编程。很明显能感觉到,自己很熟悉在这段时间的编写的代码,即使是对方在掌控键盘编写。在一定程度上,减少了两人阅读对方代码,询问如何使用对方代码时消耗的时间。相较之下,程序有一部分代码并不是两人一起编写的,在使用仅由对方编写的代码时常会产生许多的疑惑,需要在沟通上花费不少的时间。时间规划上存在难度
结对开发的两人并不是一直能够抽出时间一同编程。时间的碎片化也增加了两人一同使用大块时间进行编程的难度。就笔者两人而言,在这两周中基本上只有晚上有可能同时有时间结对编程。而白天常常会是一人有空而另一人有事的情况。因而结对编程时,对于时间上的规划存在一定的难度。但是如果是在类似于公司的环境中进行结对编程,这个问题应当会减轻很多。工程量较大时,进度较难推进
结对编程和分工开发就好比单线程与多线程。当任务的工作量较大,并且各模块的开发任务能分解为并行度较高的子任务的时候,很明显进行分工“多线程”开发的效率会高一些。再基于上一条,在面对工作量较大的任务,结对编程很有可能会在推进开发进度上出现困难。在笔者结对编程的前期,两人编程的效率是比较可观的,很快就完成了基本功能。但随之而来的测试、优化、回归测试、GUI绘制等等任务使得本来时间就不太富裕的结对编程出现的进度推进上的困难。最终笔者两人将部分任务的任务进行了分工开发,缓解结对任务的压力。
结对编程反思
经过了两周的合作,笔者对自己和队友在结对编程中各自的亮点和不足进行了一下总结。
| 队员 | 优点 | 不足 |
|---|---|---|
| 笔者 | 1.代码编写规范 2.吃苦耐劳 3.积极推动项目 |
解决复杂算法问题能力有待加强 |
| 队友 | 1.算法能力强 2.肝帝 3.沟通能力强 |
经常打错字 |