1.大纲
Es是什么?处理哪种业务逻辑用的多?
Es类比数据库是什么?
对于数据库的字段、表等,在es中叫什么?
Es的refresh把数据写到哪里?
Es的数据如何变成检索和聚合索引的?
Es的flush操作是干什么的?
2.Es是什么?处理哪种业务逻辑用的多?
elasticsearch简写es,es是一个高扩展、开源的全文检索和分析引擎,它可以准实时地快速存储、搜索、分析海量的数据。
什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
es的应用场景
- 一个线上商城系统,用户需要搜索商城上的商品。
在这里你可以用es存储所有的商品信息和库存信息,用户只需要输入”空调”就可以搜索到他需要搜索到的商品。 - 一个运行的系统需要收集日志,用这些日志来分析、挖掘从而获取系统业务未来的趋势。
你可以用logstash(elk中的一个产品,elasticsearch/logstash/kibana)收集、转换你的日志,并将他们存储到es中。一旦数据到达es中,就你可以在里面搜索、运行聚合函数等操作来挖掘任何你感兴趣的信息。 - 如果你有想基于大量数据(数百万甚至数十亿的数据)快速调查、分析并且要将分析结果可视化的需求。
你可以用es来存储你的数据,用kibana构建自定义的可视化图形、报表,为业务决策提供科学的数据依据。
直白点讲,es是一个企业级海量数据的搜索引擎,可以理解为是一个企业级的百度搜索,除了搜索之外,es还可以快速的实现聚合运算。
3.Es类比数据库是什么?

4.Es的refresh把数据写到哪里?
refresh实现的是文档从内存移到文件系统缓存的过程。
5.Es的数据如何变成检索和聚合索引的?
6.Es的flush操作是干什么的?
刷到磁盘
7.整体流程
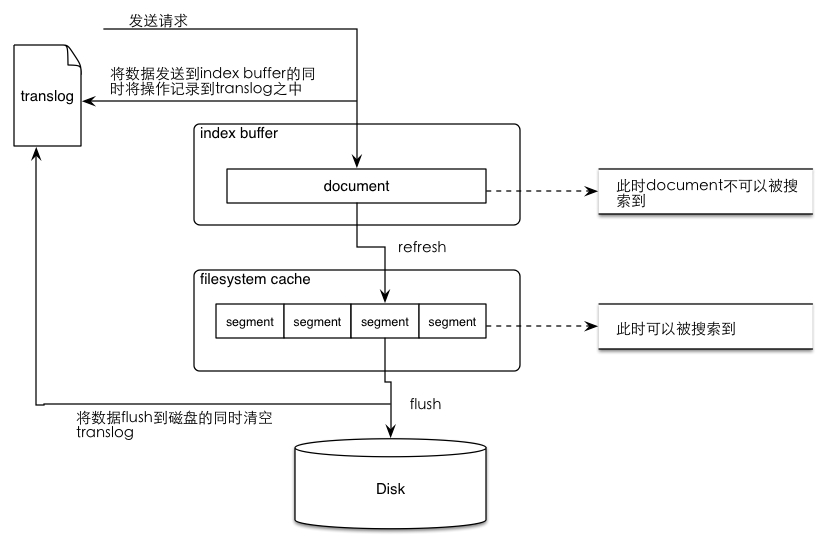
- 数据写入buffer缓冲和translog日志文件中。
当你写一条数据document的时候,一方面写入到mem buffer缓冲中,一方面同时写入到translog日志文件中。 - buffer满了或者每隔1秒(可配),refresh将mem buffer中的数据生成index segment文件并写入os cache,此时index segment可被打开以供search查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空mem buffer供后续使用。可见,refresh实现的是文档从内存移到文件系统缓存的过程。
- 重复上两个步骤,新的segment不断添加到os cache,mem buffer不断被清空,而translog的数据不断增加,随着时间的推移,translog文件会越来越大。
- 当translog长度达到一定程度的时候,会触发flush操作,否则默认每隔30分钟也会定时flush,其主要过程:
4.1. 执行refresh操作将mem buffer中的数据写入到新的segment并写入os cache,然后打开本segment以供search使用,最后再次清空mem buffer。
4.2. 一个commit point被写入磁盘,这个commit point中标明所有的index segment。
4.3. filesystem cache(os cache)中缓存的所有的index segment文件被fsync强制刷到磁盘os disk,当index segment被fsync强制刷到磁盘上以后,就会被打开,供查询使用。
4.4. translog被清空和删除,创建一个新的translog。
8.知识点
ES没有用户验证和权限控制
ES没有事务的概念,不支持回滚,误删不能恢复
ES免费,完全开源;传统数据库部分免费
ES采用倒排索引,传统数据库采用B+树索引
ES分布式搜索,传统数据库遍历式搜索
ES支持分片和复制,从而方便水平分割和扩展,复制保证了es的高可用与高吞吐。