相信Excel大家都不陌生,但是还是普及一下Excel到底是什么。Excel是Microsoft为使用Windows和Apple Macintosh操作系统的电
脑
学习Python中有不明白推荐加入交流群
号:984632579
群里有志同道合的小伙伴,互帮互助,
群里有不错的视频学习教程和PDF!
编写的一款电子表格软件。直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,使Excel成为最流行的个人计算机数据处理软件。在1993年,作为MicrosoftOffice的组件发布了5.0版之后,Excel就开始成为所适用操作平台上的电子制表软件的霸主。(百度百科如是说)。
Excel以其优异的表现,在桌面端办公软件中占据一席之地,常用Excel的人知道,它有三个最基本的功能:数据存储、统计分析、绘制图形。抛开其他不说,很多人利用Excel存储数据,其实,表格跟数据库表类似,行、列、表头(字段名称)等。因此,很多人(非数据库专业人员)设计好相应的表格来存储相应的数据,在应用中,很多系统设计完成后,用户想通过Excel导入数据,这就需要程序开发人员针对设计好的表格和数据库表进行对应,做好数据解析、入库的工作,因此,我就简单学了一下Python如何解析Excel。
Python操作Excel,主要用到xlrd和xlwt这两个库,即xlrd是读Excel,xlwt是写Excel的库。在Windows命令行输入conda install xlrd和conda installxlwt,稍等片刻,安装完成,即可使用这两个库。这种安装的前提是你的开发环境中安装了Anaconda并设置了环境变量。如果没有的话,可以用pip命令进行安装。
以如下表格为例,介绍相应的操作方法:
首先,获得工作表格。
xlsxFile =xlrd.open_workbook(r'C:\Users\admin\Desktop\123.xlsx')这里需要注意的是,由于\有特殊含义,所以在传递文件路径时,前面带有字母r,表示这个字符串不需要转义。
其次,找到对应的工作页。有三种方法可以获得工作页:两种是根据工作页的索引,一种是根据工作页的名字。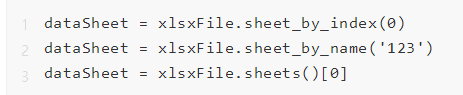
找到工作页,其实就相当于获取到了这个表格,然后,关键问题来了,就看你想怎么取得表格数据了。
这两个语句可以得出这个工作页到底有几行几列,获取这两个关键信息的用处在于可以获取每一行后,逐列获取行中每一个单元格数据。
for i in range(rowNum):
row =dataSheet.row(i)
for j inrange(colNum):
print(str(i)+' '+str(j)+' '+str(row[j].ctype) + ' ' + str(row[j].value))遍历每一行,获取这个行的对象之后,遍历每一个单元格,得到单元格的数据类型和数据值。输出结果如下
以上结果有4列,第一列是行号,第二列是列号,第三列是这个单元格的数据类型,第四列是数据的值。话说数据类型这些数字都是什么意思?ctype: 0 empty,1string,2 number, 3 date,4 boolean,5 error。阅读程序你会发现,日期类型的单元格和显示的日期不一样,这么处理一下即可。
date_value = xlrd.xldate_as_tuple(row[j].value, 0)print(str(i) + ' ' + str(j) + ' ' + str(row[j].ctype) + ' ' + date(*date_value[:3]).strftime('%Y/%m/%d'))
完整代码如下:
# -*- coding: utf-8 -*-
# Author:Dong.Zhang
# Email:[email protected]
import xlrd
from datetime import date,datetime
# 开始读取文件
xlsxFile = xlrd.open_workbook(r'C:\Users\admin\Desktop\123.xlsx')
# 找到对应的sheet
dataSheet = xlsxFile.sheet_by_index(0)
dataSheet = xlsxFile.sheet_by_name('123')
dataSheet = xlsxFile.sheets()[0]
# 查看此页由多少行和多少列
rowNum = dataSheet.nrows
colNum = dataSheet.ncols
# 逐行遍历sheet
for i in range(rowNum):
row = dataSheet.row(i)
for j in range(colNum):
if row[j].ctype != 3:
print(str(i)+' '+str(j)+' '+str(row[j].ctype) + ' ' + str(row[j].value))
else:
date_value = xlrd.xldate_as_tuple(row[j].value, 0)
print(str(i) + ' ' + str(j) + ' ' + str(row[j].ctype) + ' ' + date(*date_value[:3]).strftime('%Y/%m/%d'))
#print(date_value)
#print(date(*date_value[:3]))
#print(date(*date_value[:3]).strftime('%Y/%m/%d'))
# 按照行序逐个遍历单元格
for rowIndex in range(rowNum):
for colIndex in range(colNum):
cell = dataSheet.cell(rowIndex, colIndex)
#print(str(cell.ctype) + ' ' + str(cell.value))