以下是利用卷积神经网络对某一个句子的处理结构图,我们进行垃圾邮件分类的原理也就是这样。
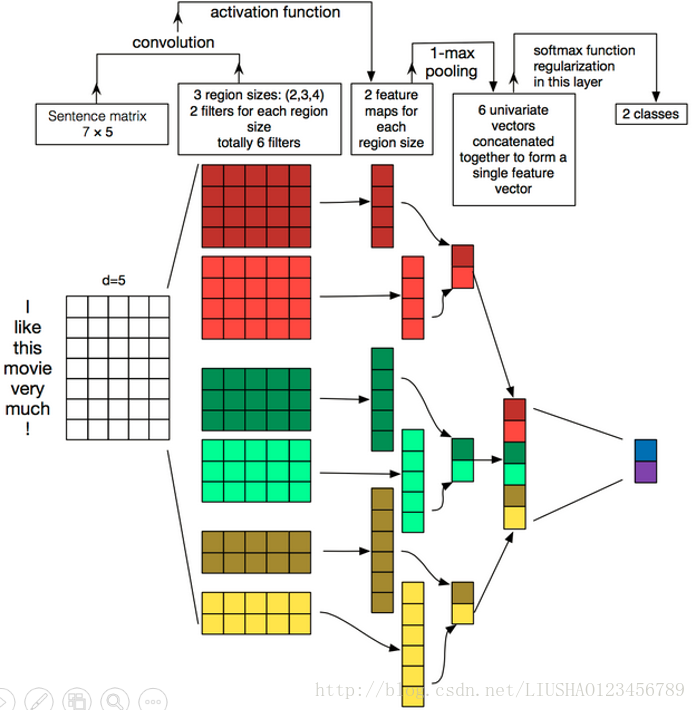
我们从上图可知,将一句话转化成一个矩阵。我们看到该句话有6个单词和一个标点符号,所以我们可以将该矩阵设置为7行,对于列的话每个单词可以用什么样的数值表示。我们可以将其转化成向量的形式。所以其为7*5的矩阵,其次因为它不是图片,所以不存在通道一说,说白了就是7*5*1。其次在选择filter的时候,至少要以一个单词为单位。region就是设置几个单词为单位。
数据集下载链接链接:https://pan.baidu.com/s/1kVkXrZT 密码:iukq
源代码如下:
train.py:
#! /usr/bin/env python
import tensorflow as tf
import numpy as np
import os
import time
import datetime
import data_helpers
from text_cnn import TextCNN
from tensorflow.contrib import learn
# Parameters
# ==================================================
# Data loading params
tf.flags.DEFINE_float("dev_sample_percentage", .1, "Percentage of the training data to use for validation")
tf.flags.DEFINE_string("positive_data_file", "./data/rt-polaritydata/rt-polarity.pos", "Data source for the positive data.")
tf.flags.DEFINE_string("negative_data_file", "./data/rt-polaritydata/rt-polarity.neg", "Data source for the negative data.")
# Model Hyperparameters
tf.flags.DEFINE_integer("embedding_dim", 128, "Dimensionality of character embedding (default: 128)")
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')")
tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)")
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.0, "L2 regularization lambda (default: 0.0)")
# Training parameters
tf.flags.DEFINE_integer("batch_size", 64, "Batch Size (default: 64)")
tf.flags.DEFINE_integer("num_epochs", 200, "Number of training epochs (default: 200)")
tf.flags.DEFINE_integer("evaluate_every", 100, "Evaluate model on dev set after this many steps (default: 100)")
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")
# Misc Parameters
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
FLAGS._parse_flags()
print("\nParameters:")
for attr, value in sorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(), value))
print("")
# Data Preparation
# ==================================================
# Load data
print("Loading data...")
x_text, y = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
# Build vocabulary
max_document_length = max([len(x.split(" ")) for x in x_text])
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
x = np.array(list(vocab_processor.fit_transform(x_text)))
# Randomly shuffle data
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(y)))
x_shuffled = x[shuffle_indices]
y_shuffled = y[shuffle_indices]
# Split train/test set
# TODO: This is very crude, should use cross-validation
dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y)))
x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]
print("Vocabulary Size: {:d}".format(len(vocab_processor.vocabulary_)))
print("Train/Dev split: {:d}/{:d}".format(len(y_train), len(y_dev)))
# Training
# ==================================================
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
cnn = TextCNN(
sequence_length=x_train.shape[1],
num_classes=y_train.shape[1],
vocab_size=len(vocab_processor.vocabulary_),
embedding_size=FLAGS.embedding_dim,
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))),
num_filters=FLAGS.num_filters,
l2_reg_lambda=FLAGS.l2_reg_lambda)
# Define Training procedure
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-3)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# Write vocabulary
vocab_processor.save(os.path.join(out_dir, "vocab"))
# Initialize all variables
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
# Generate batches
batches = data_helpers.batch_iter(
list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
dev_step(x_dev, y_dev, writer=dev_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, './', global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
text_cnn.py
import tensorflow as tf
import numpy as np
class TextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
#self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool = tf.concat(pooled_outputs,3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# CalculateMean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
data_helper.py
import numpy as np
import re
import itertools
from collections import Counter
def clean_str(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
def load_data_and_labels(positive_data_file, negative_data_file):
"""
Loads MR polarity data from files, splits the data into words and generates labels.
Returns split sentences and labels.
"""
# Load data from files
positive = open(positive_data_file, "rb").read().decode('utf-8')
negative = open(negative_data_file, "rb").read().decode('utf-8')
positive_examples = positive.split('\n')[:-1]
negative_examples = negative.split('\n')[:-1]
positive_examples = [s.strip() for s in positive_examples]
negative_examples = [s.strip() for s in negative_examples]
#positive_examples = list(open(positive_data_file, "rb").read().decode('utf-8'))
#positive_examples = [s.strip() for s in positive_examples]
#negative_examples = list(open(negative_data_file, "rb").read().decode('utf-8'))
#negative_examples = [s.strip() for s in negative_examples]
# Split by words
x_text = positive_examples + negative_examples
x_text = [clean_str(sent) for sent in x_text]
# Generate labels
positive_labels = [[0, 1] for _ in positive_examples]
negative_labels = [[1, 0] for _ in negative_examples]
y = np.concatenate([positive_labels, negative_labels], 0)
return [x_text, y]
def batch_iter(data, batch_size, num_epochs, shuffle=True):
"""
Generates a batch iterator for a dataset.
"""
data = np.array(data)
data_size = len(data)
num_batches_per_epoch = int((len(data)-1)/batch_size) + 1
for epoch in range(num_epochs):
# Shuffle the data at each epoch
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_indices]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
yield shuffled_data[start_index:end_index]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
eavl.py
#! /usr/bin/env python
import tensorflow as tf
import numpy as np
import os
import time
import datetime
import data_helpers
from text_cnn import TextCNN
from tensorflow.contrib import learn
import csv
# Parameters
# ==================================================
# Data Parameters
tf.flags.DEFINE_string("positive_data_file", "./data/rt-polaritydata/rt-polarity.pos", "Data source for the positive data.")
tf.flags.DEFINE_string("negative_data_file", "./data/rt-polaritydata/rt-polarity.neg", "Data source for the positive data.")
# Eval Parameters
tf.flags.DEFINE_integer("batch_size", 64, "Batch Size (default: 64)")
tf.flags.DEFINE_string("checkpoint_dir", "./", "Checkpoint directory from training run")
tf.flags.DEFINE_boolean("eval_train", False, "Evaluate on all training data")
# Misc Parameters
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
FLAGS._parse_flags()
print("\nParameters:")
for attr, value in sorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(), value))
print("")
# CHANGE THIS: Load data. Load your own data here
if FLAGS.eval_train:
x_raw, y_test = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
y_test = np.argmax(y_test, axis=1)
else:
x_raw = ["a masterpiece four years in the making", "everything is off."]
y_test = [1, 0]
# Map data into vocabulary
vocab_path = os.path.join(FLAGS.checkpoint_dir, "..", "vocab")
vocab_processor = learn.preprocessing.VocabularyProcessor.restore(vocab_path)
x_test = np.array(list(vocab_processor.transform(x_raw)))
print("\nEvaluating...\n")
# Evaluation
# ==================================================
checkpoint_file = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
graph = tf.Graph()
with graph.as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
# Load the saved meta graph and restore variables
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess, checkpoint_file)
# Get the placeholders from the graph by name
input_x = graph.get_operation_by_name("input_x").outputs[0]
# input_y = graph.get_operation_by_name("input_y").outputs[0]
dropout_keep_prob = graph.get_operation_by_name("dropout_keep_prob").outputs[0]
# Tensors we want to evaluate
predictions = graph.get_operation_by_name("output/predictions").outputs[0]
# Generate batches for one epoch
batches = data_helpers.batch_iter(list(x_test), FLAGS.batch_size, 1, shuffle=False)
# Collect the predictions here
all_predictions = []
for x_test_batch in batches:
batch_predictions = sess.run(predictions, {input_x: x_test_batch, dropout_keep_prob: 1.0})
all_predictions = np.concatenate([all_predictions, batch_predictions])
# Print accuracy if y_test is defined
if y_test is not None:
correct_predictions = float(sum(all_predictions == y_test))
print("Total number of test examples: {}".format(len(y_test)))
print("Accuracy: {:g}".format(correct_predictions/float(len(y_test))))
# Save the evaluation to a csv
predictions_human_readable = np.column_stack((np.array(x_raw), all_predictions))
out_path = os.path.join(FLAGS.checkpoint_dir, "..", "prediction.csv")
print("Saving evaluation to {0}".format(out_path))
with open(out_path, 'w') as f:
csv.writer(f).writerows(predictions_human_readable)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-7b4cdcb592.css" rel="stylesheet">
</div>
</article>