SQL
随着应用程序的功能越来越复杂,数据量越来越大,如何管理这些数据就成了大问题:
- 读写文件并解析出数据需要大量重复代码;
- 从成千上万的数据中快速查询出指定数据需要复杂的逻辑。
如果每个应用程序都各自写自己的读写数据的代码,一方面效率低,容易出错,另一方面,每个应用程序访问数据的接口都不相同,数据难以复用。
所以,数据库作为一种专门管理数据的软件就出现了。应用程序不需要自己管理数据,而是通过数据库软件提供的接口来读写数据。至于数据本身如何存储到文件,那是数据库软件的事情,应用程序自己并不关心:
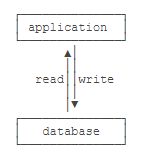
SQL是结构化查询语言的缩写,用来访问和操作数据库系统。SQL语句既可以查询数据库中的数据,也可以添加、更新和删除数据库中的数据,还可以对数据库进行管理和维护操作。不同的数据库,都支持SQL,这样,我们通过学习SQL这一种语言,就可以操作各种不同的数据库。
虽然SQL已经被ANSI组织定义为标准,不幸地是,各个不同的数据库对标准的SQL支持不太一致。并且,大部分数据库都在标准的SQL上做了扩展。也就是说,如果只使用标准SQL,理论上所有数据库都可以支持,但如果使用某个特定数据库的扩展SQL,换一个数据库就不能执行了。例如,Oracle把自己扩展的SQL称为PL/SQL,Microsoft把自己扩展的SQL称为T-SQL。
现实情况是,如果我们只使用标准SQL的核心功能,那么所有数据库通常都可以执行。不常用的SQL功能,不同的数据库支持的程度都不一样。而各个数据库支持的各自扩展的功能,通常我们把它们称之为“方言”。
总的来说,SQL语言定义了这么几种操作数据库的能力:
DDL:Data Definition Language
DDL允许用户定义数据,也就是创建表、删除表、修改表结构这些操作。通常,DDL由数据库管理员执行。
DML:Data Manipulation Language
DML为用户提供添加、删除、更新数据的能力,这些是应用程序对数据库的日常操作。
DQL:Data Query Language
DQL允许用户查询数据,这也是通常最频繁的数据库日常操作。
一、数据模型
数据库按照数据结构来组织、存储和管理数据,实际上,数据库一共有三种模型:
- 层次模型
- 网状模型
- 关系模型
层次模型就是以“上下级”的层次关系来组织数据的一种方式,层次模型的数据结构看起来就像一颗树:

网状模型把每个数据节点和其他很多节点都连接起来,它的数据结构看起来就像很多城市之间的路网:

关系模型把数据看作是一个二维表格,任何数据都可以通过行号+列号来唯一确定,它的数据模型看起来就是一个Excel表:
主流关系数据库
目前,主流的关系数据库主要分为以下几类:
- 商用数据库,例如:Oracle,SQL Server,DB2等;
- 开源数据库,例如:MySQL,PostgreSQL等;
- 桌面数据库,以微软Access为代表,适合桌面应用程序使用;
- 嵌入式数据库,以Sqlite为代表,适合手机应用和桌面程序。
二、数据类型
对于一个关系表,除了定义每一列的名称外,还需要定义每一列的数据类型。关系数据库支持的标准数据类型包括数值、字符串、时间等:
| 名称 | 类型 | 说明 |
|---|---|---|
| INT | 整型 | 4字节整数类型,范围约+/-21亿 |
| BIGINT | 长整型 | 8字节整数类型,范围约+/-922亿亿 |
| REAL | 浮点型 | 4字节浮点数,范围约+/-1038 |
| DOUBLE | 浮点型 | 8字节浮点数,范围约+/-10308 |
| DECIMAL(M,N) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10)表示一共20位,其中小数10位,通常用于财务计算 |
| CHAR(N) | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100)总是存储100个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100)可以存储0~100个字符的字符串 |
| BOOLEAN | 布尔类型 | 存储True或者False |
| DATE | 日期类型 | 存储日期,例如,2018-06-22 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期+时间,例如,2018-06-22 12:20:59 |
上面的表中列举了最常用的数据类型。很多数据类型还有别名,例如,REAL又可以写成FLOAT(24)。还有一些不常用的数据类型,例如,TINYINT(范围在0~255)。各数据库厂商还会支持特定的数据类型,例如JSON。
选择数据类型的时候,要根据业务规则选择合适的类型。通常来说,BIGINT能满足整数存储的需求,VARCHAR(N)能满足字符串存储的需求,这两种类型是使用最广泛的。
三、基本查询
1、增(INSERT INTO)
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...);
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小蓝 | M | 88 |
----》》 INSERT INTO students (class_id, name, gender, score) VALUES (2, '小绿', 'M', 80);
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小蓝 | M | 88 |
| 4 | 2 | 小绿 | M | 80 |
注:1、我们并没有列出id字段,也没有列出id字段对应的值,这是因为id字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在INSERT语句中也可以不出现。
2、字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。也就是说,可以写INSERT INTO students (score, gender, name, class_id) ...,但是对应的VALUES就得变成(80, 'M', '小绿', 2)。
2、改(UPDATE)
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 66 |
----》》UPDATE students SET name='大明', score=66 WHERE id=1;
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 66 |