分布式存储
(1) 5PB甚至更大的数据集怎么存储 ?
所有数据分块,每个数据块冗余存储在多台机器上(冗余可提高数据块高可用性)。另外一台机器上启动一个管理所有节点、以及存储在各节点上面数据块的服务。
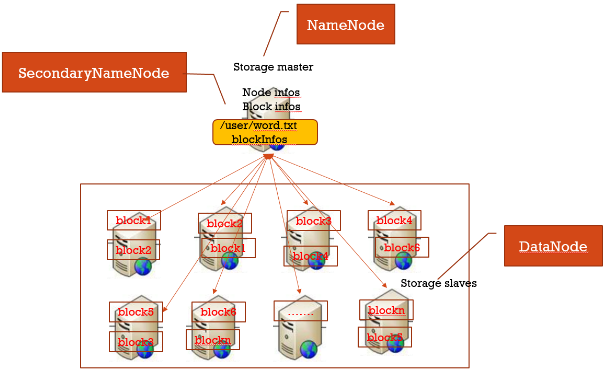
(2)分布式存储集群: master/slave结构集群
- 存在于slave上的文件:表示真实存放数据的文件即本地磁盘文件
- 存在于master上的文件:表示逻辑文件,它表示这个逻辑文件全路径名,与这个全路径对应的有数据块的存储信息(数据块位置等)
HDFS各组件及作用讲解
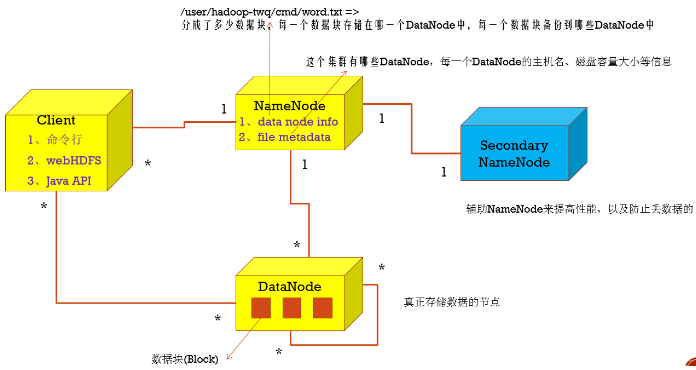
1.NameNode
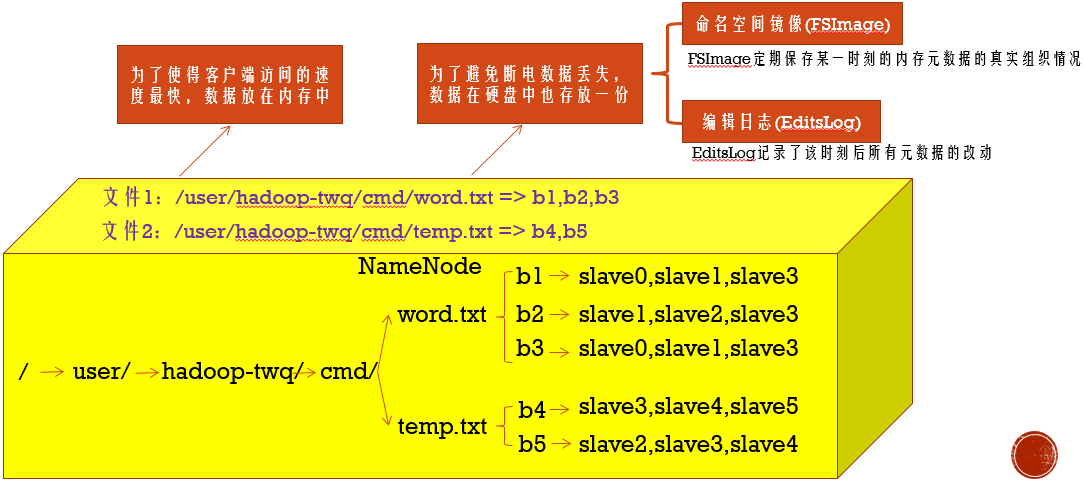
名字节点中维护了两层关系:
(1)HDFS文件系统的文件目录树,以及文件数据块的索引,即每一个文件对应的数据块列表
(2)数据块与数据节点的关系,即某一数据块保存在哪些数据节点中
2.
安装HDFS
(1)下载Hadoop ,选择版本hadoop-2.7.5.tar
(2)master slave1 slave2,使用hadoop-twq用户,家目录下创建目录~/bigdata
mkdir -p ~/bigdata
(3)master,使用hadoop-twq用户,上传安装包到目录~/bigdata,并解压。
cd ~/bigdata
tar -zxvf ~/bigdata/hadoop-2.7.5.tar.gz
(4)master,使用hadoop-twq用户,创建nameNode和dataNode需要的文件目录
mkdir -p ~/bigdata/dfs/name mkdir -p ~/bigdata/dfs/data
(5)master,使用hadoop-twq用户,修改配置文件【core-site.xml】【hdfs-site.xml】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9999</value>
<description>默认的HDFS路径</description>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>数据块的副本数量,需小于DataNode数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/name</value>
<description>NameNode存放数据的位置</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/data</value>
<description>DataNode存放数据的位置</description>
</property>
</configuration>
(6)master,使用hadoop-twq用户,配置JAVA_HOME,修改【hadoop-env.sh】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/local/lib/jdk1.8.0_161
(7)master,使用hadoop-twq用户,配置集群里所有DataNode的主机名,修改【slaves】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop
vi slaves
slave1
slave2
(8)master,使用hadoop-twq用户,将配置好的hadoop分发到每一个slave上
scp -r ~/bigdata/dfs hadoop-twq@slave1:~/bigdata
scp -r ~/bigdata/dfs hadoop-twq@slave2:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-twq@slave1:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-twq@slave2:~/bigdata
(9)master salve1 slave2,使用hadoop-twq用户,配置环境变量
vi ~/.bash_profile export HADOOP_HOME=~/bigdata/hadoop-2.7.5 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source ~/.bash_profile which hdfs
(10)master,使用hadoop-twq用户,格式化并启停HDFS
hdfs namenode -format ==>格式化
start-dfs.sh ==>启动hdfs
jps
http://master的IP地址:50070/ ==>看下是否部署成功
stop-dfs.sh ==>停止hdfs
安装注意事项:
1..更改salves配置前,需要先停止集群,否则有datanode无法停止。
2.多次格式化,可能会出现namenode和datanode的clusterID不一致。(clusterID在/home/hadoop-twq/bigdata/dfs/data/current/VERSION中)
3.core-site.xml中fs.defaultFS 描述集群中NameNode结点的URI(包括协议、主机名称、端口号)
4.hdfs-site.xml中dfs.namenode.http-address,描述HDFS web界面的监听端口,默认50070
添加节点
(1)修改所有节点的host
(2)修改namenode的配置文件slaves
(3)在新节点的机器上,启动服务
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
(4)namenode节点,均衡block
a.如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低mapred的工作效率。
start-balancer.sh
b.设置平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长
start-balancer.sh -threshold 5
c.配置hdfs balance时datanode之间数据迁移的带宽设置,默认只有1048576(1M/s)
vi hdfs-site.xml
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>
删除节点
(1)阻止待删除的机器连接Namenode
vi conf/hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>~/bigdata/hadoop-2.7.5/etc/hadoop/excludes</value>
<description>
Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.
</description>
</property>
vi ~/bigdata/hadoop-2.7.5/etc/hadoop/excludes ==>待下线机器hostname一个一行
slave3
slave4
(2)强制重新加载配置
hadoop dfsadmin -refreshNodes ==>强制重新加载配置,会在后台进行Block块移动
hadoop dfsadmin -report ==>查看到现在集群上连接的节点, Decommission in progress(执行中), Decommissioned(执行完毕)
(3)关闭节点
等待刚刚的操作结束后,需要下架的机器就可以安全的关闭了
(4)再次编辑excludes文件
一旦完成了机器下架,它们就可以从excludes文件移除了
登录要下架的机器,会发现DataNode进程没有了,但是TaskTracker依然存在,需要手工处理一下。
参考文档: