总帖:CDH 6系列(CDH 6.0、CHD6.1等)安装和使用
1.hive 整合 hbase
1.Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询、插入操作以及进行Join和Union等复杂查询、同时也可以将hive表中的数据映射到Hbase中。
2.应用场景
1.将ETL操作的数据存入HBase

2.HBase作为Hive的数据源

3.构建低延时的数据仓库

Hive HBase集成:文档地址 https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
从Hive 0.9.0开始,HBase集成至少需要HBase 0.92,早期版本的Hive正在使用HBase 0.89 / 0.90
Hive 1.x将与HBase 0.98.x及更低版本保持兼容。Hive 2.x将与HBase 1.x及更高版本兼容。
希望使用Hive 1.x使用HBase 1.x的消费者需要自己编译Hive 1.x流代码。
3.环境准备
1.hive与hbase版本兼容性
1.hbase与hive哪些版本兼容?
hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译。
hive1.x与hbase0.98.x或则更低版本是兼容的,不需要自己编译。
hive2.x与hbase1.x及比hbase1.x更高版本兼容,不需要自己编译。
重点注意:hive 1.x 与 hbase 1.x整合时,需要自己编译
2.Hive 0.6.0推出了storage-handler,用于将数据存储到HDFS以外的其他存储上。并方便的通过hive进行插入、查询等操作。
同时hive提供了针对Hbase的hive-hbase-handler。这使我们在使用hive节省开发M/R代码成本的同时还能获得HBase的特性来快速响应随机查询。
3.但是,hive自带的hive-hbase-handler是针对特定版本的Hbase的,比如:0.7.0版本的hive编译时使用的是0.89.0版本的Hbase,
0.6.0版本的hive默认使用0.20.3版本的hbase进行编译。
如果能够找到对应的版本,可以跳过编译的步骤直接使用。不过,我们现状已经找不到这些版本的Hbase与之配合使用了。
所以只好自己来编译这个jar包。
4.使用不匹配的版本,一些功能会发生异常。其原因是由于没有重新编译storage-handler组件,发现在hive中查询HBase表存在问题。
hive-hbase-handler.jar的作用在hbase与hive整合的时候发挥了重要作用,有了这个包,hbase与hive才能通信。
如果想hbase1.x与hive1.x整合,比如Hive版本 hive-1.x 和 hbase的版本hbase-1.x 进行整合的话,需要编译 hive1.x 的源代码本身。
4.编译hive-hbase-handler.jar:
hive 1.x版本 只能与 hbase 0.98.x版本或则更低版本进行兼容的,而下面则演示 Hive版本 hive-1.2.1 和 hbase的版本 hbase-1.2.1 进行整合,
那么必须重新编译 apache-hive-1.2.1-src.tar.gz 源代码本身。apache-hive-1.2.1-src目录中的 hbase-handler文件夹 本身为一个项目。
首先便需要修改hbase-handler项目中的pom.xml依赖,从查看源代码得知,apache-hive-1.2.1版本 依赖的是 hbase 0.98.9版本,
因此pom.xml中此处修改为 依赖 hbase 1.2.1版本

1.在eclipse中创建一个项目。Java project即可。


2.随便起个名,finish即可。导入代码,在创建好的项目上点击右键,选择Import,选择General下的FileSystem。
3.找到 apache-hive-1.2.1-src\hbase-handler\src\java 目录选择其中的org目录进行导入到项目中。

4.添加依赖包
导入代码后可以看到很多的错误提示。这时由于没有引入依赖的jar包导致的。
下面,我们引入需要hadoop、hive、hbase下相关的lib包。新建lib目录,把对应的依赖包导入。
选择 Build Path 点击 Add to Bulid Path ,至此可以导出我们需要的jar包了。
在org.apache.hadoop.hive.hbase包上点击右键,选择export选择java下的JAR file,选择一个生成位置,即可点击完成jar包文件。
到这里我们就生成了符合自己Hbase版本的hive-hbase-handler了。

5.hive与hbase整合环境配置
1./root/hive/conf 修改hive-site.xml文件,添加配置属性(zookeeper的地址)
<property>
<name>hbase.zookeeper.quorum</name>
<value>NODE1:2181,NODE2:2181,NODE3:2181</value>
</property>
2.引入hbase的依赖包
在/root/hive/conf/hive-env.sh 文件中添加 export HIVE_CLASSPATH=$HIVE_CLASSPATH:/root/hbase/lib/*
表示将/root/hbase/lib 文件夹下的包导入到hive的环境变量中。
3.把编译好的 hive-hbase-handler-1.2.1.jar,替换掉 /root/hive/lib 中自带的 hive-hbase-handler-1.2.1.jar。
6.启动 hbase集群 之前必须先启动 zookeeper集群、hdfs集群
1.ZK集群:需要搭建一个ZK集群,并启动zk集群。每台机器都启动zookeeper(启动zookeeper 都必须执行 时间同步命令:ntpdate ntp6.aliyun.com)
cd /root/zookeeper/bin/
zkServer.sh start
查看集群状态、主从信息:
1.cd /root/zookeeper/bin/
2../zkServer.sh status # 查看状态:一个leader,两个follower
3.“follower跟随者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: follower
4.“leader领导者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: leader
5.jps命令:QuorumPeerMain
2.hadoop集群:脚本一键启动(推荐)
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有 Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
1.启动 hdfs 集群:
cd /root/hadoop/sbin
./start-dfs.sh
2.停止 hdfs 集群:
cd /root/hadoop/sbin
./stop-dfs.sh
3.Hbase集群:启动和关闭hbase集群,bin目录下自带了一键启动脚本
cd /root/hbase/bin
./start-hbase.sh # 启动 hbase集群
./stop-hbase.sh # 关闭 hbase集群

7.进入 Hive 交互模式:
本地路径下启动hive
cd /root/hive/bin
./hive
8.进入 hbase 交互模式:
shell命令 连接集群(任意一个路径下访问都可以):hbase shell
2.hive 整合 hbase案例
1.第一种方式:hbase表 映射到 hive表中(数据在hbase中)
该方式是先生成hbase表,在创建hive表,并且在创建hive表的同时指定所要映射hbase表
1.在hbase中创建表:表名hbase_test, 有三个列族 f1、f2、f3。创建该hbase表的目的是把该hbase表映射到hive表上
1.create '表名', {NAME => '列簇名', VERSIONS => '版本号数值'}
create 'hbase_test',{NAME => 'f1',VERSIONS => 1},{NAME => 'f2',VERSIONS => 1},{NAME => 'f3',VERSIONS => 1}
2.list # 查看所有表信息
2.插入数据到hbase中:put '表名','rowkey名','列簇名:列名','列值'
put 'hbase_test','r1','f1:name','zhangsan'
put 'hbase_test','r1','f2:age','20'
put 'hbase_test','r1','f3:sex','male'
put 'hbase_test','r2','f1:name','lisi'
put 'hbase_test','r2','f2:age','30'
put 'hbase_test','r2','f3:sex','female'
put 'hbase_test','r3','f1:name','wangwu'
put 'hbase_test','r3','f2:age','40'
put 'hbase_test','r3','f3:sex','male'
3.查询该表数据:scan 'hbase_test'

4.创建基于hbase表的 hive表,hbase表 映射到 hive表中
CREATE EXTERNAL TABLE hiveFromHbase(
rowkey string, # rowkey 代表的是 hbase中的 rowkey
f1 map<STRING,STRING>,
f2 map<STRING,STRING>,
f3 map<STRING,STRING>
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:,f2:,f3:") # 指定hbase表中的列簇名:列名
TBLPROPERTIES ("hbase.table.name" = "hbase_test"); # hive表中指定所映射的hbase表,那么便把该hbase表映射到hive表上
CREATE EXTERNAL TABLE hiveFromHbase(
rowkey string, # rowkey 代表的是 hbase中的 rowkey
column1 STRING,
column2 STRING,
column3 STRING
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:column1 ,f2:column2 ,f3:column3 ") # 指定hbase表中的列簇名:列名
TBLPROPERTIES ("hbase.table.name" = "hbase_test"); # hive表中指定所映射的hbase表,那么便把该hbase表映射到hive表上
例子:
create external table hivetable(rowkey string, column1 string,column2 string,column3 string)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = ":key,columnfamily1:column1,columnfamily1:column2,columnfamily2:column3")
tblproperties("hbase.table.name"="hbasetable");
1.这里hive表使用 EXTERNAL 外部表 映射到HBase中的表,这样,在Hive中删除表,并不会删除HBase中的表,
否则,如果hive表使用内部表映射到HBase中的表的话,那么在删除hive表时,还会连着删除HBase中的表。
2.另外,除了rowkey,其他三个字段使用Map结构来保存HBase中的每一个列族:"hbase.columns.mapping" = ":key,f1:,f2:,f3:"。
3.Hive表 和 HBase表 的字段映射关系,分别为:
Hive表中第一个字段映射:key(rowkey),第二个字段映射列族f1,第三个字段映射列族f2,第四个字段映射列族f3。
4.hbase.table.name:配置HBase中表的名字,如"hbase.table.name" = "hbase_test","hbase_test"为hbase表
5.hive中 查询 hive表“hiveFromHbase”,即能查询到 hive表 所映射到的 hbase表'hbase_test'中的数据

6.hbase中 存储数到 hbase表'hbase_test'中

7.Hive中插入数据到HBase表
insert into table hiveFromHbase
SELECT 'r4' AS rowkey,
map('name','zhaoliu') AS f1,
map('age','50') AS f2,
map('sex','male') AS f3
from person limit 1;
8.插入成功后,查看 hive表 hiveFromHbase 和 Hbase表 hbase_test 的数据
Hive中的外部表hiveFromHbase,就和其他外部表一样,只有一份元数据,真正的数据是在HBase表中,Hive通过hive-hbase-handler来操作HBase中的表。
1.hive表hiveFromHbase:

2.Hbase表hbase_test:

2.第二种方式:hive表 映射到 hbase表中(数据在hive中)
该方式是先在hive中创建hive表,并在创建语句中指定所要映射hbase表,并且该hbase表可以不需要预先存在,在创建hive表完成之后,便也会同时生成hbase表。
1.hive中 创建 “映射hbase的” hive表
create table hive_test(
id string, # id 代表的是 hbase中的 rowkey
name string, # 列名
age int,
address string
)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:name,f2:age,f3:address") # 指定hbase表中的列簇名:列名
TBLPROPERTIES ("hbase.table.name" = "hbaseFromhive"); # hive表中指定所映射的hbase表,那么便把该hive表映射到hbase表上
在hive1.2.1 跟 hbase 0.98整合时,需要添加:"hbase.mapred.output.outputtable" = "hbaseFromhive" 表属性
TBLPROPERTIES ("hbase.table.name" = "hbaseFromhive","hbase.mapred.output.outputtable"="hbaseFromhive");
如果不添加会报错:Must specify table name
创建了hive表之后还可以添加分区:
1.alter table 表名 add partition (分区字段名='分区字段值',分区字段名='分区字段值');
即创建 /user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值/分区字段名2=分区字段值
2.alter table 表名 drop partition (分区字段名='分区字段值');
即创建 /user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值
2.hbase中 查看 hbase映射表 是否产生:list

3.查看 hbase映射表 的表结构和数据
由于hive表中没有加载数据,此时hbase中映射的表也无数据


4.Hive表 加载数据,数据来源于另一张hive表hive_source(此时必须启动yarn集群):insert overwrite table hive_test select * from hive_source;
注意:insert ... select ... 会运行mapreduce,因此必须启动yarn集群

5.查看 hive表 和 hive表所映射的 hbase表 中的数据 均为一致


3.当前项目的例子:用户画像宽表导入hbase(此处使用第二种方式:hive表 映射到 hbase表中)
hive中 创建用户画像宽表:
1.create database if not exists adm;
2.create table if not exists adm.itcast_adm_personas(
user_id string ,--用户ID
......) TBLPROPERTIES (
"hbase.table.name" = "itcast_adm_personas_hbase_20170101", # hive表中指定所映射的hbase表,那么便把该hive表映射到hbase表上
"hbase.mapred.output.outputtable"="itcast_adm_personas_hbase_20170101" ) ; # "itcast_adm_personas_hbase_20170101" 为hbase表

Hive中加载数据到hive中:数据来源于另一张hive表hive_source
注意:insert ... select ... 会运行mapreduce,因此必须启动yarn集群
insert overwrite table adm.itcast_adm_personas_hbase select * from adm.itcast_adm_personas;

3.电商用户画像数据可视化的web项目:使用 Phoenix 操作hbase数据表
1.Phoenix 相当于一个Java中间件,提供jdbc连接,操作hbase数据表。Phoenix是一个HBase的开源SQL引擎。
你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
我们把SQL又放回NoSQL去了!这边说的NoSQL专指HBase,意思是可以用SQL语句来查询Hbase,你可能会说:“Hive和Impala也可以啊!”。
但是Hive和Impala还可以查询文本文件,Phoenix的特点就是,它只能查Hbase,别的类型都不支持!
但是也因为这种专一的态度,让Phoenix在Hbase上查询的性能超过了Hive和Impala!
2.Phoenix性能
1.Phoenix是构建在HBase之上的SQL引擎。你也许会存在“Phoenix是否会降低HBase的效率?”或者“Phoenix效率是否很低?”这样的疑虑,事实上并不会,
Phoenix通过以下方式实现了比你自己手写的方式相同或者可能是更好的性能(更不用说可以少写了很多代码):
编译你的SQL查询为原生HBase的scan语句。
检测scan语句最佳的开始和结束的key。
精心编排你的scan语句让他们并行执行。
推送你的WHERE子句的谓词到服务端过滤器处理。
执行聚合查询通过服务端钩子(称为协同处理器)。
2.除此之外,Phoenix还做了一些有趣的增强功能来更多地优化性能:
实现了二级索引来提升非主键字段查询的性能。
统计相关数据来提高并行化水平,并帮助选择最佳优化方案。
跳过扫描过滤器来优化IN,LIKE,OR查询。
优化主键的来均匀分布写压力。
3.Phoenix的安装部署
1.准备工作:提前安装好ZK集群、hadoop集群、Hbase集群
1.ZK集群:需要搭建一个ZK集群,并启动zk集群。每台机器都启动zookeeper(启动zookeeper 都必须执行 时间同步命令:ntpdate ntp6.aliyun.com)
cd /root/zookeeper/bin/
zkServer.sh start
查看集群状态、主从信息:
1.cd /root/zookeeper/bin/
2../zkServer.sh status # 查看状态:一个leader,两个follower
3.“follower跟随者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: follower
4.“leader领导者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: leader
5.jps命令:QuorumPeerMain
2.hadoop集群:脚本一键启动(推荐)
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有 Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
1.启动 hdfs 集群:
cd /root/hadoop/sbin
./start-dfs.sh
2.停止 hdfs 集群:
cd /root/hadoop/sbin
./stop-dfs.sh
3.Hbase集群:启动和关闭hbase集群,bin目录下自带了一键启动脚本
cd /root/hbase/bin
./start-hbase.sh # 启动 hbase集群
./stop-hbase.sh # 关闭 hbase集群

2.安装包
从对应的地址下载:http://mirrors.cnnic.cn/apache/phoenix/ (最新版本在对应的bin目录下) 或者 http://phoenix.apache.org/download.html(最新版本在对应的bin目录下)
这里我们使用的是:phoenix-4.8.2-HBase-1.2-bin.tar.gz
3.上传、解压
将对应的安装包上传到对应的Hbase集群其中一个服务器的一个目录下
解压:tar -zxvf phoenix-4.8.2-HBase-1.2-bin.tar.gz
重命名:mv phoenix-4.8.2-HBase-1.2-bin phoenix
4.配置
1.将 /root/phoenix 目录下的 phoenix-4.8.2-HBase-1.2-server.jar、phoenix-core-4.8.2-HBase-1.2.jar 拷贝到各个 /root/hbase/lib目录下。
cp /root/phoenix/phoenix-4.8.2-HBase-1.2-server.jar /root/hbase/lib
cp /root/phoenix/phoenix-core-4.8.2-HBase-1.2.jar /root/hbase/lib
scp /root/phoenix/phoenix-4.8.2-HBase-1.2-server.jar root@NODE2:/root/hbase/lib
scp /root/phoenix/phoenix-4.8.2-HBase-1.2-server.jar root@NODE3:/root/hbase/lib
scp /root/phoenix/phoenix-core-4.8.2-HBase-1.2.jar root@NODE2:/root/hbase/lib
scp /root/phoenix/phoenix-core-4.8.2-HBase-1.2.jar root@NODE3:/root/hbase/lib
2.将 /root/hbase/conf目录下的 配置文件hbase-site.xml,还有将/root/hadoop/etc/hadoop 下的core-site.xml、hdfs-site.xml放到/root/phoenix/bin/下,
替换phoenix原来的配置文件。
1.删除/root/phoenix目录中原有的hbase-site.xml:rm -rf /root/phoenix/hbase-site.xml
2.将/root/hadoop/etc/hadoop 下的core-site.xml、hdfs-site.xml放到/root/phoenix/bin/下
cp /root/hadoop/etc/hadoop/core-site.xml /root/phoenix/bin
cp /root/hadoop/etc/hadoop/hdfs-site.xml /root/phoenix/bin
3.重启hbase集群,使Phoenix的jar包生效。
5.验证是否成功
1.在 /root/phoenix/bin 下输入命令:
cd /root/phoenix/bin
./sqlline.py NODE1:2181 # 端口可以省略
出现如下界面说明启动成功
2.输入“!tables”查看都有哪些表。红框部分是用户建的表,其他为Phoenix系统表,系统表中维护了用户表的元数据信息。

3.退出Phoenix。输入“!quit”
4.Phoenix使用
1.Phoenix可以有4种方式调用:
1.批处理方式
2.命令行方式
3.GUI方式
4.JDBC调用方式
2.批处理方式
1.创建 user_phoenix.sql 文件,内容如下
CREATE TABLE IF NOT EXISTS user_phoenix ( state CHAR(2) NOT NULL, city VARCHAR NOT NULL,
population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
2.创建user_phoenix.csv数据文件
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
3.创建user_phoenix_query.sql文件,内容为:
SELECT state as "State", count(city) as "City Count", sum(population) as "Population Sum" FROM user_phoenix
GROUP BY state ORDER BY sum(population) DESC;
4.执行 /root/phoenix/bin/psql.py NODE1:2181 user_phoenix.sql user_phoenix.csv user_phoenix_query.sql
这条命令同时做了三件事:创建表、插入数据、查询结果。
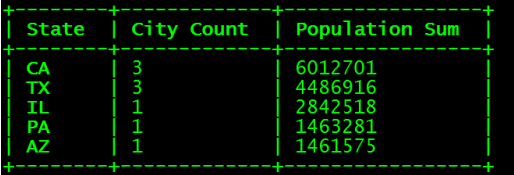
5.用Hbase shell 看下会发现多出来一个 USER_PHOENIX 表,用 scan '表名'命令查看一下这个表的数据

6.结论:
之前定义的 Primary key 为 state,city, 于是Phoenix就把输入的state,city的值拼起来成为 rowkey
其他的字段还是按照列名去保存,默认的列族为0
还有一个0:_0这个列是没有值的,这个是Phoenix处于性能方面考虑增加的一个列,不用管这个列
3.命令行方式
1.执行命令:
cd /root/phoenix/bin
./sqlline.py NODE1:2181 # 端口可以省略
2.可以进入命令行模式:0: jdbc:phoenix:NODE1> 然后执行相关的命令
3.退出命令行方式:执行 !quit
4.命令开头需要一个感叹号,使用help可以打印出所有命令
5.hbase中 建立employee的映射表:数据准备
进入 hbase 交互模式:shell命令 连接集群(任意一个路径下访问都可以):hbase shell
1.数据准备然后,我们来建立一个映射表,映射我之前建立过的一个hbase表 employee,有2个列族 company、family
1.create 'employee','company','family'
2.put 'employee','row1','company:name','ted'
put 'employee','row1','company:position','worker'
put 'employee','row1','family:tel','13600912345'
put 'employee','row2','company:name','michael'
put 'employee','row2','company:position','manager'
put 'employee','row2','family:tel','1894225698'
3.scan 'employee'
2.在建立映射表之前要说明的是,Phoenix是大小写敏感的,并且所有命令都是大写,如果你建的表名没有用双引号括起来,
那么无论你输入的是大写还是小写,建立出来的表名都是大写的,要创建小写的表名和字段名话,必须使用双引号括起来。
如果你需要建立出同时包含大写和小写的表名和字段名,请把表名或者字段名用双引号括起来。
3.你可以建立读写的表或者只读的表,他们的区别如下
读写表:如果你定义的列簇不存在,会被自动建立出来,并且赋以空值
只读表:你定义的列簇必须事先存在
6.建立映射表
cd /root/phoenix/bin
./sqlline.py NODE1:2181 # 端口可以省略 (hbase表 employee,有2个列族 company、family)
0: jdbc:phoenix:NODE1> CREATE TABLE IF NOT EXISTS "employee" ("no" VARCHAR(10) NOT NULL PRIMARY KEY, "company"."name" VARCHAR(30),
"company"."position" VARCHAR(20), "family"."tel" VARCHAR(20), "family"."age" INTEGER);

这个语句有几个注意点:
1.IF NOT EXISTS:可以保证如果已经有建立过这个表,配置不会被覆盖
2.作为rowkey的字段用 PRIMARY KEY 标定
3.列簇用 columnFamily.columnName 来表示,如:"company"."name"
4.family.age("family"."age") 是新增的字段,我之前建立测试数据的时候没有建立这个字段的原因是在hbase shell下无法直接写入数字型,
使用UPSERT 命令插入数据的时候你就可以看到真正的数字型在hbase 下是如何显示的。建立好后,查询一下数据
7.查询映射表数据
8.在phoenix插入数据、更改数据之后,实际就是对hbase中的数据进行插入和修改
1.插入或者更改数据在phoenix中使用upsert关键字,如果表中不存在该数据则插入,否则更新
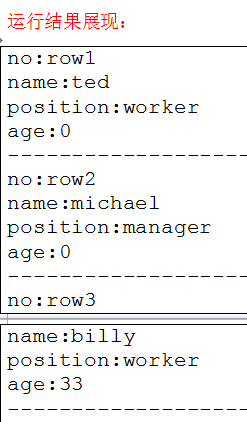
2.插入:0:jdbc:phoenix:NODE1> upsert into "employee" values('row3','billy','worker','16974681345',33);
3.修改数据:0: jdbc:phoenix:NODE1:2181> upsert into "employee" ("no","tel") VALUES ('row2','13588888888');
4.查询:select * from "表名";

9.查询Hbase数据
company:_0 这个列是没有值的,这个是Phoenix处于性能方面考虑增加的一个列,不用管这个列。

4.GUI方式
1.squirrel下载
从网址http://www.squirrelsql.org/下载相应版本的squirrel的安装jar包,比如下载squirrel-sql-3.7-standard.jar window版本。

2.squirrel安装
Window下:通过cmd进入window控制台,输入 java -jar squirrel-sql-3.7-standard.jar 显示安装界面。
3.squirrel 配置连接 Phoenix
1.配置squirrel
解压的 phoenix-4.7.0-HBase-1.1-bin.tar.gz 包的主目录下 将如下几个jar包拷贝到 squirrel安装目录的lib下

2.在安装目录下双击squirrel-sql.bat,点击左侧的Drivers,添加图标
配置说明:在出现的窗口中填写如下项
Name:就是个名字任意取就可以,这里使用phoenix
Example URL:jdbc:phoenix:NODE1:2181(这里是你的phonenix的jdbc地址,注意端口也可以不写,多个用逗号隔开)
Class Name:org.apache.phoenix.jdbc.PhoenixDriver

4.连接Phoenix
1.点击Aiiasses,点击右边的添加图标

配置说明:
1.这里还是名字随意写(这里使用phoenix),driver要选择刚才配置的可用的driver,我们刚才配置的是phoenix
2.url这里就是连接phonex的url选择了phoenix的driver以后自动出现也可以改,user name就是phoenix连接的主机的用户名,
密码就是该机器的密码,点击自动登录
3.然后点击test,显示连接成功即可(在这里最好不要直接点OK,先点Test,连接成功了再OK)




5.JDBC调用方式
1.打开Eclipse建立一个简单的Maven项目 phoenix
2.pom.xml文件内容:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcast</groupId>
<artifactId>phoenix</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>phoenix</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.7.0-HBase-1.1</version>
</dependency>
</dependencies>
</project>
3.建立一个类 PhoenixManager
package cn.itcast.phoenix;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class PhoenixManager
{
public static void main(String[] args) throws SQLException
{
Connection conn=null;
Statement state=null;
ResultSet rs=null;
try
{
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection("jdbc:phoenix:NODE1:2181");
state=conn.createStatement();
rs= state.executeQuery("select * from \"employee\"");
while(rs.next())
{
System.out.println("no:"+rs.getString("no"));
System.out.println("name:"+rs.getString("name"));
System.out.println("position:"+rs.getString("position"));
System.out.println("age:"+rs.getInt("age"));
System.out.println("-------------------------");
}
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
if(rs!=null)rs.close();
if(state!=null) state.close();
if(conn!=null) conn.close();
}
}
}
4.导入 phoenix建立映射表.sql
1.执行命令 可以进入命令行模式:0: jdbc:phoenix:NODE1> 然后执行相关的命令
cd /root/phoenix/bin
./sqlline.py NODE1:2181 # 端口可以省略
2.执行“ phoenix建立映射表.sql” 中语句:
create table "itcast_adm_personas_hbase_20170101"("user_id" varchar(100) primary key,。。。);

