请看链接https://www.cnblogs.com/fengyiru6369/p/7993366.html
1 # coding=utf-8
2 from selenium import webdriver
3 driver = webdriver.Firefox()
4 driver.maximize_window ()
5 driver.get("https://www.baidu.com")
6 try:
7 driver.find_element_by_id("kwf")
8 print("id is find")
9 except Exception as e:
10 print("exception find ",format(e))
11 driver.quit()
运行结果:
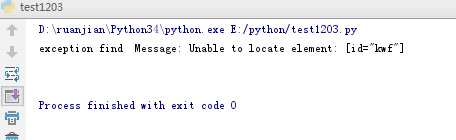
注:该断言判断是否获取对应的元素,再自动化脚本执行时,可以定位出现的问题
2.利用link text定位元素
1 try:
2 driver.find_element_by_link_text("新闻")
3 print ('test pass: element found by link text')
4 except Exception as e:
5 print ("Exception found", format(e))
3.利用partial link text定位元素
try:
driver.find_element_by_partial_link_text("主页").click()
print ('test pass: element found by partial link text')
except Exception as e:
print ("Exception found", format(e))
注:partial_link_text与link_text链接定位类似,partial link text就是选择这个元素的link text中一部分字段。
例如:百度首页带链接文字为:“把百度设为主页”。
为了更好的验证是否找到了“把百度添加到首页”这个元素,我在这个地方添加了一个click(),运行代码,可以看到确实点击了这个元素,代表找到了这个元素。
选择partial link text的时候,需要选择一个比较唯一的字段,来区分这个元素。
4.利用class name定位元素

1 try:
2 driver.find_element_by_class_name("s_ipt")
3 print ('test pass: element found by class name')
4 except Exception as e:
5 print ("Exception found", format(e))
5.利用name定位元素
try:
driver.find_element_by_name("wd") # 这里百度搜索输入框有name = 'wd'这个节点信息
print ('test pass: element found by name value')
except Exception as e:
print ("Exception found", format(e))
6.利用css定位元素
参考:http://blog.csdn.net/u011541946/article/details/68927139
7.清楚文本信息

1 # coding=utf-8
2 from selenium import webdriver
3 driver = webdriver.Firefox()
4 driver.maximize_window ()
5 driver.get("https://www.baidu.com")
6 driver.find_element_by_id("kw").send_keys("Selenium")
7 try:
8 driver.find_element_by_id("kw").clear()
9 driver.find_element_by_id ("kw1").send_keys ("Selenium")
10 print ('test pass: clean successful')
11 except Exception as e:
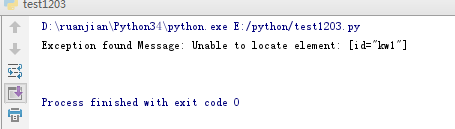
12 print ("Exception found", format(e))
13 driver.quit()
8.基本页面操作方法
driver.refresh() # 刷新方法 refresh
driver.back() # 从百度新闻后退到百度首页
driver.forward() # 百度首页前进到百度新闻
print(driver.capabilities['version']) # 打印浏览器version的值
print (driver.current_url) # current_url 方法可以得到当前页面的URL
print (driver.title) # title方法可以获取当前页面的标题显示的字段
在浏览器中新开一个界面:
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4 from selenium.webdriver.common.keys import Keys
5
6 driver = webdriver.Firefox ()
7 driver.maximize_window ()
8 # driver.implicitly_wait (6)
9
10 driver.get ("http://www.baidu.com/")
11 time.sleep (1)
12 ele = driver.find_element_by_tag_name ('body').send_keys (Keys.CONTROL + 't') # 触发ctrl + t 在浏览器中新开一个tab
13 time.sleep (1)
8.点击单选按钮-Radio Button
勾选一个单选按钮,就是调用元素方法click()
我们利用for语句遍历这两个单选按钮,依次点击他们。

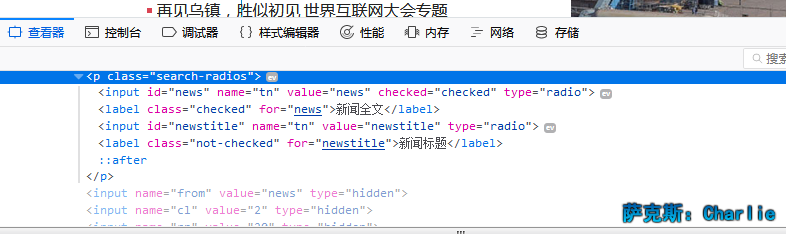
1 from selenium import webdriver
2 import time
3 driver = webdriver.Firefox ()
4 driver.maximize_window ()
5 driver.get ('http://news.baidu.com')
6 # driver.implicitly_wait (8)
7 print(driver.find_elements_by_xpath ("//*/input[@type='radio']"))
8 for i in driver.find_elements_by_xpath ("//*/input[@type='radio']"):
9 i.click ()
10 time.sleep (5)
9.获取元素页面上的文字
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4 from selenium.webdriver.common.keys import Keys
5
6 driver = webdriver.Firefox ()
7 driver.maximize_window ()
8 # driver.implicitly_wait (6)
9
10 driver.get ("http://www.baidu.com/")
11 time.sleep (1)
12 driver.find_element_by_xpath ("//*[@id='u1']/a[7]").click ()
13 time.sleep (1)
14
15 driver.find_element_by_xpath ("//*[@id='TANGRAM__PSP_10__submit']").click ()
16
17
18 # 断言方法二,本文重点介绍方法
19 error_mes = driver.find_element_by_xpath ("//*[@id='TANGRAM__PSP_10__error']").text
20 print(error_mes)
21 try:
22 assert error_mes == u'请您填写手机/邮箱/用户名'
23 print ('Test pass.')
24 except Exception as e:
25 print ("Test fail.", format (e))
注:不同版本的火狐浏览器,定位的元素会有所不同
10.验证控件是否选中
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 # driver.implicitly_wait (6)
8 driver.get ("http://news.baidu.com/")
9 time.sleep (1)aluse
10 try:
11 # driver.find_element_by_xpath ("//*[@id='news']").is_selected ()
12 assert driver.find_element_by_xpath ("//*[@id='newstitle']").is_selected () == True
13 print ('Test Pass.')
14 except Exception as e:
15 print ('Test fail', format (e))
总结:
元素方法is_selected()返回是是布尔值(True /Faluse),用来判断单选或者多选控件是否被选中,或者下拉选择菜单是否选择一个默认的option,都可以通过这个方法去判断。
11.获取页面元素的大小
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 # driver.implicitly_wait (6)
8 driver.get ("http://baidu.com/")
9 time.sleep (1)
10 Size = driver.find_element_by_id("su")
11 print(Size.size)
12.多窗口之间的切换
场景:在页面A点击一个连接,会触发在新Tab或者新窗口打开页面B,由于之前的driver实例对象在页面A,但是你接下来的脚本是操作页面B的元素,这样就造成了找不到元素的报错。本来介绍selenium中switch_to.window()方法来处理这个问题。
测试场景:打开百度新闻(页面A),点击热点新闻中第一个新闻链接(一般是国家领导人的新闻),会在第二个窗口打开这个新闻的具体详情页(页面B),测试需要去判断你点击这个这个新闻,在打开的详情页是否正确。
问题拆分:
1. 我们已经知道switch_to.window()方法可以处理窗口切换的问题
2. 在页面A跳转到页面B之前,我们需要用一个变量保存这个新闻的标题
3. 切换到页面B后,我们获取这个新闻标题,然后和前面这个变量保存的值去对比,如果相等,那么就测试通过。
我们分两个步骤去解答这个测试需求:
1. 先实现页面A切换到页面B
2. 页面A和页面B两个新闻标题进行对比
先看看窗口切换的脚本代码:
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 driver.get ('http://news.baidu.com')
8 time.sleep (3)
9
10 driver.find_element_by_xpath ("//*[@id='pane-news']/div/ul/li[1]/strong/a").click ()
11 time.sleep (3)
12 print (driver.current_window_handle) # 输出当前窗口句柄
13 handles = driver.window_handles # 获取当前全部窗口句柄集合
14 print (handles) # 输出句柄集合
15
16 for handle in handles: # 切换窗口
17 print(handle)
18 if handle != driver.current_window_handle:
19 print(handle)
20 print ('switch to second window', handle)
21 driver.close () # 关闭第一个窗口
22 driver.switch_to.window (handle) # 切换到第二个窗口
23 print(handle)
注:通过driver.current_window_handle获取的当前窗口句柄,无论打开多少个窗口,只要不使用driver.switch_to.window()就是第一次打开的窗口。
使用driver.window_handles获取的窗口为当前打开的所有窗口。
只有driver.switch_to.window()才能切换到对应的窗口,获取窗口句柄。
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 # driver = webdriver.Chrome()
6 driver = webdriver.Firefox()
7 # driver.maximize_window ()
8 driver.get ('http://news.baidu.com')
9 time.sleep (1)
10
11 news_link = driver.find_element_by_xpath ("//*[@id='pane-news']/div/ul/li[1]/strong/a")
12 page1_title_string = news_link.text # 得到页面A新闻标题
13 print(page1_title_string)
14 news_link.click () # 点击新闻链接
15 time.sleep (1)
16 handles = driver.window_handles
17
18 for handle in handles: # 切换窗口(切换到搜狗)
19 if handle != driver.current_window_handle:
20 print( 'switch to second window', handle)
21 driver.close () # 关闭第一个窗口
22 driver.switch_to.window (handle) # 切换到第二个窗口
23 page2_title_string = driver.find_element_by_xpath ("/html/body/div[2]/div[2]/div[4]/div[2]/div/div[1]").text
24
25 print(page2_title_string)
26 # 详情页有一个原标题
27
28 try:
29 assert page1_title_string in page2_title_string # 判断页面B标题是否包含页面A标题
30 print ('Test Pass.')
31 except Exception as e:
32 print ('Test Fail')
注:
1.一般编程的过程中,要提前设置浏览器最大化,不要使用drive.maxisize_window()去设置窗口的大小。否者当浏览器窗口最大时,使用该方法浏览器就会变成最小,导致有些元素通过xpath定位失效。
2网页的title与新闻详情页的title是不一样的概念,前者通过driver.title即可获取,后者通过元素定位获取。
13.处理iframe切换
问题:发现元素定位没问题,在测试回放的过程,发现就是找不到元素报错。
由于没有找到合适的iframe网站,这里不好用代码举例,简单文字加图片来介绍。
1 driver.switch_to.frame("iframe1")
2 # 操作目标元素,这个目标元素在 iframe1里面,这里就是百度文本输入框输入文字
3 driver.switch_to.default_content()
14.处理alert弹框
1 driver.switch_to_alert().accept() # 点击弹出里面的确定按钮 2 #driver.switch_to_alert().dismiss() # 点击弹出上面的X按钮
15.获取当前页面的全部图片信息
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Chrome ()
6 driver.maximize_window ()
7 driver.implicitly_wait (6)
8 driver.get ("http://news.baidu.com")
9 time.sleep (1)
10 print(driver.find_elements_by_tag_name ("img"))
11 for image in driver.find_elements_by_tag_name ("img"):
12 print (image.text)
13 print (image.size)
14 print (image.tag_name)

运行结果:
运行结果,发现没有图片名称打印出来,说明百度新闻页面,所有图片都没有给出text这个属性,前端的妹子没有写图片的text属性
16.获取页面元素的herf属性
通过Selenium获取页面元素的某一个属性。一个元素可能有多个属性,例如 class, id, name, text, href, vale等等。这里我们举例一个爬虫中经常需要处理的链接问题:找出当前页面所有的超链接。
已百度首页为例,打印所有包含href的元素的链接
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox()
6 driver.maximize_window()
7 # driver.implicitly_wait(6)
8 driver.get("https://www.baidu.com")
9 time.sleep(1)
10 print(driver.find_elements_by_xpath("//*[@href]"))
11 for link in driver.find_elements_by_xpath("//*[@href]"):
12 print(link)
13 print(link.get_attribute('href'))
14 driver.quit()


17.如何截图并保存
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox()
6 driver.maximize_window()
7
8 driver.get("https://www.baidu.com")
9 time.sleep(1)
10
11 driver.get_screenshot_as_file("C:\\Users\\fyr\\Desktop\\新建文本文档 11(2).png")
12 time.sleep(4)
13 driver.quit()
1 # coding=utf-8
2 from selenium import webdriver
3 driver = webdriver.Firefox()
4 driver.maximize_window ()
5 driver.get("https://www.baidu.com")
6 try:
7 driver.find_element_by_id("kwf")
8 print("id is find")
9 except Exception as e:
10 print("exception find ",format(e))
11 driver.quit()
运行结果:
注:该断言判断是否获取对应的元素,再自动化脚本执行时,可以定位出现的问题
2.利用link text定位元素
1 try:
2 driver.find_element_by_link_text("新闻")
3 print ('test pass: element found by link text')
4 except Exception as e:
5 print ("Exception found", format(e))
3.利用partial link text定位元素
try:
driver.find_element_by_partial_link_text("主页").click()
print ('test pass: element found by partial link text')
except Exception as e:
print ("Exception found", format(e))
注:partial_link_text与link_text链接定位类似,partial link text就是选择这个元素的link text中一部分字段。
例如:百度首页带链接文字为:“把百度设为主页”。
为了更好的验证是否找到了“把百度添加到首页”这个元素,我在这个地方添加了一个click(),运行代码,可以看到确实点击了这个元素,代表找到了这个元素。
选择partial link text的时候,需要选择一个比较唯一的字段,来区分这个元素。
4.利用class name定位元素
1 try:
2 driver.find_element_by_class_name("s_ipt")
3 print ('test pass: element found by class name')
4 except Exception as e:
5 print ("Exception found", format(e))
5.利用name定位元素
try:
driver.find_element_by_name("wd") # 这里百度搜索输入框有name = 'wd'这个节点信息
print ('test pass: element found by name value')
except Exception as e:
print ("Exception found", format(e))
6.利用css定位元素
参考:http://blog.csdn.net/u011541946/article/details/68927139
7.清楚文本信息
1 # coding=utf-8
2 from selenium import webdriver
3 driver = webdriver.Firefox()
4 driver.maximize_window ()
5 driver.get("https://www.baidu.com")
6 driver.find_element_by_id("kw").send_keys("Selenium")
7 try:
8 driver.find_element_by_id("kw").clear()
9 driver.find_element_by_id ("kw1").send_keys ("Selenium")
10 print ('test pass: clean successful')
11 except Exception as e:
12 print ("Exception found", format(e))
13 driver.quit()
8.基本页面操作方法
driver.refresh() # 刷新方法 refresh
driver.back() # 从百度新闻后退到百度首页
driver.forward() # 百度首页前进到百度新闻
print(driver.capabilities['version']) # 打印浏览器version的值
print (driver.current_url) # current_url 方法可以得到当前页面的URL
print (driver.title) # title方法可以获取当前页面的标题显示的字段
在浏览器中新开一个界面:
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4 from selenium.webdriver.common.keys import Keys
5
6 driver = webdriver.Firefox ()
7 driver.maximize_window ()
8 # driver.implicitly_wait (6)
9
10 driver.get ("http://www.baidu.com/")
11 time.sleep (1)
12 ele = driver.find_element_by_tag_name ('body').send_keys (Keys.CONTROL + 't') # 触发ctrl + t 在浏览器中新开一个tab
13 time.sleep (1)
8.点击单选按钮-Radio Button
勾选一个单选按钮,就是调用元素方法click()
我们利用for语句遍历这两个单选按钮,依次点击他们。
1 from selenium import webdriver
2 import time
3 driver = webdriver.Firefox ()
4 driver.maximize_window ()
5 driver.get ('http://news.baidu.com')
6 # driver.implicitly_wait (8)
7 print(driver.find_elements_by_xpath ("//*/input[@type='radio']"))
8 for i in driver.find_elements_by_xpath ("//*/input[@type='radio']"):
9 i.click ()
10 time.sleep (5)
9.获取元素页面上的文字
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4 from selenium.webdriver.common.keys import Keys
5
6 driver = webdriver.Firefox ()
7 driver.maximize_window ()
8 # driver.implicitly_wait (6)
9
10 driver.get ("http://www.baidu.com/")
11 time.sleep (1)
12 driver.find_element_by_xpath ("//*[@id='u1']/a[7]").click ()
13 time.sleep (1)
14
15 driver.find_element_by_xpath ("//*[@id='TANGRAM__PSP_10__submit']").click ()
16
17
18 # 断言方法二,本文重点介绍方法
19 error_mes = driver.find_element_by_xpath ("//*[@id='TANGRAM__PSP_10__error']").text
20 print(error_mes)
21 try:
22 assert error_mes == u'请您填写手机/邮箱/用户名'
23 print ('Test pass.')
24 except Exception as e:
25 print ("Test fail.", format (e))
注:不同版本的火狐浏览器,定位的元素会有所不同
10.验证控件是否选中
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 # driver.implicitly_wait (6)
8 driver.get ("http://news.baidu.com/")
9 time.sleep (1)aluse
10 try:
11 # driver.find_element_by_xpath ("//*[@id='news']").is_selected ()
12 assert driver.find_element_by_xpath ("//*[@id='newstitle']").is_selected () == True
13 print ('Test Pass.')
14 except Exception as e:
15 print ('Test fail', format (e))
总结:
元素方法is_selected()返回是是布尔值(True /Faluse),用来判断单选或者多选控件是否被选中,或者下拉选择菜单是否选择一个默认的option,都可以通过这个方法去判断。
11.获取页面元素的大小
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 # driver.implicitly_wait (6)
8 driver.get ("http://baidu.com/")
9 time.sleep (1)
10 Size = driver.find_element_by_id("su")
11 print(Size.size)
12.多窗口之间的切换
场景:在页面A点击一个连接,会触发在新Tab或者新窗口打开页面B,由于之前的driver实例对象在页面A,但是你接下来的脚本是操作页面B的元素,这样就造成了找不到元素的报错。本来介绍selenium中switch_to.window()方法来处理这个问题。
测试场景:打开百度新闻(页面A),点击热点新闻中第一个新闻链接(一般是国家领导人的新闻),会在第二个窗口打开这个新闻的具体详情页(页面B),测试需要去判断你点击这个这个新闻,在打开的详情页是否正确。
问题拆分:
1. 我们已经知道switch_to.window()方法可以处理窗口切换的问题
2. 在页面A跳转到页面B之前,我们需要用一个变量保存这个新闻的标题
3. 切换到页面B后,我们获取这个新闻标题,然后和前面这个变量保存的值去对比,如果相等,那么就测试通过。
我们分两个步骤去解答这个测试需求:
1. 先实现页面A切换到页面B
2. 页面A和页面B两个新闻标题进行对比
先看看窗口切换的脚本代码:
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox ()
6 driver.maximize_window ()
7 driver.get ('http://news.baidu.com')
8 time.sleep (3)
9
10 driver.find_element_by_xpath ("//*[@id='pane-news']/div/ul/li[1]/strong/a").click ()
11 time.sleep (3)
12 print (driver.current_window_handle) # 输出当前窗口句柄
13 handles = driver.window_handles # 获取当前全部窗口句柄集合
14 print (handles) # 输出句柄集合
15
16 for handle in handles: # 切换窗口
17 print(handle)
18 if handle != driver.current_window_handle:
19 print(handle)
20 print ('switch to second window', handle)
21 driver.close () # 关闭第一个窗口
22 driver.switch_to.window (handle) # 切换到第二个窗口
23 print(handle)
注:通过driver.current_window_handle获取的当前窗口句柄,无论打开多少个窗口,只要不使用driver.switch_to.window()就是第一次打开的窗口。
使用driver.window_handles获取的窗口为当前打开的所有窗口。
只有driver.switch_to.window()才能切换到对应的窗口,获取窗口句柄。
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 # driver = webdriver.Chrome()
6 driver = webdriver.Firefox()
7 # driver.maximize_window ()
8 driver.get ('http://news.baidu.com')
9 time.sleep (1)
10
11 news_link = driver.find_element_by_xpath ("//*[@id='pane-news']/div/ul/li[1]/strong/a")
12 page1_title_string = news_link.text # 得到页面A新闻标题
13 print(page1_title_string)
14 news_link.click () # 点击新闻链接
15 time.sleep (1)
16 handles = driver.window_handles
17
18 for handle in handles: # 切换窗口(切换到搜狗)
19 if handle != driver.current_window_handle:
20 print( 'switch to second window', handle)
21 driver.close () # 关闭第一个窗口
22 driver.switch_to.window (handle) # 切换到第二个窗口
23 page2_title_string = driver.find_element_by_xpath ("/html/body/div[2]/div[2]/div[4]/div[2]/div/div[1]").text
24
25 print(page2_title_string)
26 # 详情页有一个原标题
27
28 try:
29 assert page1_title_string in page2_title_string # 判断页面B标题是否包含页面A标题
30 print ('Test Pass.')
31 except Exception as e:
32 print ('Test Fail')
注:
1.一般编程的过程中,要提前设置浏览器最大化,不要使用drive.maxisize_window()去设置窗口的大小。否者当浏览器窗口最大时,使用该方法浏览器就会变成最小,导致有些元素通过xpath定位失效。
2网页的title与新闻详情页的title是不一样的概念,前者通过driver.title即可获取,后者通过元素定位获取。
13.处理iframe切换
问题:发现元素定位没问题,在测试回放的过程,发现就是找不到元素报错。
由于没有找到合适的iframe网站,这里不好用代码举例,简单文字加图片来介绍。
1 driver.switch_to.frame("iframe1")
2 # 操作目标元素,这个目标元素在 iframe1里面,这里就是百度文本输入框输入文字
3 driver.switch_to.default_content()
14.处理alert弹框
1 driver.switch_to_alert().accept() # 点击弹出里面的确定按钮 2 #driver.switch_to_alert().dismiss() # 点击弹出上面的X按钮
15.获取当前页面的全部图片信息
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Chrome ()
6 driver.maximize_window ()
7 driver.implicitly_wait (6)
8 driver.get ("http://news.baidu.com")
9 time.sleep (1)
10 print(driver.find_elements_by_tag_name ("img"))
11 for image in driver.find_elements_by_tag_name ("img"):
12 print (image.text)
13 print (image.size)
14 print (image.tag_name)
运行结果:
运行结果,发现没有图片名称打印出来,说明百度新闻页面,所有图片都没有给出text这个属性,前端的妹子没有写图片的text属性
16.获取页面元素的herf属性
通过Selenium获取页面元素的某一个属性。一个元素可能有多个属性,例如 class, id, name, text, href, vale等等。这里我们举例一个爬虫中经常需要处理的链接问题:找出当前页面所有的超链接。
已百度首页为例,打印所有包含href的元素的链接
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox()
6 driver.maximize_window()
7 # driver.implicitly_wait(6)
8 driver.get("https://www.baidu.com")
9 time.sleep(1)
10 print(driver.find_elements_by_xpath("//*[@href]"))
11 for link in driver.find_elements_by_xpath("//*[@href]"):
12 print(link)
13 print(link.get_attribute('href'))
14 driver.quit()
17.如何截图并保存
1 # coding=utf-8
2 import time
3 from selenium import webdriver
4
5 driver = webdriver.Firefox()
6 driver.maximize_window()
7
8 driver.get("https://www.baidu.com")
9 time.sleep(1)
10
11 driver.get_screenshot_as_file("C:\\Users\\fyr\\Desktop\\新建文本文档 11(2).png")
12 time.sleep(4)
13 driver.quit()