目录
阴阳大论之ForkJoin&MapReduce
目录
## ForkJoin
定义
ForkJoin是Java7提供的原生多线程并行处理框架,其基本思想是将大任务分割成小任务,最后将小任务聚合起来得到结果。
- 工作窃取模式:当执行新的任务时他可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随即线程中偷一个并把它加入自己的队列中。
优缺点
优点:
- 方便的利用多核平台的计算能力实现并发任务的拆分,极大的简化了编写并发程序的琐碎工作。
- 对于该模式下的应用,不再需要处理并行事务【同步、同信、死锁、data race…。
缺点:
- 需要注意,如果拆分对象过多,短时间内将内存撑满。等待线程的CPU资源释放了,但线程对象等待时不会被垃圾回收机制回收;
实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务
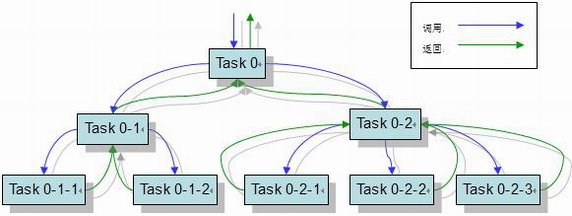
ForkJoinTask
fork方法--将任务划分成子任务的fork操作
- 决定了ForkJoinTask 的异步执行,凭借这个方法可以创建新的任务
- 调用该方法时,程序会调用push( ) 【把当前任务放在ForkJoinPool.WorkQueue[ ] 中】异步执行这个任务,然后立即返回结果。
join方法--等待这些子任务结束的join操作
- 负责计算完成后返回结果,因此允许一个任务等待另一个任务执行完成。
- 主要作用:阻塞当前线程并等待获取结果。
## MapReduce
定义
Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
- 一是数据或计算的规模相对原任务要大大缩小;
- 二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;
- 三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reducer负责对map阶段的结果进行汇总。
运行机制
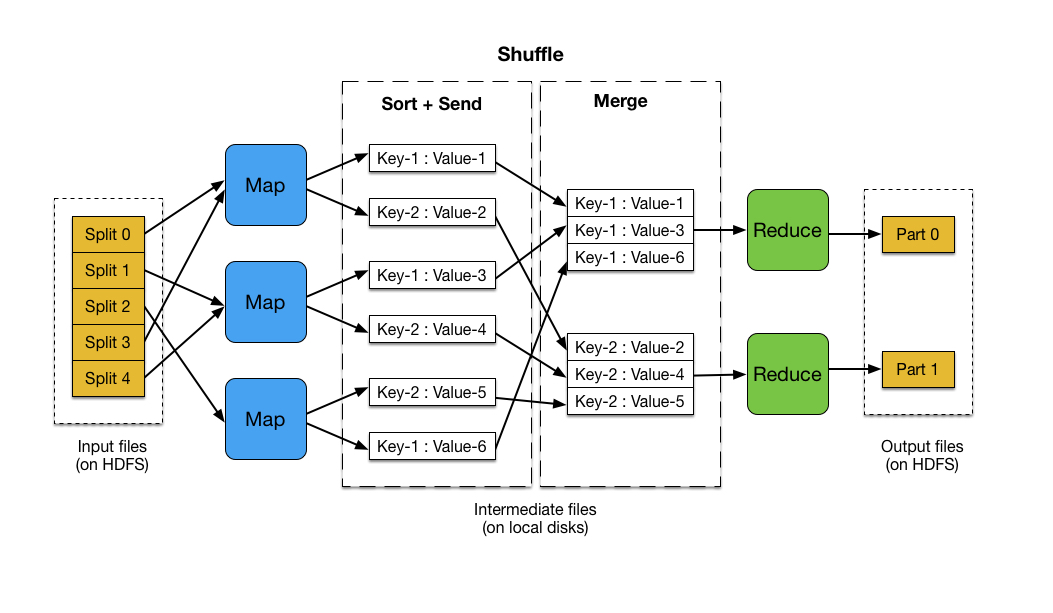
- 大规模数据集包括分布式存储和分布式计算两个核心环节,MapReduce的输入输出都需要借助分布式文件系统进行存储,这些文件被分布存储到不同的节点上
- 一个大的MapReduce作业,首先会被拆分成许多个Map认为在多台机器上并行执行,Map任务通常运行在slave节点上,这样,计算的数据就可以放在一起运行,不需要额外的传输开销,当Map任务结束后,这些结果会被分发到多个Reduce中并行执行,具有相同key的会被发送到一个Reduce,Reduce会把汇总后的结果存储到HDFS中
- Map任务之间不会进行通信,Reduce任务之间也不会有任何信息交换,用户不能显式的从一台机器向另一台机器发送信息,所有的数据交换都是通过MapReduce框架去实现
- Map的输入文件,Reduce的输出都是保存在HDFS上,Map的输出则保存在本地存储中
shuffle流程概括
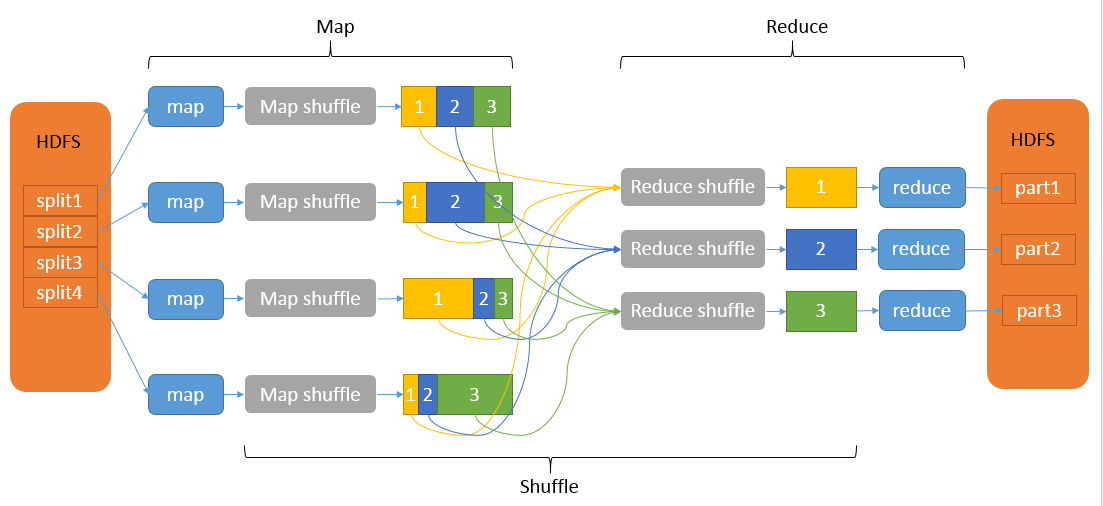
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件,分区有序的含义是map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认)
Map shuffle
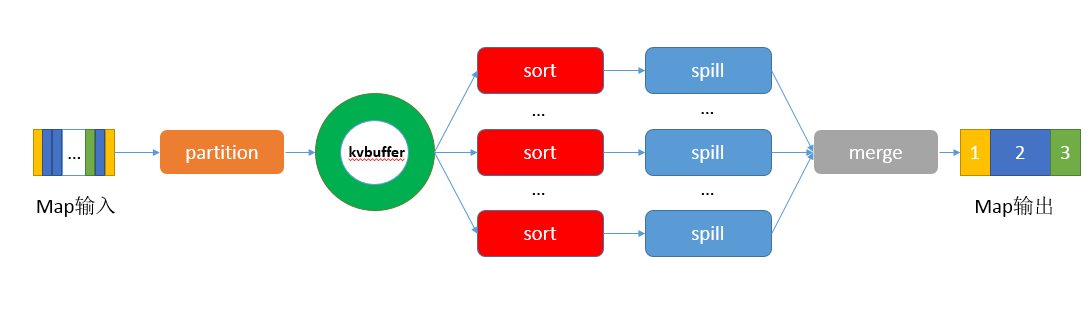
分区partition。在将map()函数处理后得到的(key,value)对写入到缓冲区之前,需要先进行分区操作,这样就能把map任务处理的结果发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜。
写入环形内存缓冲区。 因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到map节点的“环形内存缓冲区”,并做一些预排序以提高效率,当写入的数据量达到预先设置的阙值后便会执行一次I/O操作将数据写入到磁盘。每个map任务都会分配一个环形内存缓冲区,用于存储map任务输出的键值对(默认大小100MB,mapreduce.task.io.sort.mb调整)以及对应的partition,被缓冲的(key,value)对已经被序列化(为了写入磁盘)。
执行溢出写(排序sort--->合并combiner--->生成溢出写文件)。一旦缓冲区内容达到阈值(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%),就会会锁定这80%的内存,并在每个分区中对其中的键值对按键进行sort排序,具体是将数据按照partition和key两个关键字进行排序,排序结果为缓冲区内的数据按照partition为单位聚集在一起,同一个partition内的数据按照key有序。排序完成后会创建一个溢出写文件(临时文件),然后开启一个后台线程把这部分数据以一个临时文件的方式溢出写(spill)到本地磁盘中(如果客户端自定义了Combiner(相当于map阶段的reduce),则会在分区排序后到溢写出前自动调用combiner,将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量。这个过程叫“合并”)。剩余的20%的内存在此期间可以继续写入map输出的键值对。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。
合并Combiner
- 1..当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
- 2.缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用
归并merge。当一个map task处理的数据很大,以至于超过缓冲区内存时,就会生成多个spill文件。此时就需要对同一个map任务产生的多个spill文件进行归并生成最终的一个已分区且已排序的大文件。配置属性mapreduce.task.io.sort.factor控制着一次最多能合并多少流,默认值是10。这个过程包括排序和合并(可选),归并得到的文件内键值对有可能拥有相同的key,这个过程如果client设置过Combiner,也会合并相同的key值的键值对(根据上面提到的combine的调用时机可知)。
压缩。写磁盘时压缩map端的输出,因为这样会让写磁盘的速度更快,节约磁盘空间,并减少传给reducer的数据量。默认情况下,输出是不压缩的(将mapreduce.map.output.compress设置为true即可启动)
Reduce shuffle
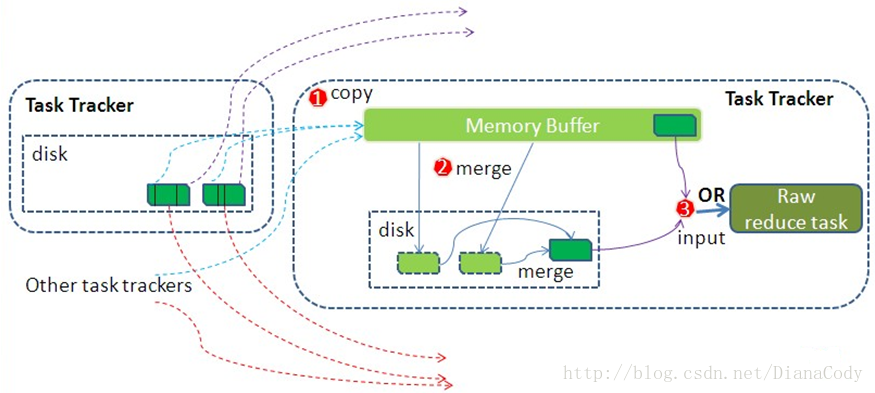
- educe任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
- Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。
- 在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。