吴恩达ML课程课后总结,以供复习、总结、温故知新,也欢迎诸位评论讨论分享,一起探讨一起进步:
上一篇:机器学习(4)--前向神经网络及BP算法 python实现(附练习数据资源文件百度云)https://blog.csdn.net/qq_36187544/article/details/88300086
下一篇:机器学习(6)--支持向量机SVMhttps://blog.csdn.net/qq_36187544/article/details/88365165
写在前面的总结:
利用学习曲线和误差分析诊断现有的模型,判断高偏差还是高方差再进行处理,不要盲目优化!
训练出来的模型不是一次性就完美的,容易问题很大,拟合的不好或过拟合采用的方法:
1.扩大训练集,更多数据
2. 增加或减少特征数量
3.改变特征多项式,如增加x^3等
4. 减少或增加λ
选取相对较好的模型,核心就是训练集,验证集和测试集:
一般把数据7:3 分成训练集和测试集
为了选择模型等,将数据6:2:2分为训练,交叉验证或验证,测试集,选择不同的模型计算对应的参数θ计算其验证集误差J(θ) ,最小的作为最好的模型,而测试集来测试误差
偏差和方差评价欠拟合和过拟合,高偏差对应欠拟合的情况,高方差对应过拟合的情况:
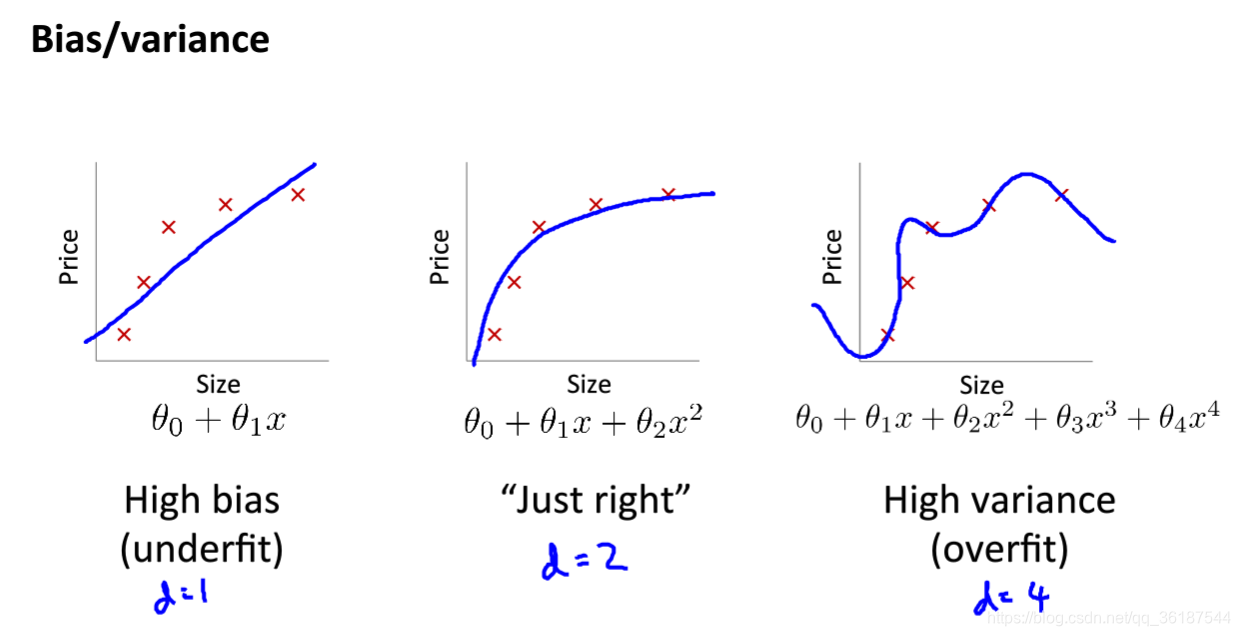
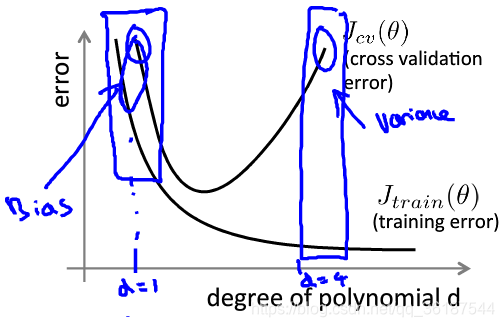
训练集误差和验证集误差的图中,左侧为高偏差,欠拟合,二者的误差都大,右侧为高方差,过拟合,训练集误差小,验证集误差大(Jcv表示交叉验证集,Jtrain表示训练集,d表示特征数)
正则化对方差、偏差的影响:正则化对模型的影响,λ过大高偏差,λ过小高方差。注意:正则化参数λ在验证和测试时不带正则化项即计算Jθ时不带正则化项

绘制λ与误差图像:随着λ的增大,验证集的误差先减少后增大,而训练集误差逐步增大,由高方差变为高偏差,选取适当的λ很重要

学习曲线诊断:
m训练样本数量为横坐标,error误差作为纵坐标,训练集的误差随m增大而增大,验证集误差随m增大而减小。
高偏差时m较大时训练集和验证集误差接近,趋于水平。所以高偏差时增加训练集样本数量没有意义。(中图)
高方差时m较大时训练集和验证集误差相差较大,增加训练集样本数是很好的方法(右图)



优化算法模型的方案:
1.扩大训练集,更多数据(可修复高方差)
2. 增加特征数量(可修复高方差)
3.减少特征数量(可修复高偏差)
4.改变特征多项式,如增加x^3等(可修复高偏差)
5. 减少λ(可修复高偏差)
6.增加λ(可修复高方差)
一个实用的建议:
多层复杂的神经网络易过拟合,采用正则化λ调整
误差分析(除了学习曲线外另一个有效的方法):
使用验证集中被错误分类的数据进行分析,找其错误的共同点和特征,简单点说,就是手动检查错误。举了一个垃圾邮件分类的例子,就是去检查错误分类的邮件,然后判断由于药厂,由于来源,由于标点符号等造成的影响,再致力于一方面深入下去。
所以推荐先实现一个算法,找到不易处理的样本类型等,再不断改进,因为高效。
评判标准就是查看检查验证集的正确率有没有提高
偏斜类的问题:
正例与负例的比例较极端,比如正例有1000数据,而负例只有10个数据,这种情况下会总是得到1,也就是说预测总是偏向于1,测不出负例情况的正确性(刚遇到这种情况,测试集测试的时候全部输出一种值,总体正确率80%,但是负例正确率0%)
提出查准率和召回率检测算法的优劣(第一次写的时候就注意到分类别计算比例,这运气)。
二分类中,
查准率指真阳性(通过算法得到的值和实际值都是y=1)/所有预测y=1的数据(就是预测y=1的时候的正确率,越高越好,说明预测的准)
召回率指真阳性/实际上y=1的数据(就是实际y=1时正确率,越高越好,说明测出来的多)
一般来讲,查准率和召回率是相悖的,为此,需要平衡召回率和查准率来优化算法:
1.如果需要精确的1需要高查准率,比如在癌症判断中1代表有癌症,需要精确(这种情况下就是精确判断有癌症,不误判),可以将logistics函数的阈值由0.5变为0.7等(函数不一样阈值不一样,举例)
2.如果需要高召回率,1代表患有癌症,需要让有可能有癌症的人都注意起来(这种情况放弃查准率,提高查出来的比率,这样不会漏查让患癌的人以为没有患病),同样可以调整阈值(临界值),调低
可通过F值来判断算法查准率(P)和召回率(S)
F=PS/(S+P),较高的F算法性能较好,内涵在于提高较小值的权重,分析较全面。当然,其实按需求最重要
数据的重要性:随着数据量的提升,无论什么算法都会让模型更加优秀,所以“不是拥有最好算法的人获胜,而是最多数据的人”
首先,人类专家看到了很多特征,当特征足够,数据量足够,就算没有最好的算法,也能有低方差,低误差的模型,预测很准
就上一篇文章中神经的网络模型训练的数据是偏斜类数据,验证部分的源码为:
y_equal_1_right = 0 # 正确值是y=1时正确的个数
y_equal_1_wrong = 0 # 正确值是y=1时错误的个数
y_equal_0_right = 0 # 正确值是y=0时正确的个数
y_equal_0_wrong = 0 # 正确值是y=0时错误的个数
logis_line = 0.7 # 逻辑回归阈值
for i in range(len(x)):
if y[i] == 1:
if nn.predict((x[i]-mean)/std) >logis_line:
y_equal_1_right+=1
else:
y_equal_1_wrong+=1
else:
if nn.predict((x[i]-mean)/std)<logis_line:
y_equal_0_right+=1
else:
y_equal_0_wrong+=1
print("正确答案y=1时,正确的个数:"+str(y_equal_1_right)+",错误的个数:"+str(y_equal_1_wrong)+",正确率:"+str(y_equal_1_right/(y_equal_1_right+y_equal_1_wrong)))
print("正确答案y=0时,正确的个数:"+str(y_equal_0_right)+",错误的个数:"+str(y_equal_0_wrong)+",正确率:"+str(y_equal_0_right/(y_equal_0_right+y_equal_0_wrong)))
print("总计正确:"+str(y_equal_0_right+y_equal_1_right)+",错误:"+str(y_equal_0_wrong+y_equal_1_wrong)+",正确率:"+str((y_equal_0_right+y_equal_1_right)/(y_equal_0_right+y_equal_0_wrong+y_equal_1_right+y_equal_1_wrong)))
采用逻辑回归分类阈值是0.5时得到的结果,因为整体数据y=0的数据居多,所以偏向y=0:

阈值0.7时,完全偏向y=0,如果需求情况是y=0的情况要尽可能查出来结果这种阈值时可以的:

阈值0.3时,结果逐步偏向y=1:

阈值0.1时:

可以计算F值,但是这样的测试已经够足了,说明偏斜类的问题的解法应当是这样去操作,改变阈值