在指定网页中,某个关键词出现的次数除以该网页长度称为该关键词在此网页中的词频。对新闻类网页,存在一组的关键词。因此,每个新闻页都存在一组词频,称为该新闻网页的特征向量。
设两个新闻网页的特征向量分别为:甲(a1 ,a2,.... ak)、乙(b1 ,b2,.... bk),则计算这个网页的相似度时需先计算它们的内积S=a1b1+a2b2+.....+akbk。一般情况下,新闻网页特征向量的维数时巨大的,但每个特征向量中非零元素却并不多。为了节省存储空间和计算时间,我们依次用特征向量中非零元素的序号及相应词频值来简化特征向量。为此,
我们用(NA(i),A(i)| i=1,2,…,m)和(NB(j),B(j)| j=1,2,…,n)来简化两个网页的特征向量。其中:NA(i)从前到后描述了特征向量甲中非零元素A(i)的序号(NA(1)<NA(2)<…),NB(j))从前到后描述了特征向量乙中非零元素B(j)的序号(NB(1)<NB(2)<…)。
下面的流程图描述了计算这两个特征向量内积S的过程。(题来自软考2014上)
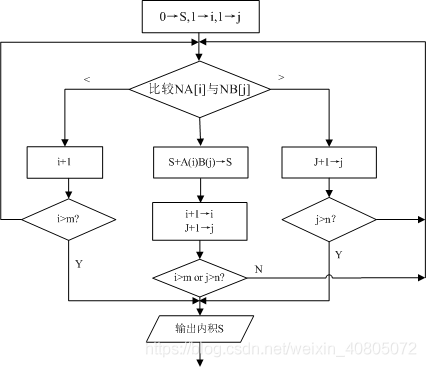
(1)处,由题目信息和最终输出,可以得知,流程图得S代表特征向量内积和,所以S 的初值为0
(2)处,由S=a1b1+a2b2+…+akbk 得,S=S+A(i)*B(j),所以填S+A(i)*B(j)
(3)处,分析流程图得要正常计算内积必须保证i=j,当NA[i]<NB[J]时,j不变,i加1。此时正常来说应该用新的i值接着计算内积,但是特征向量中非零元素个数时有限的,无论如何i的值不能超出最大值m,所以此处应该判断是否越界,填入i>m?
同理可得(4)处应填,j>n?
(5)处,分析流程图得知,流程图中间部分是用来正常计算内积的,从(2)下去,自增后,应当判断是否计算完成,作为结束条件。计算结束意味着其中有一个简化向量结束,即NA(i)或NB(j)结束,此处应填i>m or j>n
—————————————————————————————————————————————————————
附:(答案中的一些描述)
世界上有大量的新闻网页,门户网站需要将其自动进行分类,并传送给搜索的用户。为了分类,需要建立相似度衡量方法。流行的算法是,先按统一的关键词组计算各个关键词的词频,形成网页的特征向量,这样,两个网页特征向量的夹角余弦(内积/两个向量模具的乘积),就可以衡量两个网页的相似度。因此,计算两个网页特征向量的内积就是分类计算中的关键。
对于存在大量零元素的稀疏向量来说,题中的简化表示方法很有效。
(1)0
(2)S+A(i)B(j)
(3) i>m 或i=m+1或等价表示
(4)j>n或j=n+1或等价表示
(5)i>m or i=m+1 或 i=m+1 or j=n+1