python序列化与反序列
在python中提供了两个模块可进行序列化。分别是pickle和json。他们两者的功能都差不多,dumps和dump都是进行序列化,而loads和load则是反序列化。
模块1:pickle
pickle是python中独有的序列化模块。有个特别的名字,为泡菜。用于实现Python数据类型与Python特定二进制格式之间的转换。
1. .dumps()和.loads()为格式处理函数
import pickle
#序列化 d = dict(name='Bob', age=20, score=88) c = pickle.dumps(d) #dumps将所传入的变量的值序列化为一个bytes, 就可以将这个bytes写入磁盘或者进行传输。 print(c)
#反序列化
c1 = pickle.loads(c) #把bytes loads为python对象 print((c1))
运行结果:
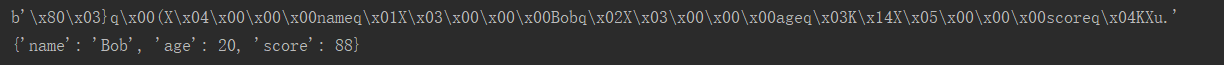
2..dump()和.load()主要用来读写json文件函数
import pickle #写 f = open('2.txt','wb') d = dict(name='Bob', age=20, score=88) pickle.dump(d,f) #以二进制文件写入2.txt中 print(d) f.close() #读 f1 = open('2.txt','rb') r = pickle.load(f1) #读出文件内容 print(r)
这里就不上图了。
模块2:json
大部分编程语言都会提供处理json数据的接口,用于实现Python数据类型与通用(json(其他编程语言))字符串之间的转换
直接上源码
1.json.dumps()和json.loads()是json格式处理函数
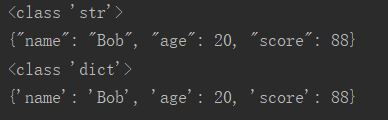
import json #序列化 d = dict(name='Bob', age=20, score=88) d1 = json.dumps(d) #dumps方法是把pyhon对象转化为json对象 (转为字符串) print(type(d1)) print(d1) #反序列化 d2 = json.loads(d1) #loads方法是把json对象转化为python对象 (字符串转为python对象) print(type(d2)) print(d2)
运行结果:
2.json.dump()和json.load()主要用来读写json文件函数
import json #写操作 json_info = "{'name': 'Bob', 'age': 20, 'score': 88}" #字符串 也可以是上面代码的d2变量 file = open('1.json','w',encoding='utf-8') #创建(打开)一个可写的1.json文件 json.dump(json_info,file) #将json信息写入文件中 #读操作 file = open('1.json','r',encoding='utf-8') info = json.load(file) #读取json信息 print(info)
这里我就不上图了 都差不多的
总结:
pickle与json都可以实现序列化以及反序列化,它们之间不同的有以下几点:
1)、pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化,只针对python的数据类型;而json可以支持更多语言的序列化和反序列化,在python中序列化一个自定义的类对象时,会抛出一个 TypeError。
2)、json的序列化输出是文本对象是str类型,而pickle序列化的输出是二进制字节-bytes。
3)、json可读性优于pickle。