在ActiveMQ、RabbitMQ、RocketMQ、Kafka消息中间件之间,我们为什么要选择Kafka?
下面详细介绍一下,2012年9月份我在支付宝做余额宝研发,2013年6月支付宝正式推出余额宝,2013年8月担任支付宝淘宝彩票项目经理带领兄弟们一起做研发,期间需要与淘宝和500万对接竞彩接口数据。
通过业余时间与淘宝同事沟通,了解到天猫在电商节如何处理大数据?技术架构上采用了哪些策略?
1、应用无状态(淘宝session框架)
2、有效使用缓存(Tair)
3、应用拆分(HSF)
4、数据库拆分(TDDL)
5、异步通信(Notify)
6、非结构化数据存储 ( TFS,NOSQL)
7、监控、预警系统
8、配置统一管理
天猫的同事把大致的架构跟我描述了一番,心有感悟。咱们来看一下2018年双11当天的成交额。

二、kafka实现天猫亿万级数据统计架构
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
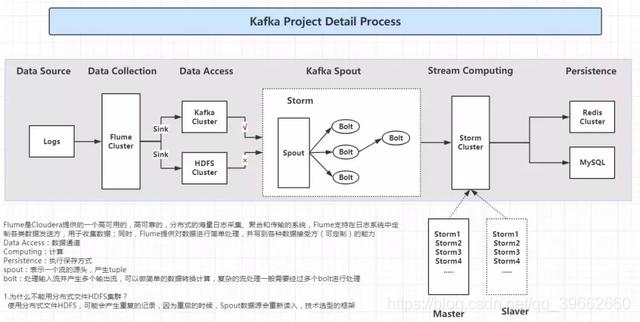
Data Access:数据通道
Computing:计算
Persistence:执行保存方式
spout:表示一个流的源头,产生tuple
bolt:处理输入流并产生多个输出流,可以做简单的数据转换计算,复杂的流处理一般需要经过多个bolt进行处理。
为什么不能用分布式文件HDFS集群?
1、实时性:hdfs的实时性没有kafka高。
2、消费量的记录:hdfs不会记录你这个块文件消费到了哪里,而基于zookeeper的kafka会记录你消费的点。
3、并发消费:hdfs不支持并发消费,而kafka支持并发消费,即多个consumer。
4、弹性且有序:当数据量会很大,而且处理完之后就可以删除时,频繁的读写会对hdfs中NameNode造成很大的压力。而kafka的消费点是记录在zookeeper的,并且kafka的每条数据都是有“坐标”的,所以消费的时候只要这个“坐标”向后移动就行了,而且删除的时候只要把这个“坐标”之前的数据删掉即可。
三、什么是Kafka?
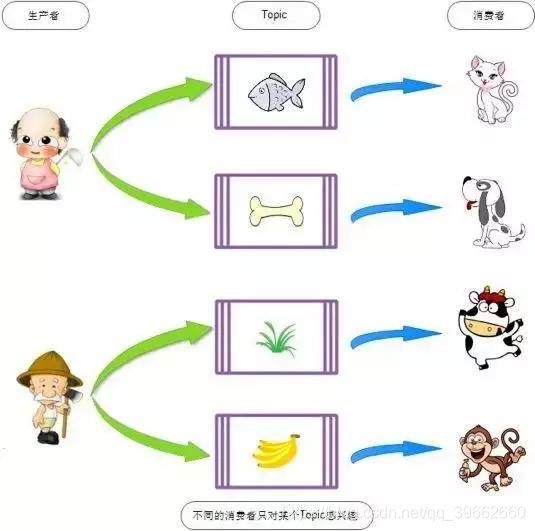
通过上图就可以了解到,生产者Producers(农民和厨师),消费主题top(鱼,骨头,草,香蕉),消费者Comsumer(猫,狗,老牛,猴子),生产者根据消费主题获取自己想要的食物。
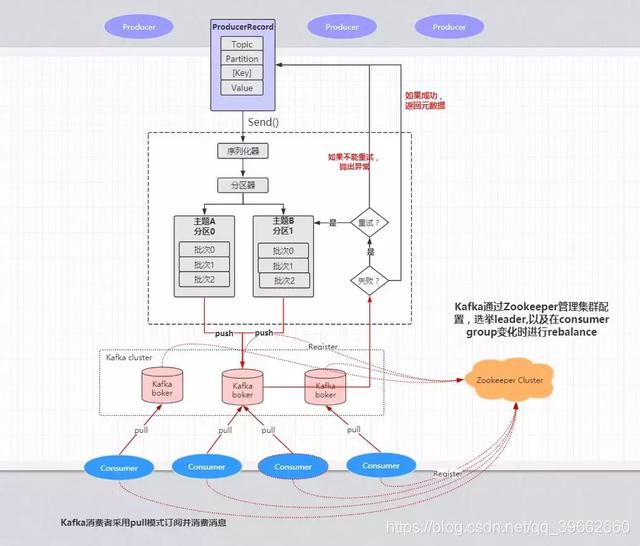
四、Kafka架构原理
欢迎加入Java进阶架构交流:加入142019080。
直接点击链接加群。https://jq.qq.com/?_wv=1027&k=5lXBNZ7 获取最新学习资料