1、Redis简介
简介:Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使
用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构
的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据
类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
2、下载安装
A、下载地址 https://github.com/MSOpenTech/redis/releases
B、下载后,解压到磁盘目录即安装成功。Redis Windows版属于免安装版。

3、启动服务
启动服务器命令:打开一个 cmd 窗口 使用cd命令切换到安装目录,运行 redis-server.exe redis.windows.conf ,即可启动。Conf文件为默认文件,可以根据需要修改。

链接服务器命令:切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 –raw
退出链接命令:quit
参数解释:127.0.0.1为主机IP地址,6379为端口,–raw为设置dos支持中文
乱码问题:A,加—raw
B,设置字符集在控制台中输入命令CHCP 65001即可
C,在新弹出的窗口选择【字体】选项卡 ,然后在下面的字体里选择【Lucida Console】
这个字体
4、Redis常用命令
key相关命令
(1)设置key: set keyName keyValue;
(2)删除key:del keyName;
(3)序列化key:dump keyName;
(4)检查key是否存在:exists keyName; 存在返回1,不存在返回0。
(5)获得key:get keyName;
(6)删除所有key: flushall

字符串相关命令
(1)设置字符串: set StrName StrValue;
(2)删除字符串:del StrName;
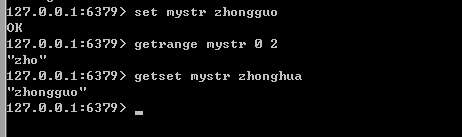
(3)截取字符串:GETRANGE StrName start end ;
(4)字符串重新赋值: GETSET key value ; 返回老字符串的值
哈希(Hash)相关命令
Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
(1)设置一个hash对象:hmset HashName field value[field vaule ……];
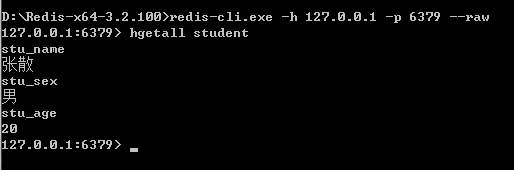
(2)获取Hash对象:hgetall Hashname;
(3)获取Hash中的一个属性:hget HashName field;
(4)查看Hash中的属性是否存在:hexists HashName field;
(5)删除Hash中的属性:hdel HashName field;

列表(List)相关命令
列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
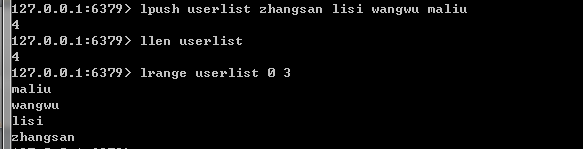
(1)创建List并添加元素:lpush/rpush ListName strValue[ strVaule ……] ;
(2)获取List长度:llen ListName;
(3)通过索引获取元素:lindex ListName index;
(4)通过索引设置某个元素的值:lset ListName index value;
(5)移出并获取列表的第一个元素:LPOP ListName;
(6)移出并获取列表最后一个元素:RPOP ListName;
(7)获取列表指定范围内的元素:LRANGE ListName start stop
(8)对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除:LTRIM ListName start stop
有序集合相关命令
Redis 有序集合(sorted set)和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
(1)向有序集合添加一个或多个成员,或者更新已存在成员的分数: ZADD setName score1 member1 [score2 member2];
(2)获取有序集合的成员数: ZCARD setName ;
(3)计算在有序集合中指定区间分数的成员数: ZCOUNT setName min max ;
(4)通过索引区间返回有序集合成指定区间内的成员: ZRANGE key start stop [WITHSCORES];
(5)通过字典区间返回有序集合的成员: ZRANGEBYLEX setName min max [LIMIT offset count];
(6)移除有序集合中的一个或多个成员: ZREM setName member [member …];
注意【索引】【指定区间】不是分数,是下标参数,下表参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。
你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。

HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
基数:比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
(1)添加指定元素到 HyperLogLog 中: PFADD key element [element …]
(2)返回给定 HyperLogLog 的基数估算值: PFCOUNT key [key …]
(3)将多个 HyperLogLog 合并为一个 HyperLogLog: PFMERGE destkey sourcekey [sourcekey …]

5、Redis备份与恢复
备份数据库:save / bgsave 该命令将在 redis 安装目录中创建dump.rdb文件;
恢复数据库: 如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。
获取 redis 目录可以使用 CONFIG 命令
6、Redis经典应用场景
(1)会话缓存(session):防止会话数据丢失,快速获得会话信息;
页面缓存:回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进;
(2)队列排序、排行榜等:Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构;
(3)发布订阅:发布/订阅的使用场景确实非常多。社交网络连接中,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统;
(4)最新最近记录类似场景:在Web应用中,“列出最新的回复”之类的查询非常普遍,这通常会带来可扩展性问题。这令人沮丧,因为项目本来就是按这个顺序被创建的,但要输出这个顺序却不得不进行排序操作。在Redis中我们的最新ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
(5)计数:Redis是一个很好的计数器,这要感谢INCRBY和其他相似命令。我相信你曾许多次想要给数据库加上新的计数器,用来获取统计或显示新信息,但是最后却由于写入敏感而不得不放弃它们。好了,现在使用Redis就不需要再担心了。有了原子递增(atomic increment),你可以放心的加上各种计数,用GETSET重置,或者是让它们过期。
特定时间内的特定项目:另一项对于其他数据库很难,但Redis做起来却轻而易举的事就是统计在某段特点时间里有多少特定用户访问了某个特定资源。传统数据库却需要每次都要更新。