版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_30241709/article/details/88017545
目录
关于Nesterov Accelerated Gradient
多层感知机(MLP)的softmax多分类
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
import keras
import numpy as np
# 生成虚拟数据
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.fit(x_train, y_train, epochs=20, batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
print("score: ", score)运行结果:
Using TensorFlow backend.
Epoch 1/20
2019-02-28 10:37:16.147684: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
128/1000 [==>...........................] - ETA: 0s - loss: 2.4224 - acc: 0.0859
1000/1000 [==============================] - 0s 149us/step - loss: 2.3773 - acc: 0.1000
Epoch 2/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3494 - acc: 0.0703
1000/1000 [==============================] - 0s 11us/step - loss: 2.3454 - acc: 0.0870
Epoch 3/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3077 - acc: 0.1094
1000/1000 [==============================] - 0s 11us/step - loss: 2.3437 - acc: 0.0870
Epoch 4/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3307 - acc: 0.0938
1000/1000 [==============================] - 0s 11us/step - loss: 2.3364 - acc: 0.0980
Epoch 5/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3100 - acc: 0.1094
1000/1000 [==============================] - 0s 10us/step - loss: 2.3171 - acc: 0.1100
Epoch 6/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3120 - acc: 0.1172
1000/1000 [==============================] - 0s 11us/step - loss: 2.3188 - acc: 0.1040
Epoch 7/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3345 - acc: 0.0859
1000/1000 [==============================] - 0s 12us/step - loss: 2.3167 - acc: 0.1030
Epoch 8/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3246 - acc: 0.0625
1000/1000 [==============================] - 0s 11us/step - loss: 2.3150 - acc: 0.0970
Epoch 9/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3137 - acc: 0.1562
1000/1000 [==============================] - 0s 11us/step - loss: 2.3083 - acc: 0.1070
Epoch 10/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2797 - acc: 0.0781
1000/1000 [==============================] - 0s 12us/step - loss: 2.3075 - acc: 0.1090
Epoch 11/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3197 - acc: 0.1016
1000/1000 [==============================] - 0s 11us/step - loss: 2.3028 - acc: 0.1030
Epoch 12/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2950 - acc: 0.1250
1000/1000 [==============================] - 0s 11us/step - loss: 2.2958 - acc: 0.1240
Epoch 13/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2962 - acc: 0.1172
1000/1000 [==============================] - 0s 11us/step - loss: 2.3070 - acc: 0.1080
Epoch 14/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2960 - acc: 0.1016
1000/1000 [==============================] - 0s 12us/step - loss: 2.3027 - acc: 0.1070
Epoch 15/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2930 - acc: 0.1172
1000/1000 [==============================] - 0s 11us/step - loss: 2.2939 - acc: 0.1260
Epoch 16/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3049 - acc: 0.1016
1000/1000 [==============================] - 0s 11us/step - loss: 2.3043 - acc: 0.1080
Epoch 17/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3016 - acc: 0.0703
1000/1000 [==============================] - 0s 11us/step - loss: 2.3060 - acc: 0.1000
Epoch 18/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2788 - acc: 0.1328
1000/1000 [==============================] - 0s 11us/step - loss: 2.2954 - acc: 0.1190
Epoch 19/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.2863 - acc: 0.1641
1000/1000 [==============================] - 0s 11us/step - loss: 2.2952 - acc: 0.1210
Epoch 20/20
128/1000 [==>...........................] - ETA: 0s - loss: 2.3144 - acc: 0.0625
1000/1000 [==============================] - 0s 10us/step - loss: 2.2917 - acc: 0.1150
100/100 [==============================] - 0s 259us/step
score: [2.301650047302246, 0.05999999865889549]其中SGD为随机梯度下降优化器, Stochastic Gradient Descent。
四个参数:
- lr:学习率
- momentum:动量优化的momentum参数,用于加速SGD在相关方向上前进,并抑制震荡
- decay:每次更新后学习率的衰减值
- nesterov:boolean,是否适用Nesterov动量
关于Momentum
SGD在ravines的情况下容易被困住(ravines就是曲面的一个方向比另一个方向更陡),这时SGD会发生震荡而迟迟不能接近极小值:

Momentum通过加入可以加速SGD,并且抑制震荡:
加入这一项,可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减少震荡
超参数的设定:一般取左右
关于Nesterov Accelerated Gradient
用来近似作为下一步会变成的值,则在计算梯度时,不是在当前的位置,而是在未来的位置上:
超参数的设定值:一般取左右
效果比较:

蓝色是Momentum的过程,会计算当前的梯度,然后再更新后的累积梯度后会有一个大的跳跃。
NAG (Nesterov Accelerated Gradient)会在前一步累积的梯度上(灰色)有一个大的跳跃,然后衡量一下梯度做一下修正(红色),这种预期的更新可以避免我们走的太快。
基于多层感知器的二分类
# 生成虚拟数据
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add((Dense(1, activation='sigmoid')))
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=128, epochs=20)
score = model.evaluate(x_test, y_test, batch_size=128)
print("score: ", score)结果:
Using TensorFlow backend.
Epoch 1/10
2019-02-28 14:24:11.425481: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
128/1000 [==>...........................] - ETA: 1s - loss: 0.7517 - acc: 0.5078
1000/1000 [==============================] - 0s 186us/step - loss: 0.7252 - acc: 0.5090
Epoch 2/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7346 - acc: 0.4609
1000/1000 [==============================] - 0s 10us/step - loss: 0.7191 - acc: 0.4820
Epoch 3/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.6853 - acc: 0.5078
1000/1000 [==============================] - 0s 10us/step - loss: 0.7109 - acc: 0.4860
Epoch 4/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.6962 - acc: 0.5000
1000/1000 [==============================] - 0s 11us/step - loss: 0.7083 - acc: 0.4890
Epoch 5/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.6950 - acc: 0.5391
1000/1000 [==============================] - 0s 10us/step - loss: 0.7050 - acc: 0.4990
Epoch 6/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7180 - acc: 0.4609
1000/1000 [==============================] - 0s 10us/step - loss: 0.7037 - acc: 0.5040
Epoch 7/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7023 - acc: 0.4453
1000/1000 [==============================] - 0s 10us/step - loss: 0.7014 - acc: 0.4850
Epoch 8/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7039 - acc: 0.5000
1000/1000 [==============================] - 0s 10us/step - loss: 0.6987 - acc: 0.5040
Epoch 9/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7013 - acc: 0.5078
1000/1000 [==============================] - 0s 10us/step - loss: 0.6934 - acc: 0.5360
Epoch 10/10
128/1000 [==>...........................] - ETA: 0s - loss: 0.7071 - acc: 0.4922
1000/1000 [==============================] - 0s 10us/step - loss: 0.6983 - acc: 0.5210
100/100 [==============================] - 0s 279us/step
score: [0.6979394555091858, 0.4399999976158142]类似VGG的卷积神经网络
关于VGG
Karen Simonyan & Andrew Zisserman的VGG网络结构:
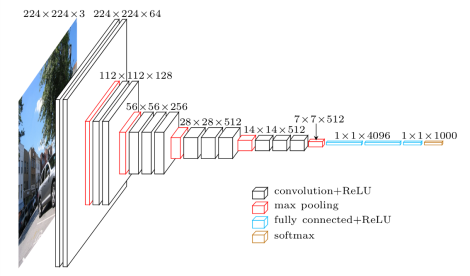
# 生成虚拟数据
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
print("score:", score)结果:
Using TensorFlow backend.
Epoch 1/10
2019-02-28 14:50:59.772493: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
32/100 [========>.....................] - ETA: 6s - loss: 2.2790
64/100 [==================>...........] - ETA: 2s - loss: 2.3399
96/100 [===========================>..] - ETA: 0s - loss: 2.3195
100/100 [==============================] - 7s 72ms/step - loss: 2.3264
Epoch 2/10
32/100 [========>.....................] - ETA: 4s - loss: 2.3259
64/100 [==================>...........] - ETA: 2s - loss: 2.2703
96/100 [===========================>..] - ETA: 0s - loss: 2.3011
100/100 [==============================] - 6s 61ms/step - loss: 2.3065
Epoch 3/10
32/100 [========>.....................] - ETA: 4s - loss: 2.2935
64/100 [==================>...........] - ETA: 2s - loss: 2.2876
96/100 [===========================>..] - ETA: 0s - loss: 2.2873
100/100 [==============================] - 6s 62ms/step - loss: 2.2882
Epoch 4/10
32/100 [========>.....................] - ETA: 4s - loss: 2.2825
64/100 [==================>...........] - ETA: 2s - loss: 2.2777
96/100 [===========================>..] - ETA: 0s - loss: 2.2668
100/100 [==============================] - 6s 62ms/step - loss: 2.2689
Epoch 5/10
32/100 [========>.....................] - ETA: 4s - loss: 2.3120
64/100 [==================>...........] - ETA: 2s - loss: 2.2865
96/100 [===========================>..] - ETA: 0s - loss: 2.2830
100/100 [==============================] - 6s 62ms/step - loss: 2.2771
Epoch 6/10
32/100 [========>.....................] - ETA: 4s - loss: 2.3145
64/100 [==================>...........] - ETA: 2s - loss: 2.2907
96/100 [===========================>..] - ETA: 0s - loss: 2.2718
100/100 [==============================] - 6s 62ms/step - loss: 2.2757
Epoch 7/10
32/100 [========>.....................] - ETA: 4s - loss: 2.2969
64/100 [==================>...........] - ETA: 2s - loss: 2.2606
96/100 [===========================>..] - ETA: 0s - loss: 2.2733
100/100 [==============================] - 6s 62ms/step - loss: 2.2728
Epoch 8/10
32/100 [========>.....................] - ETA: 4s - loss: 2.2306
64/100 [==================>...........] - ETA: 2s - loss: 2.2661
96/100 [===========================>..] - ETA: 0s - loss: 2.2564
100/100 [==============================] - 6s 62ms/step - loss: 2.2579
Epoch 9/10
32/100 [========>.....................] - ETA: 4s - loss: 2.2718
64/100 [==================>...........] - ETA: 2s - loss: 2.2901
96/100 [===========================>..] - ETA: 0s - loss: 2.2900
100/100 [==============================] - 6s 62ms/step - loss: 2.2870
Epoch 10/10
32/100 [========>.....................] - ETA: 4s - loss: 2.3367
64/100 [==================>...........] - ETA: 2s - loss: 2.2874
96/100 [===========================>..] - ETA: 0s - loss: 2.2905
100/100 [==============================] - 6s 62ms/step - loss: 2.2886
20/20 [==============================] - 0s 20ms/step
score: 2.2975594997406006本程序模型结构:
- 输入:100*100*3的数据
- 第一层:使用了32个3*3的卷积核,则第一层的大小为:98*98*32
- 第二层:使用了32个3*3的卷积核,则第二层的大小为:96*96*32
- 第三层:使用了2*2的最大池化,则第三层大小为:95*95*32
- 第四层:使用了64个3*3的卷积核,则第四层的大小为:93*93*64
- 第五层:使用了64个3*3的卷积核,则第五层的大小为:91*91*64
- 第六层:使用了2*2的最大池化, 则第六层的大小为:90*90*64
- 第七层:全连接层,256个神经元
- 输出层:全连接层,10个神经元,分别对应数据的10个类别
关于卷积和池化结果的计算公式
卷积结果:
- 卷积核个数
- 卷积核大小
- 步长
- 填充
卷积过后的大小为:
池化结果:
- 池化大小
- 步长
池化后的大小为: