Prepare the topics and the input data
Assume that you installed confluent platform quickstart and have already started all of services.
In this section we will use built-in CLI tools to manually write some example data to Kafka. In practice, you would rather rely on other means to feed your data into Kafka, for instance via Kafka Connect if you want to move data from other data systems into Kafka, or via Kafka Clients from within your own applications.
We will now send some input data to a Kafka topic, which will be subsequently processed by a Kafka Streams application.
First, we need to create the input topic, named streams-plaintext-input, and the output topic, named streams-wordcount-output:
# Create the input topic
kafka-topics --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
# Create the output topic
kafka-topics --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output
Next, we generate some input data and store it in a local file at /tmp/file-input.txt:
echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > /tmp/file-input.txt
The resulting file will have the following contents:
all streams lead to kafka
hello kafka streams
join kafka summit
Lastly, we send this input data to the input topic:
cat /tmp/file-input.txt | ./bin/kafka-console-producer --broker-list localhost:9092 --topic streams-plaintext-input
The Kafka console producer reads the data from STDIN line-by-line, and publishes each line as a separate Kafka message to the topic streams-plaintext-input, where the message key is null and the message value is the respective line such as all streams lead to kafka, encoded as a string.
kafka-console-consumer --bootstrap-server localhost:9092 --topic streams-plaintext-input --from-beginning
Steup Intellij for application development
Create a new maven project

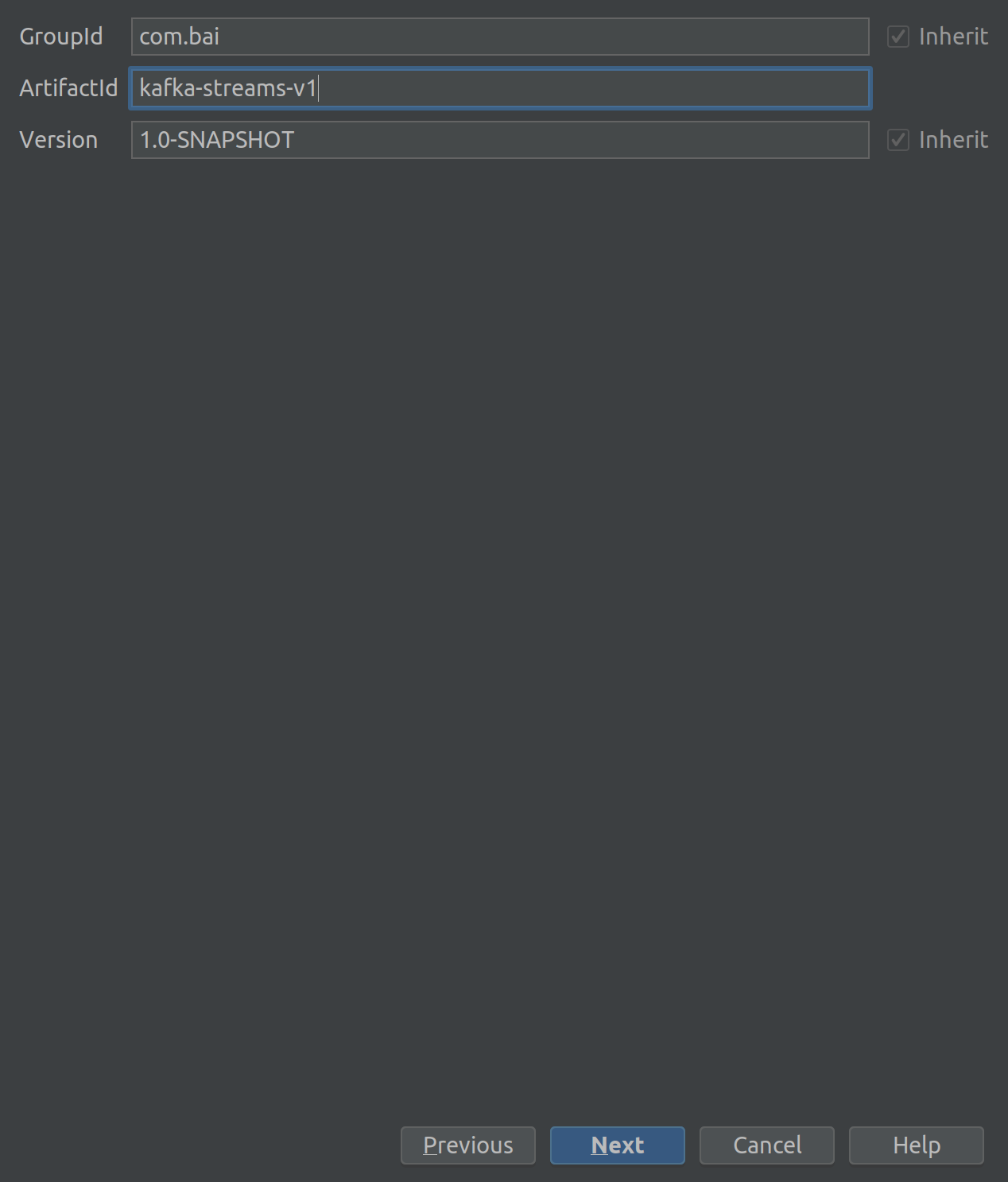
assign GroupId and ArtifactId
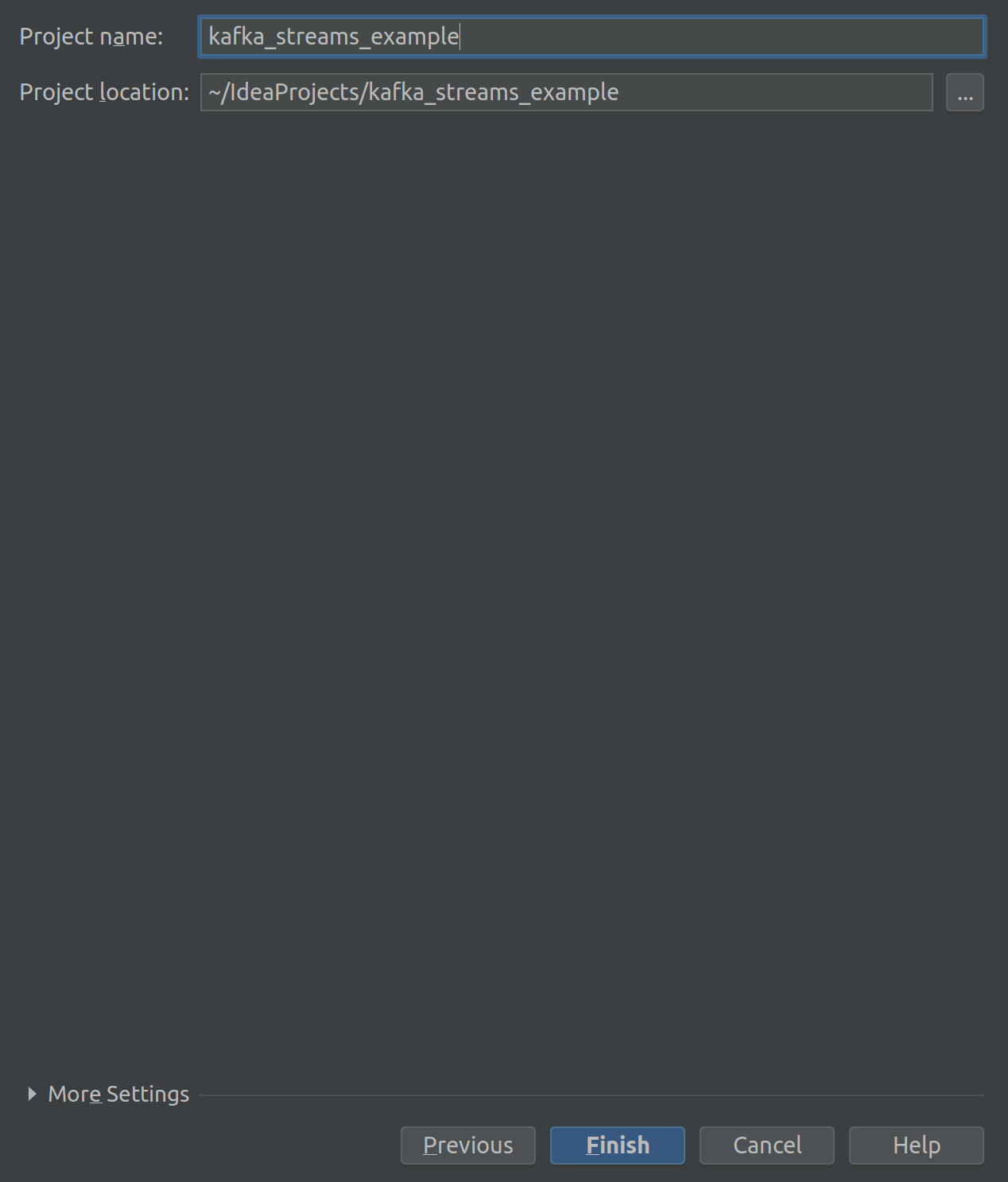
Assign Project Name:
Edit Maven POM.xml for build and download dependencies
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bai</groupId>
<artifactId>kafka-streams-v1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<avro.version>1.8.2</avro.version>
<kafka.version>2.1.1-cp1</kafka.version>
<confluent.version>5.1.2</confluent.version>
<slf4j.version>1.7.25</slf4j.version>
<java.version>1.8</java.version>
<maven.compiler.version>3.6.1</maven.compiler.version>
<maven.assembly.version>3.1.0</maven.assembly.version>
<build-helper-maven.version>3.0.0</build-helper-maven.version>
</properties>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<dependencies>
<!--project dependencies -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<!--for logging purposes-->
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- Dependencies below are required/recommended only when using Apache Avro. -->
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--force java 8-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!--package as one fat jar-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>${maven.assembly.version}</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.example.kafka_stream.WordCountApp</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>assemble-all</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Create a new Class
package com.example.kafka_stream; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serde; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.kstream.ForeachAction; import org.apache.kafka.streams.kstream.KStream; import org.apache.kafka.streams.kstream.KTable; import org.apache.kafka.streams.kstream.Produced; import java.util.Arrays; import java.util.Properties; import java.util.regex.Pattern; public class WordCountApp { public static void main(String[] args) { Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application"); config.put(StreamsConfig.CLIENT_ID_CONFIG, "wordcount-lambda-example-client"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); // Records should be flushed every 10 seconds. This is less than the default // in order to keep this example interactive. config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 10 * 1000); // For illustrative purposes we disable record caches config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); // Set up serializers and deserializers, which we will use for overriding the default serdes // specified above. final Serde<String> stringSerde = Serdes.String(); final Serde<Long> longSerde = Serdes.Long(); StreamsBuilder builder = new StreamsBuilder(); // stream from kafka KStream<String, String> wordCountInput = builder.stream("streams-plaintext-input"); // wordCountInput.foreach(new ForeachAction<String, String>() { // @Override // public void apply(String s, String s2) { // System.out.println(s2); // } // }); final Pattern pattern = Pattern.compile("\\W+", Pattern.UNICODE_CHARACTER_CLASS); final KTable<String, Long> wordCounts = wordCountInput .flatMapValues(value -> Arrays.asList(pattern.split(value.toLowerCase()))) .groupBy((k,v) -> v) .count(); // write results back to kafka wordCounts.toStream().to("streams-wordcount-output", Produced.with(stringSerde, longSerde)); KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), config); kafkaStreams.cleanUp(); kafkaStreams.start(); // Add shutdown hook to respond to SIGTERM and gracefully close Kafka Streams Runtime.getRuntime().addShutdownHook(new Thread(kafkaStreams::close)); } }
Inspect the output data
In this section we will use built-in CLI tools to manually read data from Kafka. In practice, you would rather rely on other means to retrieve data from Kafka, for instance via Kafka Connect if you want to move data from Kafka to other data systems, or via Kafka Clients from within your own applications.
Open three terminals and perform:
# in first terminal # in project folder mvn package # in target folder java -cp kafka-streams-v1-1.0-SNAPSHOT-jar-with-dependencies.jar com.example.kafka_stream.WordCountApp # in second terminal kafka-console-producer --broker-list localhost:9092 --topic streams-plaintext-input >hallo blabla hallo # in third terminal kafka-console-consumer --topic streams-wordcount-outputs --from-beginning --bootstrap-server localhost:9092 --property print.key=true --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer hallo 2 blabla
Stop the Kafka cluster
Once you are done with the quick start you can shut down the Kafka cluster in the following order:
- First, stop the Kafka broker by entering
Ctrl-Cin the terminal it is running in. Alternatively, you cankillthe broker process. - Lastly, stop the ZooKeeper instance by entering
Ctrl-Cin its respective terminal. Alternatively, you cankillthe ZooKeeper process.
Congratulations, you have now run your first Kafka Streams ap