Mysql 插拔式的存储引擎
1,插拔式的插件方式 ,插拔式的插件方式,通过一组api的组合实现数据存储。
2,mysql存储引擎是指定在表之上的,即一个库中的每一个表都可以指定专用的存储引擎。
3,不管表采用什么样的存储引擎,都会在数据区,产生对应 的一个 的一个frm文件(表结构定义描述文件)
CSV存储引擎
数据存储以 数据存储以CSV文件 文件
特点:
不能定义没有索引、列定义必须为NOT NULL、不能设置自增列
–> 不适用大表或者数据的在线处理
CSV数据的存储用,隔开,可直接编辑CSV文件进行数据的编排
–> 数据安全性低
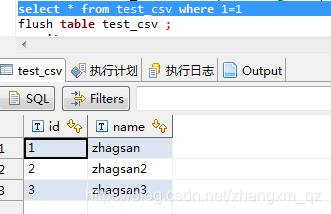
注:编辑之后,要生效使用flush table XXX 命令
应用场景:
数据的快速导出导入
表格直接转换成CSV 有点像分布式文件数据库hive
示例:
1、 查看mysql数据文件位置。
mysql> show global variables like '%datadir%'
-> ;
+---------------+---------------------------------------------+
| Variable_name | Value |
+---------------+---------------------------------------------+
| datadir | C:\ProgramData\MySQL\MySQL Server 5.7\Data\ |
+---------------+---------------------------------------------+
1 row in set, 1 warning (0.00 sec)
执行以下建表语句 提示错误 这个引擎不支持空类型的字段
mysql> create table test_csv (id varchar(10),name varchar(10))ENGINE=CSV DEFAULT
CHARSET=utf8;
ERROR 1178 (42000): The storage engine for the table doesn't support nullable co
lumns
字段加上 not null 限制,建表成功
mysql> create table test_csv (id varchar(10) not null,name varchar(10) not null)
ENGINE=CSV DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.06 sec)
插入两条数据
insert into test_csv values (‘1’,‘zhagsan’);
insert into test_csv values (‘2’,‘zhagsan2’);
mysql数据目录下有三个文件如下*.csm存储表的状态数据 ,*.csv存储数据我们可以直接打开并增加一条记录如下:
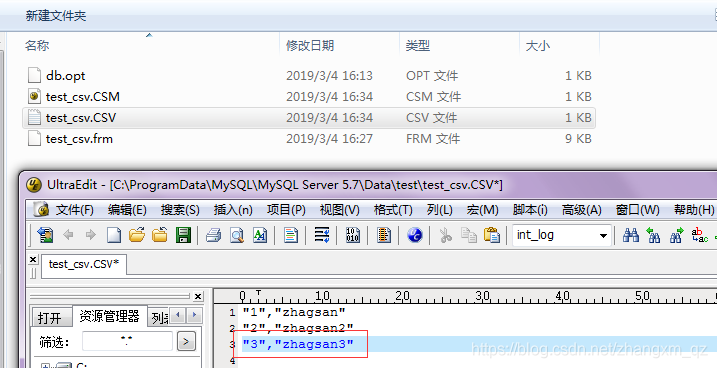
执行 flush table test_csv 之后就可以查询出 我们新加的数据如下:
Archive存储引擎
压缩协议进行数据的存储
数据存储为 数据存储为ARZ文件格式 文件格式
特点:
只支持insert和select两种操作
只允许自增ID列建立索引
行级锁
不支持事务
数据占用磁盘少
应用场景:
日志系统
大量的设备数据采集
示例
创建test_arch 表
create table test_arch (id varchar(10) not null,name varchar(10) not null) ENGINE=Archive DEFAULT CHARSET=utf8;
test_arch表包含两个文件 test_arch.arz 和test_arch.frm 如下:

当表中数据量很大时 Archive 引擎的表占用的空间比其他引擎小很多。同样100万条数据,innodb引擎的表占用 100M空间 Archive 引擎的表只占用3M 这里不做演示了。
Memory|heap存储引擎
数据都是存储在内存中,IO效率要比其他引擎高很多,服务重启数据丢失,内存数据表默认只有 16M
特点:
支持hash索引,B tree索引,默认hash(查找复杂度0(1))
字段长度都是固定长度varchar(32)=char(32)
不支持大数据存储类型字段如 blog,text
表级锁
应用场景:
等值查找热度较高数据
查询结果内存中的计算(比如子查询关联查询等),大多数都是采用这种存储引擎作为临时表存储需计算的数据。(如果查询结果包含 blog,text 类型的字段 将不会使用这种引擎,改用 Myisam )
Myisam存储引擎
Mysql5.5版本之前的默认存储引擎 版本之前的默认存储引擎,较多的系统表也还是使用这个存储引擎。系统临时表也会用到Myisam存储引擎
特点:
a,select count(*) from table 无需进行数据的扫描,有专门的地方存储数据描述,但是innodb 必须将所有结果查询出来 才会确定一共有多少列。
b,数据(MYD)和索引(MYI)分开存储,非聚集索引,参考上一篇文章
c,表级锁
d,不支持事务
https://mp.weixin.qq.com/s/FUXPXKfKyjxAvMUFHZm9UQ
InnoDB 存储引擎
Mysql5.5及以后版本的默认存储引擎 及以后版本的默认存储引擎
Key Advantages: :
Its DML operations follow the ACID model [事务ACID]
Row-level locking[行级锁]
InnoDB tables arrange your data on disk to optimize queries
based on primary keys[聚集索引(主键索引)方式进行数据存储]
To maintain data integrity, InnoDB supports FOREIGN KEY
constraints[支持外键关系保证数据完整性]
https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html
存储引擎对比
https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
