好久没有更新啦,最近又有一些新的学习与尝试,所以来更新下,以便以后遇到同样的问题还记得怎么处理!
最近在做资讯推荐算法,大体就是基于内容的推荐,还可以的一点是走实时推荐,即可以根据用户最近的浏览来捕捉用户的兴趣点,从而根据用户即时兴趣做相似度召回以及排序,算法方面没有什么可说的,使用了 gensim,jieba,hanlp 模块
hanlp模块的安装也有一些坑,其实可以直接装pyhanlp,然后装JVM,设置环境变量即可。最早按照下面这个链接安装,简直糟了半天心也安装不成功(http://www.hankcs.com/nlp/python-calls-hanlp.html),后面还是去hanlp官网,发现还有pyhanlp这种东西,用pip install pyhanlp直接安装成功了,pyhanlp安装成功,jpype也就安装成功了,然后使用的时候直接from pyhanlp import * seg_list = HanLP.segment(content) 即可
跑题了,这篇主要介绍python启动http服务,本来是我把模型和部署需要的.py文件传给同事,然后同事包装JSF服务,然后另外的同事调用,即可实时实现,但是这里面有个局限就是只能上传一个模型文件,而我这次除了tfidf模型文件外,还多了一个dictionary的字典文件,而上线又迫在眉睫,所以就准备申请多个服务器,启多个http服务,用负载均衡的方法来实现
那么如何用python启http服务呢,这就用到了python的flask模块,Flask是一个Python编写的Web 微框架,重点在于app.run模块,认识这个模块,得谢谢我的同事邱宇江(想着同事应该不会看到博客,所以就直接把同事名字写上啦!一直觉得相遇是缘分,谢谢每个同事对我工作的帮助),正好他先前替朋友的女朋友写过毕设里面用到了,然后直接把代码发给我,而且超详细的帮我备注需要改哪里,很赞,这样我迅速改了自己的代码,实现了python启http服务。但是这个里面有个坑,就是app.run()里面的参数我没有任何设置,除了debug = True ,在我本机上运行,然后用postman访问,完全可以,但是我的上游调用就无法连接,我们绞尽脑汁一直以为是网络和端口的问题,最终发现原来是app.run()的问题(注,邱宇江同学发现的)
app.run(host='0.0.0.0') 这样其他网络中的电脑才能访问我本机的http服务
postman的下载与安装也写下:
下载postman,说来也奇怪一般下载下来的postman文件后缀有可能是.crx,把这个后缀改为.zip或.rar转成压缩文件,解压到文件夹,然后用谷歌-更多工具-扩展程序-切到“开发者模式”-加载已解压的扩展程序-选择你解压的文件目录-点击确定即可,那么怎么打开呢?在谷歌浏览器地址栏输入 :chrome://apps/ 看到postman图表,单机即可打开
postman 发送json串,由于我的入参为4个list,所以我用了比较好用又灵活的json串,可以写好接送串去https://www.json.cn/里面验证是否写正确了,然后选择post-body-raw-将你的json串写入输入区,点击send,这时就回到你的代码中了,就可以进行debug啦,对json串需要根据格式进行解析
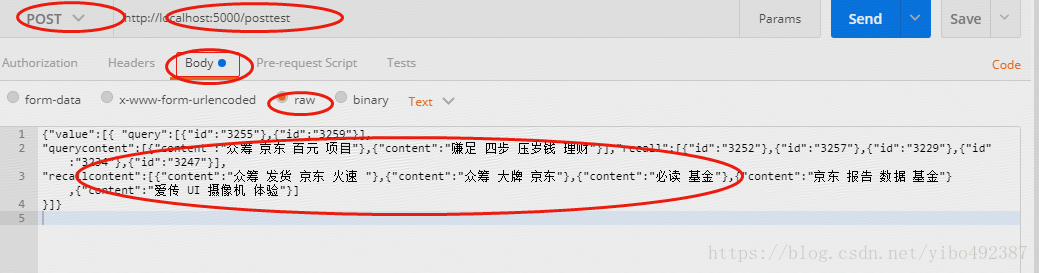
回到自己的posttest函数里面,需要去解析,大致的解析代码如下
@app.route('/posttest',methods =['POST']) def testPost(): error = None if request.method == 'POST': data = request.get_data() j_data = json.loads(data) j_data_1 = j_data['value'] listt = j_data_1[0] query = listt['query'] query_id_list = [] for i in range(0,len(query)): id = query[i]["id"] query_id_list.append(id) querycontent = listt['querycontent'] query_content_list = [] for i in range(0, len(querycontent)): content = querycontent[i]["content"] query_content_list.append(content) recall = listt['recall'] recall_id_list = [] for i in range(0, len(recall)): id = recall[i]["id"] recall_id_list.append(id) recallcontent = listt['recallcontent'] recall_content_list = [] for i in range(0, len(recallcontent)): content = recallcontent[i]["content"] recall_content_list.append(content) predict_list = predict(query_content_list, query_id_list, recall_content_list, recall_id_list, tfidf, dictionary) prestr = ",".join(predict_list) return prestr else: return "error"