epub直接获取书名及书封面
完整的Demo下载GitHub 里面有详细介绍如何使用
一、场景说明
某些场景下我们需要直接获取epub类型书籍的封面及书名,网络上很多文章介绍的都是通过Slf4j等开源库解析,但是这类库往往都是将一整本书籍进行解析后再获取书名等信息,对于一本30M、50M甚至更大的书籍时,往往需要解析很久,而不巧的是我只需要书名、封面,加载其他内容这时候显得有点多余。
首先最好先了解一下epub的一些标准epub文件格式介绍
前戏,先看看效果,是不是你想要的
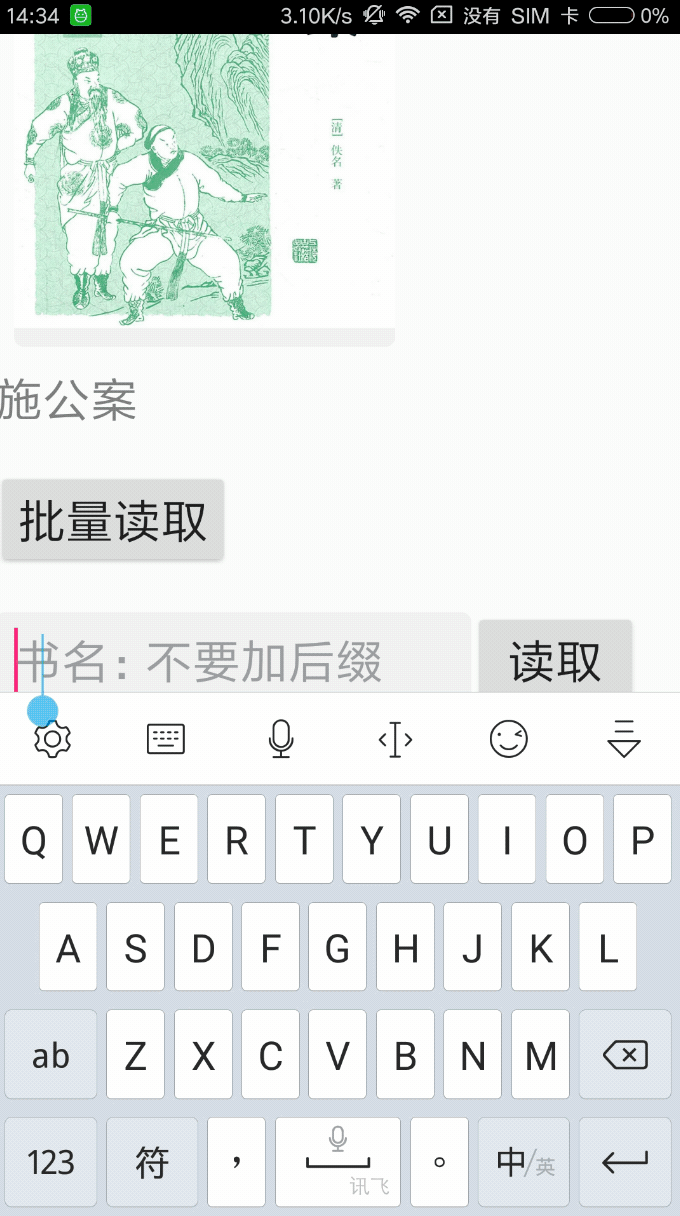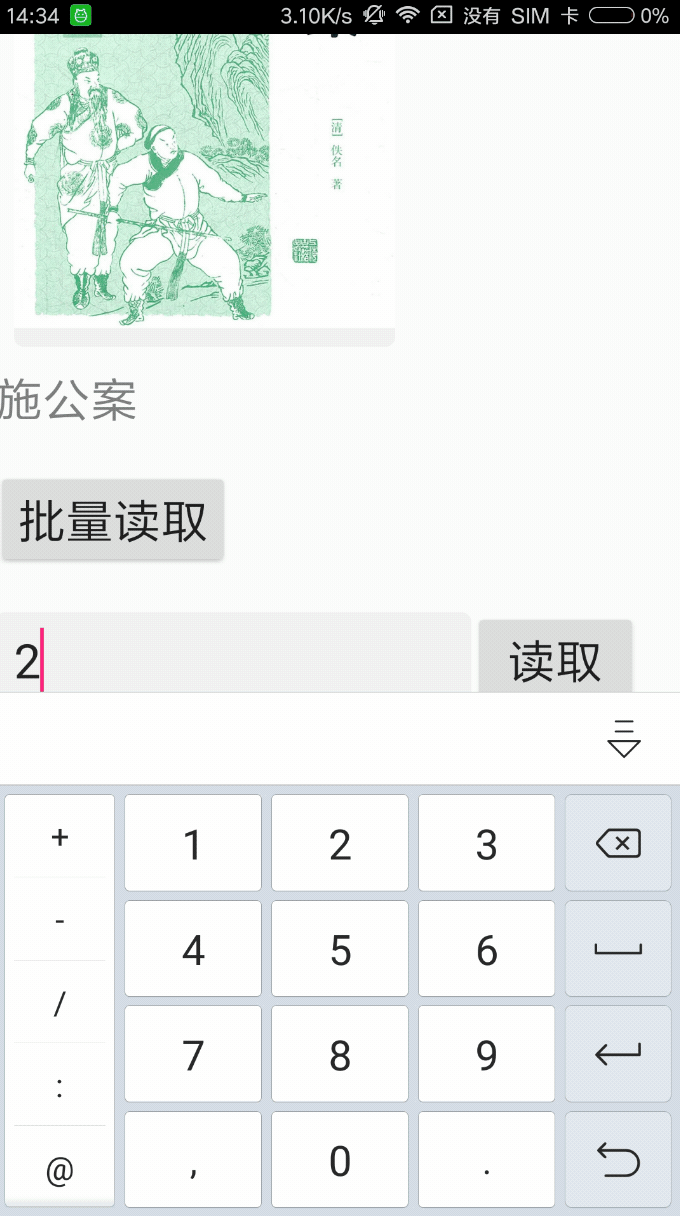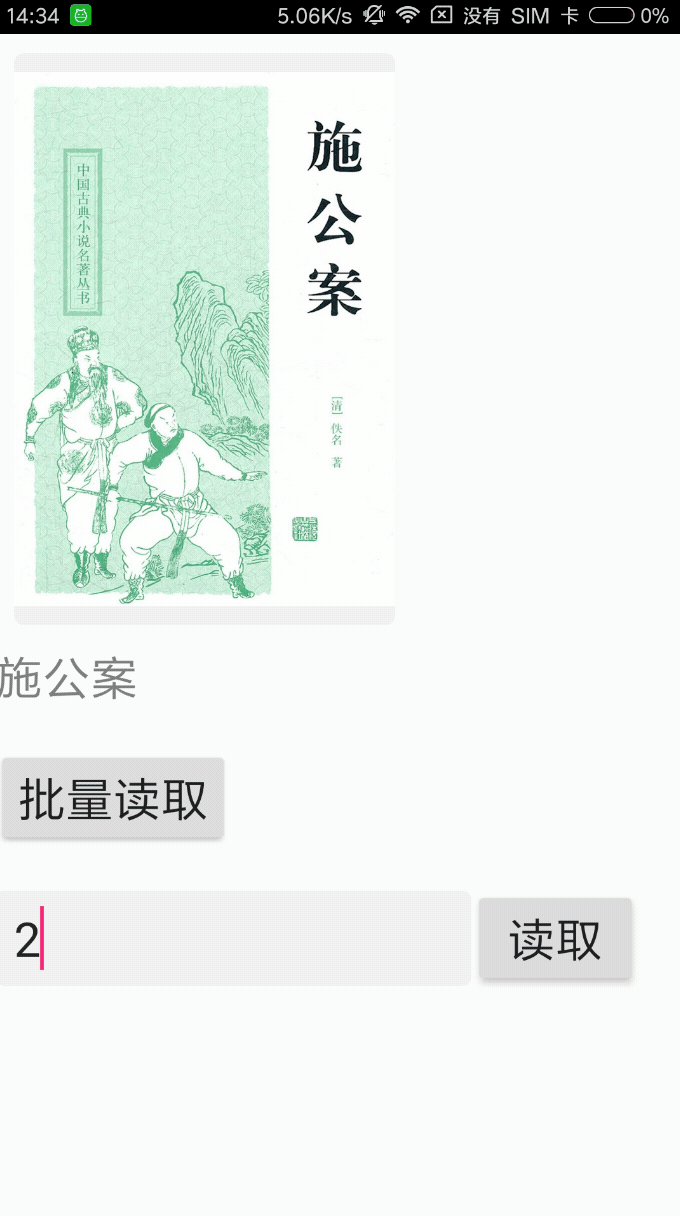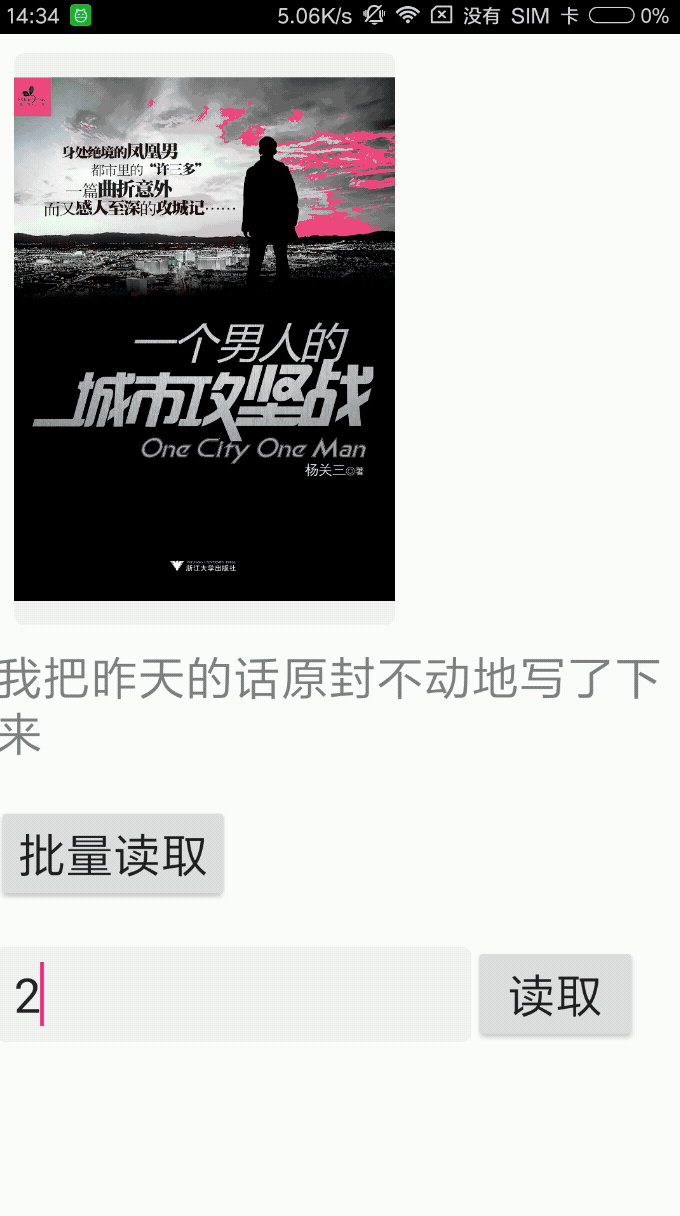
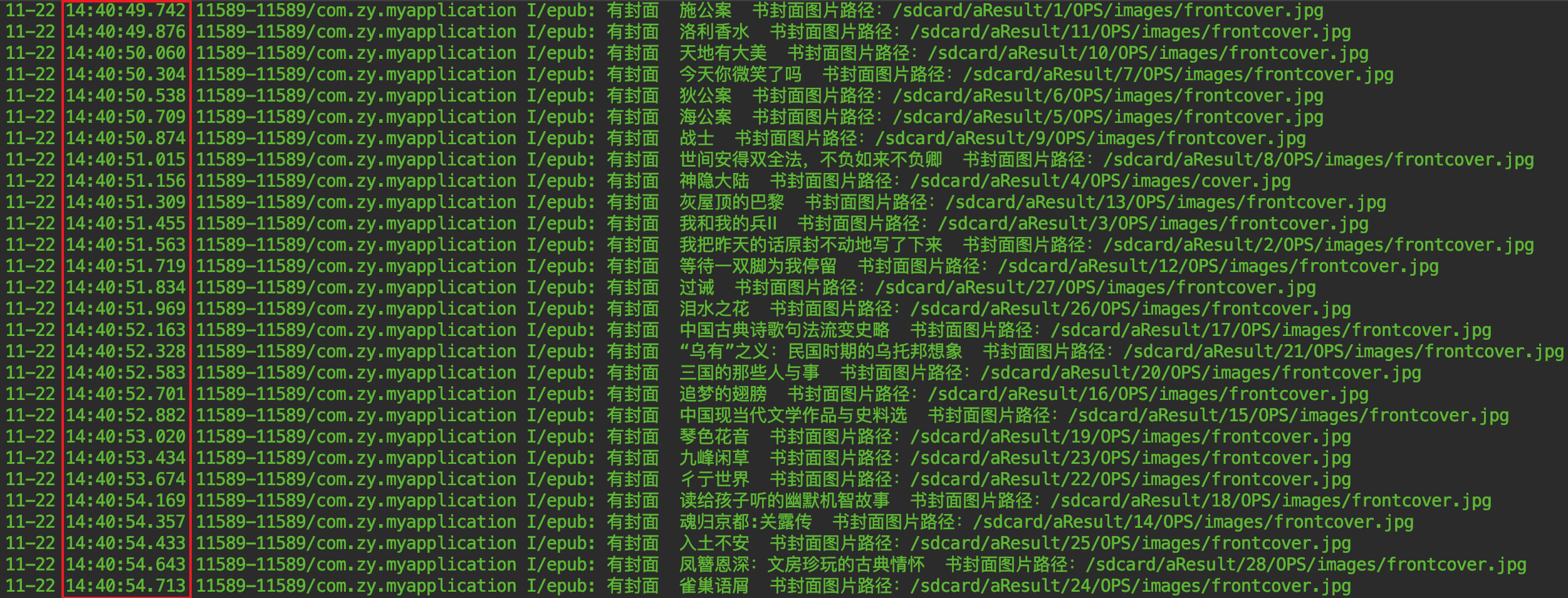
小米4手机批量解析27本epub时,具体耗时见日志。
二、ePub文件分析
我在这里简单的介绍一下,写的不好的话还请见谅啊,哈哈。
先看下流程图,大体思路也是如此。

1、思路
看懂上面其实就很简单了,没看懂没关系,下面我会详细说明的。
1.1、首先要知道2点:
- epub其实就是zip压缩,所以肯定是要先解压文件的,这里注意,我们不能去解压全部文件,这样遇到大文件时必然还是会很耗时,最优的肯定是解压单个目标文件。
- 大部分文件主要是以xml文件为主。
1.2、思路详解
首先我们先用zip将epub书籍解压,这里为了大家更直观,我用了2本目录结构不同的书本。

1号书目录结构如下:

2号书目录结构如下:

根据epub标准规范规定,META-INF文件是必然存在的,详见epub文件格式介绍。
打开META-INF文件目录下的container.xml文件,里面记录着一个重要文件的路径(content.opf)。这是比较关键性的一步,我们要根据rootfile标签,取得full-path的值,也就得到了content.opf路径。

找到content.opf文件,并打开(剩下的都步骤都一样,我这里开始主要以2号书籍为例)。可以看到一些关键的信息已经展现在我们面前了,书名、作者、出版社、时间、目录等等。想要什么大家都可以自己去发挥啦。
而且OPF文件实际也是xml内容,所以用xml解析就行了。
注:这里封面图片要注意一下,先要找到mate标签且属性name为“cover”,然后得到其中属性content的值"cover-image",接着在manifest下众多Item标签中找到ID名对应刚刚的"cover-image",里面的属性href记录着封面图片的路径。如果找不到mate标签且name为“cover”的话说明此书无封面

三、代码
1、代码思路
步骤如下:
- 解压MEIA-INF文件夹。
- 解析MEIA-INF文件夹下的container.xml,取得content.opf路径。
- 根据取得的content.opf路径,解压其文件。
- 解析content.opf取得书名和图片路径。
- 根据图片路径,解压文件夹取得图片的bitmap。
4、上代码
思路看懂了的话,代码其实也没什么好讲的了,具体看注释吧。
ReadEpubHeadInfo类,主要用于解析epub书本,返回一个BookModel对象,对象内部有书名等属性。
/**
* @作者: JJ
* @创建时间: 2018/9/12 上午11:58
* @Version 1.0
* @描述: 直接获取Epub的书名+封面图片。
*/
public class ReadEpubHeadInfo {
/**
* 存储content.opf文件路径
*/
private static final String META_INF_CONTAINER = "META-INF/container.xml";
/**
* 默认解压后进行暂存的地址
*/
private static String SAVE_INFO_PATH = "/sdcard/aEpubHeadInfo/";
/**
* 默认图片存放路径
*/
private static String SAVE_IMAGE_PATH = "/sdcard/aResult/";
public String getSaveInfoPath() {
return SAVE_INFO_PATH;
}
public void setSaveInfoPath(String saveInfoPath) {
SAVE_INFO_PATH = saveInfoPath;
}
public ReadEpubHeadInfo() {
}
public static BookModel getePubBook(String ePubPath) {
if (TextUtils.isEmpty(ePubPath))
return null;
if (!FileUtils.getFileExtension(ePubPath).equals("epub")) {
return null;
}
BookModel book = new BookModel();
//之前是否有缓存,清空
if (FileUtils.isDir(SAVE_INFO_PATH)) {
FileUtils.deleteDir(SAVE_INFO_PATH);
}
try {
//存储content.opf文件路径信息
String contentOpfPath = "";
LogUtils.d("epub", "1.解压MEAT-INF文件 " + ePubPath);
//1.解压MEAT-INF文件,解析container.xml的rootfile标签,获取content.opf的路径。
if (ZipUtils.zipSpecifiedFile(ePubPath, SAVE_INFO_PATH, META_INF_CONTAINER)) {
contentOpfPath = XmlUtils.xmlSubtagNameAnalysis(SAVE_INFO_PATH + META_INF_CONTAINER, "rootfiles", "rootfile", "full-path");
} else {
LogUtils.e("epub解析", ePubPath + "解析错误,请检查书本");
return null;
}
LogUtils.d("epub", "2.解压获取到的content.opf路径 " + ePubPath);
//2.解压获取到的content.opf路径,并用xml解析获取title信息
if (ZipUtils.zipSpecifiedFile(ePubPath, SAVE_INFO_PATH, contentOpfPath)) {
book.setName(XmlUtils.xmlSubtagNameAnalysis(SAVE_INFO_PATH + contentOpfPath, "metadata", "title", null));
book.setAuthor(XmlUtils.xmlSubtagNameAnalysis(SAVE_INFO_PATH + contentOpfPath, "metadata", "creator", null));
//3.获取封面图片路径
LogUtils.d("epub", "3.获取封面图片路径 " + ePubPath);
String imgXmlFlag = XmlUtils.xmlSubtagConditionAnalysis(SAVE_INFO_PATH + contentOpfPath, "metadata", "name", "cover", "content");
if (imgXmlFlag != null) {
String imgPath = "";
String[] content = contentOpfPath.split("/");
for (int i = 0; i < content.length - 1; i++) {
imgPath += content[i] + "/";
}
String[] sourceBookName = ePubPath.split("/");
imgPath += XmlUtils.xmlSubtagConditionAnalysis(SAVE_INFO_PATH + contentOpfPath, "manifest", "id", imgXmlFlag, "href");
String saveImagePath = SAVE_IMAGE_PATH + FileUtils.delFileSuffix(sourceBookName[sourceBookName.length - 1]) + "/";
LogUtils.d("epub", "4.根据路径解压图片 " + ePubPath);
//4.根据路径解压图片
if (ZipUtils.zipSpecifiedFile(ePubPath, saveImagePath, imgPath)) {
book.setCover(saveImagePath + imgPath);
} else {
book.setCover(null);
}
LogUtils.d("epub", "完成 " + ePubPath);
}
} else {
LogUtils.e("epub解析", ePubPath + "解析错误,请检查书本(可能原因,书籍被加密)");
return null;
}
} catch (Exception e) {
return null;
}
if (book.getName() == null) {
//获取文件名,作为备用,如果获取不到书名的话用文件名代替
book.setName(new File(ePubPath).getName());
}
return book;
}
}
完整的Demo下载GitHub 里面有详细介绍如何使用
如果对您有帮助,感谢下载
CSDN下载分数5分。