小知识
在分布式项目中,分库分表一般使用取模算法,比如一个电商项目,用户量很大,那么可以使用用户ID进行hash取模,进行分表,但是有个严重问题,如果分表数目没有预估好,随着用户量不断增大,单表数据量过大,这个时候需要扩容,改变分表数,数据迁移的难度就太大了。
一致性hash算法就可以解决分布式情况下动态扩容问题。
原理
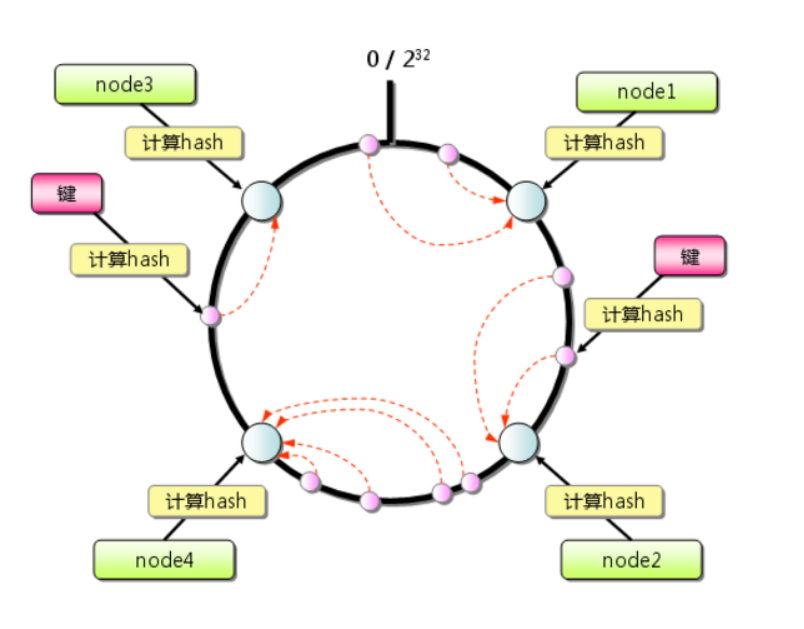
1.先构造一个长度为2^32的整数环(范围[0, 2^32-1]);
2.根据节点名称的hash值将服务器节点放到环上;
3.根据数据key值计算出其hash值,在hash环上沿顺时针寻找最近的服务器节点,将数据放入其中。
代码实现
使用TreeMap,键为hash值,value为服务器节点名称,TreeMap的firstKey()方法会找到升序最大的一个key的位置,即数据应该落到的服务器节点位置。
public class ConsistentHash {
//服务器列表名称
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
//key是服务器的hash值,value是服务器的名称
private static SortedMap<Integer, String> sortedMap = new TreeMap<>();
static {
for (int i = 0; i < servers.length; i++) {
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println("---------------");
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值,String自带的hashcode分布不均
*/
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
private static String getServer(String str) {
//求出hash值
int hash = getHash(str);
//获取大于hash部分,返回值是map
SortedMap<Integer, String> subMap =
sortedMap.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
return subMap.get(i);
}
public static void main(String[] args) {
String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"};
for (int i = 0; i < nodes.length; i++)
System.out.println("[" + nodes[i] + "]的hash值为" +
getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}
//注, 本段代码使用的是https://www.cnblogs.com/xrq730/p/5186728.html这篇博客
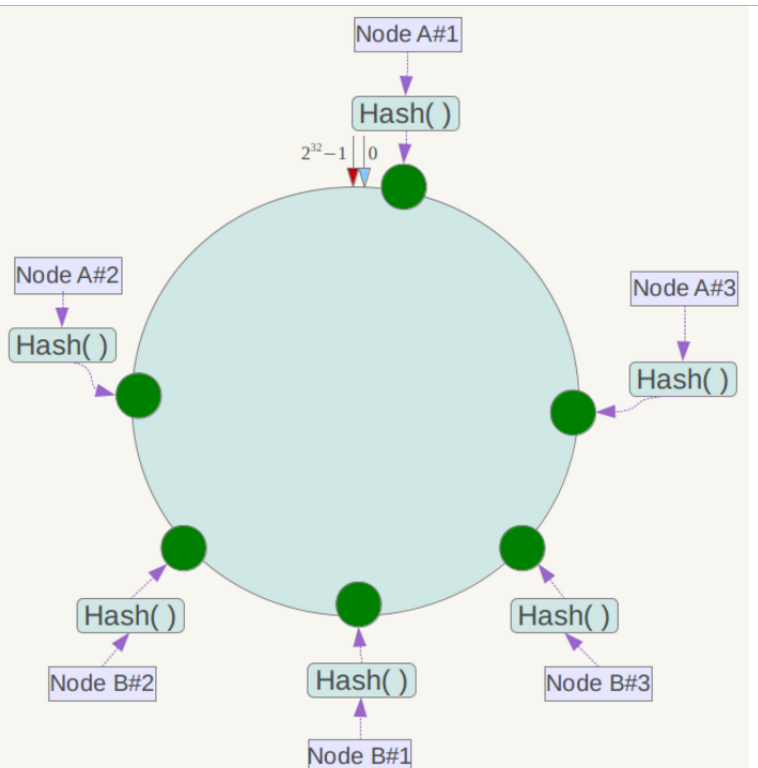
虚拟节点
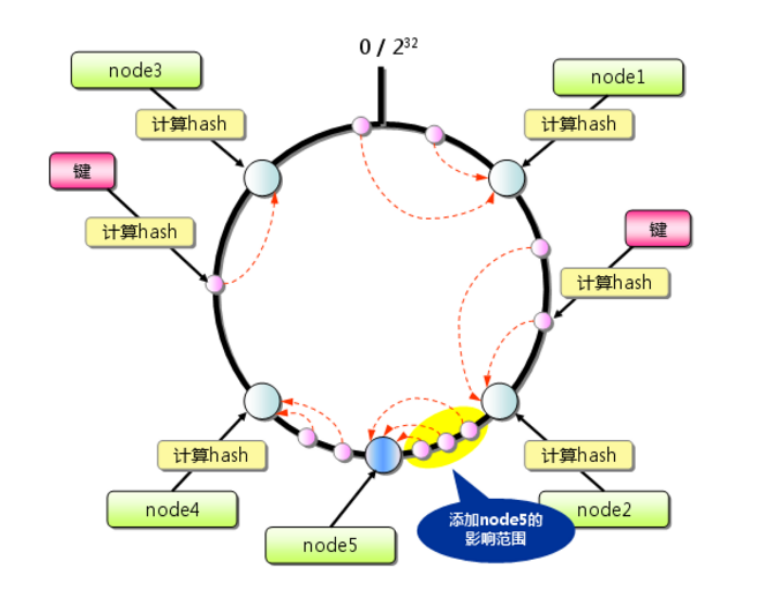
在上面图中,添加node5节点会导致原本落在node4上面的部分数据落在node5上,和其它服务器节点相比,数据分布不均匀,导致数据倾斜。
解决这个问题的方案就是将真实的节点映射成多个虚拟节点,实际运用中设置成32个节点甚至更多,这样数据分布相对均匀。
代码:
public class ConsistentHashWithVirtualNode {
//服务器列表名称
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
//真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
private static List<String> realList = new LinkedList<>();
//虚拟节点
private static SortedMap<Integer, String> vnMap = new TreeMap<>();
//设置真实节点对应虚拟节点个数比例
private static final int VIRTUAL_NODES = 5;
//初始化真实节点列表和虚拟节点列表,构造hash环
static {
for (int i = 0; i < servers.length ; i++) {
realList.add(servers[i]);
}
for (String item: realList) {
for (int i = 0; i < VIRTUAL_NODES; i++) {
//添加一个后缀作为虚拟节点名称
String virtualNodeName = item + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
vnMap.put(hash, virtualNodeName);
}
}
}
private static String getServer(String str) {
//求出hash值
int hash = getHash(str);
//获取大于hash部分,返回值是map
SortedMap<Integer, String> subMap =
vnMap.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
String vstr = subMap.get(i);
//删除后缀作为实际节点名称
return vstr.substring(0, vstr.indexOf("&&"));
}
}
使用场景
分布式缓存memcache中使用了此算法,Memcached client客户端生成hash值用的是Ketama算法,用TreeMap存储所有节点,推荐阅读源码。