科大人使用的VisualBox来搭建Linux虚拟机,先新建一台LinuxUbuntu16.04版的虚拟机,配置虚拟机的过程在这里就不说了,看科大人心情要不要专门写一篇博客来叙述安装教程。
搭建基础的hadoop集群,科大人准备使用一台主机(master)和两台从机(slave1、slave2)来实现,主机配置的2G内存2核CPU,两从机配置的1G内存2核CPU,这个可以根据电脑配置做改变,但是主机最好2G2核以上,否则可能运行不起来。
网络配置的是桥接网卡,每台虚拟机上都要配置独立的静态ip(如下图)
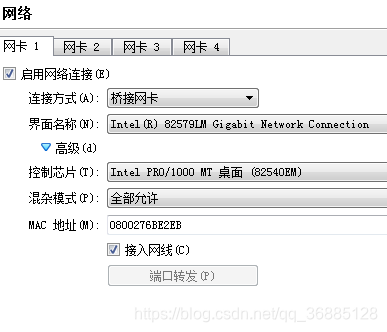
第一台主机安装好后,不忙着安装另两台,等完全配置好第一台复制两份即可。
进入正题:
1、开启安装好的虚拟机,root登录,修改主机名:
进入hostname文件:vim /etc/hostname,将localhost改为master(你准备的主机名)保存退出,新主机名重启后生效。
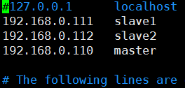
进入hosts,添加域名和ip对应关系:vim /etc/hosts,添加你的ip和域名对应关系后保存退出,例如我的:
2、配置静态ip:
进入网络配置文件:vim /etc/network/interfaces,修改为如下图:
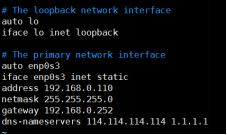
其中的address填入你准备的主机ip,netmask为子网掩码,gateway是网关,dns-nameservers是指向的域名地址(这个可以就填我的这个),子网掩码和网关通过cmd输入ipconfig可以查到你电脑的网络信息,准备的集群主机ip为上面hosts中配置master的ip,不要和你的电脑ip一样,通过在cmd输入ping加上ip来判断该ip是否已被占用。
配置好后保存退出,重启网络:/etc/init.d/networking restart,输入ping 163.com,如果能持续收到回应则网络配置成功,正常关机,对虚拟机进行快照备份,之后如果出了无法解决的问题就回滚到现在的状态,启动虚拟机,ifconfig查看ip是否配置好。
3、关闭防火墙:ufw disable
4、添加hadoop用户
添加hadoop分组:addgroup hadoop
添加hadoop用户并分配到hadoop分组中:adduser -ingroup hadoop hadoop(一路Enter键过去)
5、登录hadoop用户,自己在网上找到hadoop-2.7.2.tar.gz和 jdk-8u181-linux-x64.tar.gz的资源包,或者点击如下链接:
Hadoop http://archive.apache.org/dist/hadoop/common/
Jdk https://www.oracle.com/technetwork/java/javase/downloads/index.html
6、压缩包添加到hadoop用户目录下,解压资源包:
tar –xvf hadoop-2.7.2.tar.gz
tar –xvf jdk-8u181-linux-x64.tar.gz
7、配置环境变量:
进入配置文件:vim ~/.profile,在文件末尾添加如下内容:
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export HADOOP_HOME=/home/hadoop/hadoop-2.7.2
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使文件生效:source ~/.profile。
测试jdk是否安装成功:java -version,显示当前版本。
8、修改hadoop文件:
进入路径:cd /home/hadoop/hadoop-2.7.2/etc/hadoop/
修改如下文件:
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>0</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim mapred-site.xml(先将mapred-site.xml.template拷贝为mapred-site.xml文件再进行读写)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
vim core-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
9、在当前目录的 hadoop-env.sh(25 行)、yarn-env.sh(23 行)、mapred-env.sh(16 行)、httpfs-env.sh(最后)文件中添加以下内容:
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
10、还在当前目录的slaves文件中配置所有datanode节点名称,也就是从机名:

11、授权:
chmod 777 /home/hadoop/hadoop-2.7.2/sbin/*
chmod 777 /home/hadoop/hadoop-2.7.2/bin/*
chmod 777 /home/hadoop/hadoop-2.7.2/lib/native/*
12、关机快照备份后,将该虚拟机复制两份作为两台从机,打开从机使用root用户登录,分别修改从机ip为之前在master主机中hosts文件配置的ip,分别修改从机名为slave1、slave2,重启网络然后判断网络是否连通,具体操作回顾1、2,完成后关机快照备份。
13、SSH免登录配置:
打开三台虚拟机登录hadoop用户,输入:ssh-keygen -t rsa,然后一路Enter,如果问是否overwrite就输入y,得到公钥。
将公钥放入钥匙仓库:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
添加权限:chmod 600 ~/.ssh/authorized_keys
将密钥仓库分别拷贝到三个域名节点下(问yes/no回yes,要密码输密码):
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
*13的步骤在三台虚拟机上都要执行
14、测试是否免密登录,分别在三台虚拟机上执行:
ssh master
ssh slave1
ssh slave2
如果无需密码直接进入虚拟机用户,则执行成功,否则查看公钥里的文件是否有问题,提示找不到master或slave1、slave2则回顾1、2,之后三台虚拟机关机快照备份。
15、启动主从机,hadoop用户登录,在master运行 hdfs 格式化命令:
hdfs namenode -format
该命令仅在初次初始化或重置集群时执行,若多次格式化则需删除三台虚拟机中的tmp文件夹:rm -rf /home/hadoop/hadoop-2.7.2/tmp,执行结果中出现has been successfully formatted 表示格式化完成(successfully显示在运行结果中间。。。)。
16、在 master 机器上,hadoop用户运行 hadoop 启动命令:start-all.sh,等待启动完成,在三台虚拟机上输入指令:jps,出现如图结果则表示成功了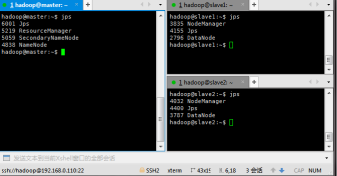
17、在 master 机器上,运行 hadoop 终止命令:stop-all.sh,则结束hadoop进程。
hadoop搭建完成,亲测有效,若有未发现的错误的地方,请留下评论一起来探讨方便科大人修改,完毕~~~