1.插入排序(insertion sort)
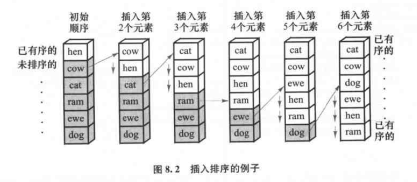
如图所示,将需要排序的序列,分成已排序的部分,和未排序的部分。
循环中,每一次就将当前迭代到的,未排序的第一个元素,插入到在已排序部分中的适当位置。
2.选择排序(selection sort)
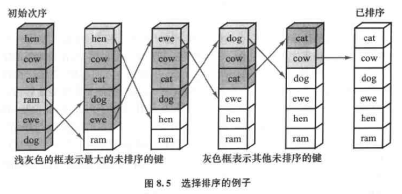
如图所示,首先便利所有未排序的元素,找出最大的一个,然后与数组中的最后一个交换。
下一次迭代就从未排序的元素中,找出最大的一个,与数组中倒数第二个交换,以此类推。
3. 希尔排序(shell sort)
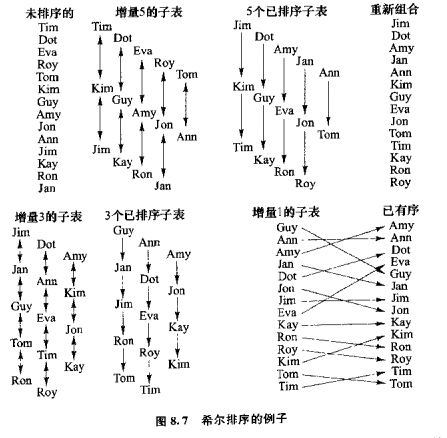
希尔排序,主要是将各元素按一个递减的增量,来对元素分组排序,如图所示,一开始increment为5,则将元素分为5组,每组3个,元素在组内先按大小排序好。
然后increment按(increment = increment / 3 + 1)的形式进行递减,则第二次迭代increment为3,则将元素分为3组,再在组内进行排序。直到increment小于等于1。
具体算法:
void shell_sort() {
int increment, start;
increment = array.count;
do {
increment = increment / 3 + 1;
for (start = 0; start < increment; start++) { sort_interval(start, increment); } } while(increment > 1); }
4. 归并排序(merge sort)

归并排序是采用分治法的一种。通过直接将数组对半分,然后分成2部分数组,进行递归,直到数组中元素为一个,则函数直接返回,而父函数就将两个数组中的元素进行比较,合并成为一个已经排好序的数组。
具体算法:
void recursive_merge_sort(Node*& sub_list) {
if (sub_list != NULL && sub_list -> next != NULL) {
Node *second_half = divide_from(sub_list);
recursive_merge_sort(sub_list);
recursive_merge_sort(second_half);
sub_list = merge(sub_list, second_half);
}
}
5. 快排(quick sort)
快排的核心,其实也是分治法。
通过选定一个pivot。

然后将数组分成大于这个pivot的和小于这个pivot的两组。
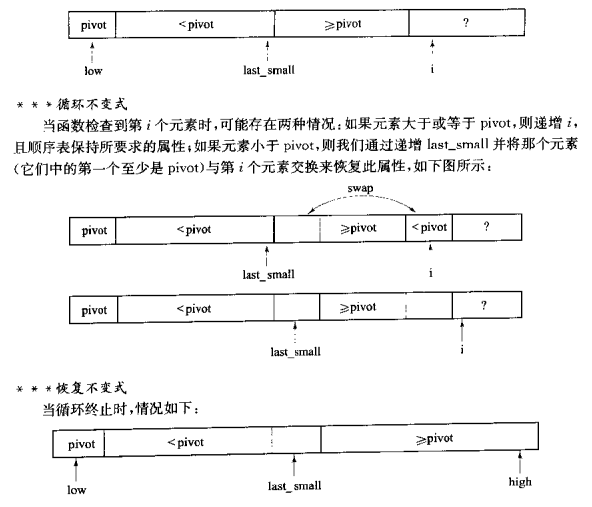
再递归,分别给这两组再找pivot及分组,直到组内元素为1。则快排结束。
6. 堆排序
堆定义:堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要不小于其孩子,最小堆要求节点元素都不大于其左右孩子,两者对左右孩子的大小关系不做任何要求。
在一个二叉堆中,位置k的结点的父结点的位置为k/2 向下取整,而他的两个子结点的位置分别为2k和2k+1。
一个例子:
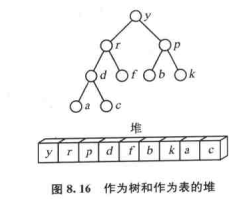
上图是一个最大堆。
堆主要有两个操作:
(1)插入:
a. 往堆中的某个空节点插入一个元素,则要用该元素与该节点的两个子节点的较大一个进行比较。
b. 如果元素大于该较大节点,则元素能够放在这个位置。
否则,将这个较大节点,上浮到元素原来想存放的位置。然后元素的位置移到这个较大节点,再重复a
参考代码思路:
void insert_heap(int current, int low, int high) {
int large = 2 * low + 1; // large是low的左子节点
while (large <= high) {
if (large < high && entry[large] < entry[large + 1])
large++; // 确保large是两个子节点中的较大一个
if (current >= entry[large])
break; // 可以放在low这个位置
else {
entry[low] = entry[large]; // 交换较大节点到low
low = large; // low指向较大节点的位置
large = 2 * low + 1; // large变为low的左子节点
} } entry[low] = current; // 放在low的位置 }
推排序最主要的几个步骤:
(1)初始化一个最大堆
将一个无序的数组,变化成一个最大堆。
方法:从最后一个子元素的父元素开始,按顺序,把非叶子节点的元素插入,判断其是否适合该位置。
参考代码:
void init_heap() {
int low;
for (low = count / 2 - 1; low >=0; low--) {
int current = entry[low];
insert_heap(current, low, count - 1);
}
}
(2)进行堆排序
把最大堆的堆顶元素出堆,放在最后一个元素(数组尾部)的位置,然后插入这个最后的元素进堆里。这样,每次出堆的都是当前堆的最大值,所以就能完成排序。
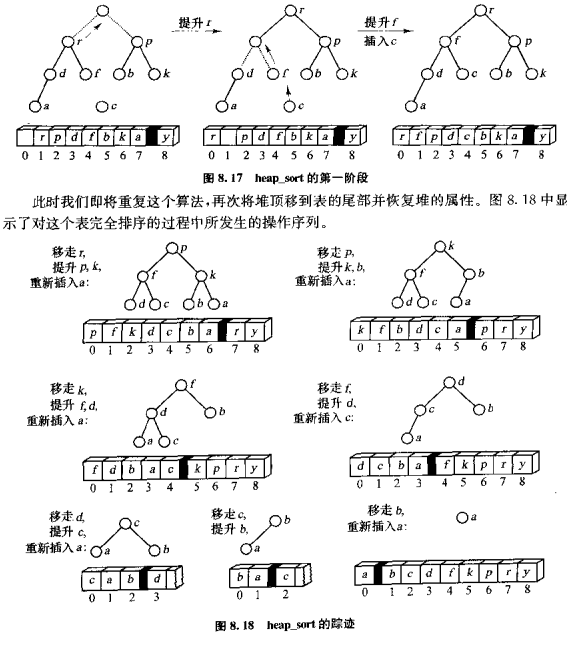
参考代码:
void heap_sort() {
int current, last_unsorted;
init_heap();
for (last_unsorted = entry.count - 1; last_unsorted > 0; last_unsorted--) {
current = entry[last_unsorted]; // 记录最后的元素
entry[last_unsorted] = entry[0]; // 把堆顶的元素放到sorted中
insert_heap(current, 0, last_unsorted - 1); // 把最后的元素放进堆中,重新构建堆。
}
}
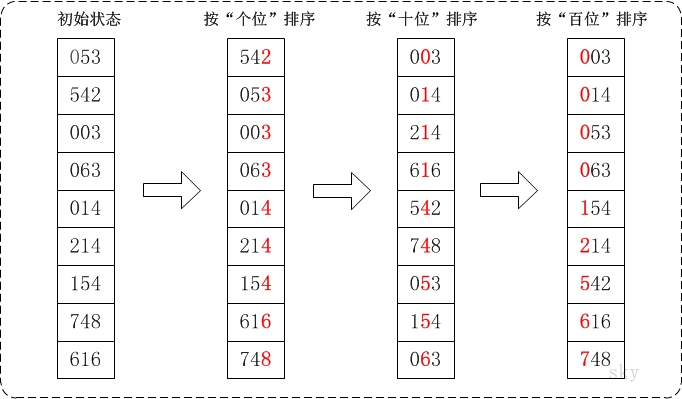
7. 基数排序
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
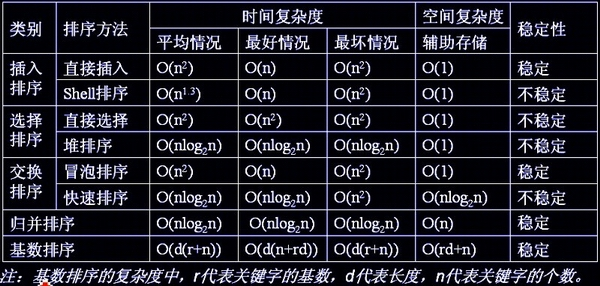
8. 各种排序的空间、时间复杂度以及稳定性