线程
在一个程序里的一个执行路线就叫做线程(thread),线程是“一个进程内部的控制序列”。一切进程至少都有一个执行线程。 线程是在进程内部运行,本质上是在进程的地址空间内运行。 在Linux下是没有线程的概念的,因此在Linux下是用进程来模拟线程的,所以Linux下的线程也称为轻量级进程。
所以总结一下可以说:进程是承担分配系统资源的基本实体,线程是CPU调度的基本单位
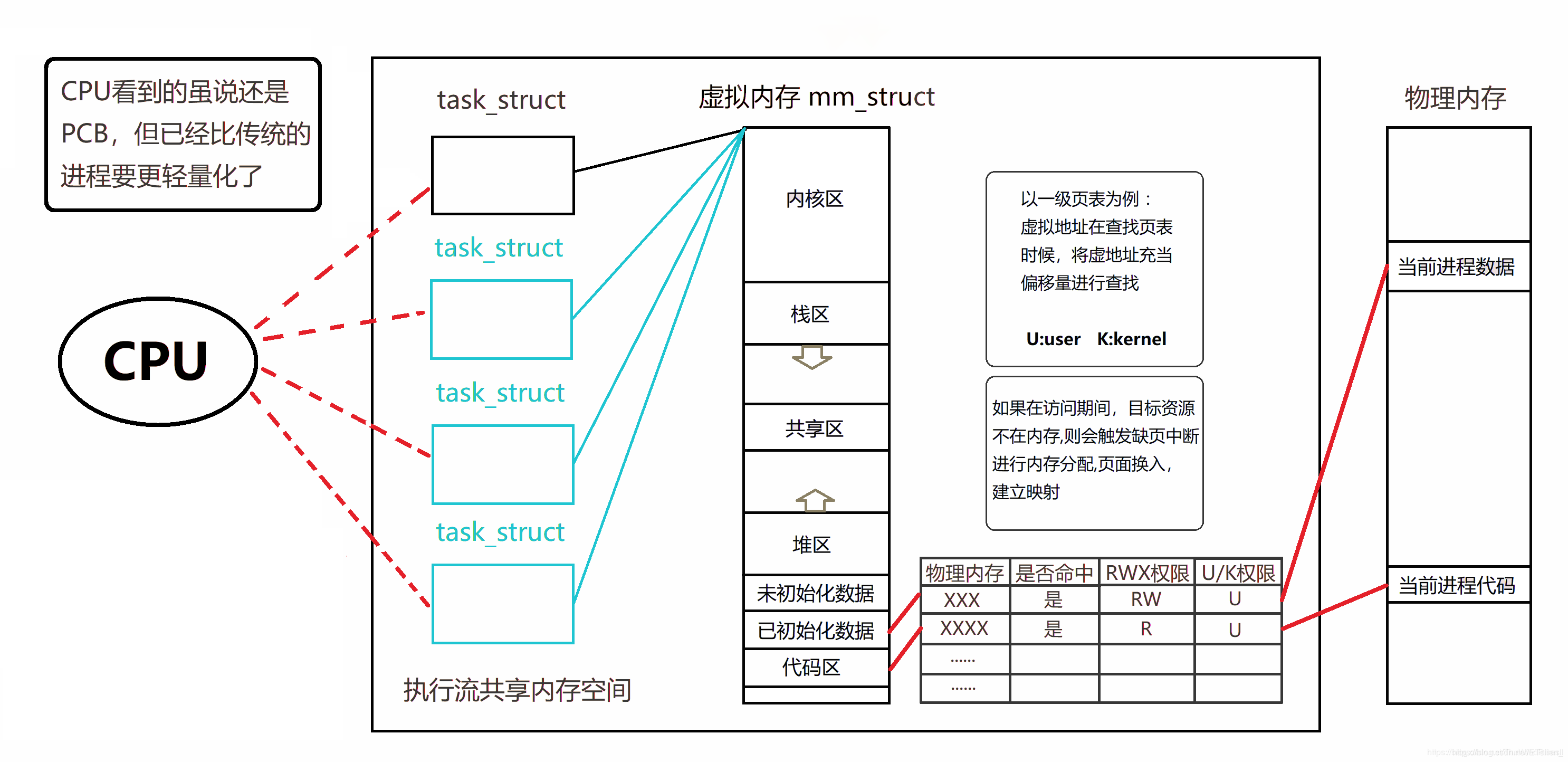
同⼀地址空间,因此Text Segment、Data Segment都是共享的,如果定义⼀个函数,在各线程中都可以调⽤,如果定义⼀个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
⽂件描述符表
每种信号的处理⽅式(SIG_ IGN、 SIG_ DFL或者⾃定义的信号处理函数)
当前⼯作目录
⽤户id和组id
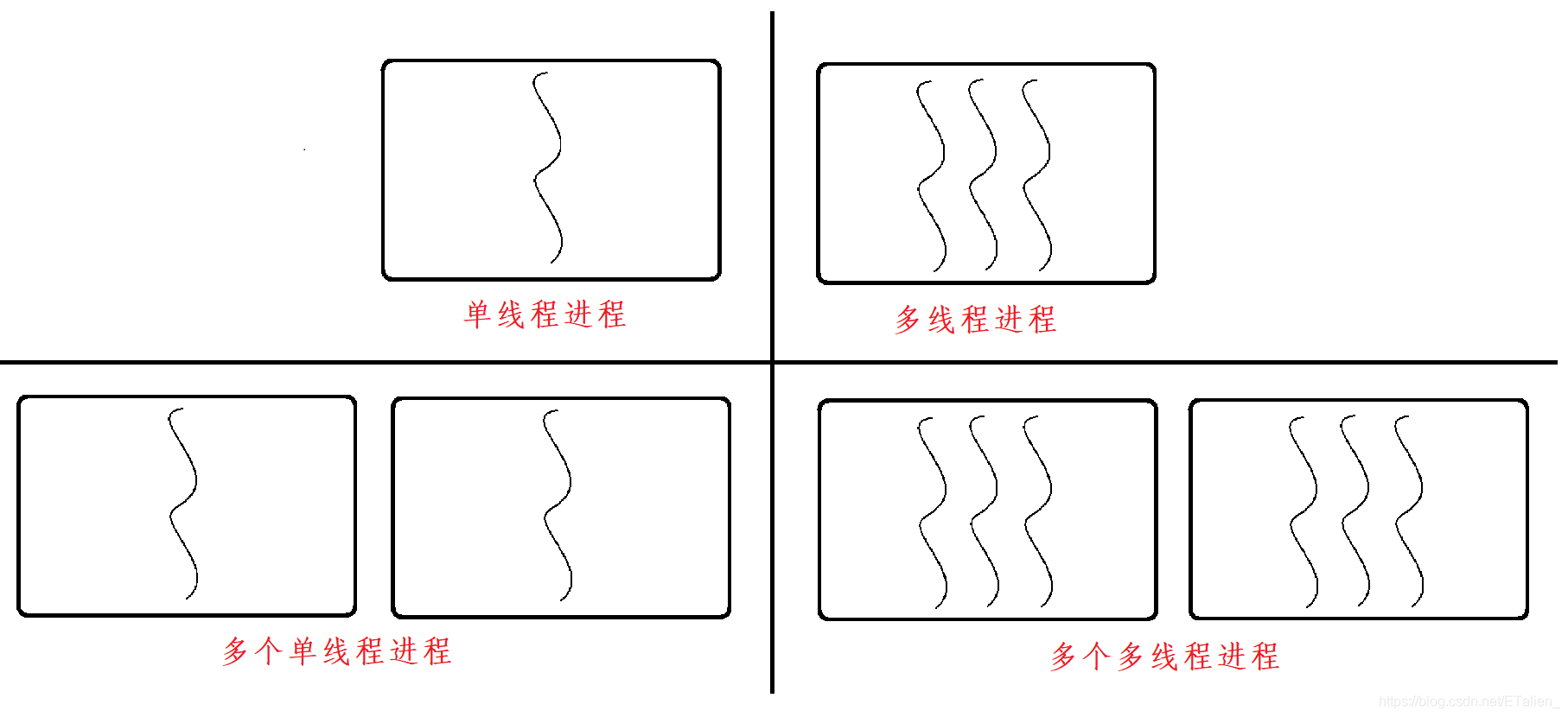
进程和线程的关系如下图:
线程的优点
- 创建⼀个新线程的代价要⽐创建⼀个新进程⼩得多
- 与进程之间的切换相⽐,线程之间的切换需要操作系统做的⼯作要少很多
- 线程占⽤的资源要⽐进程少很多
- 能充分利⽤多处理器的可并⾏数量
- 在等待慢速I/O操作结束的同时,程序可执⾏其他的计算任务
- 计算密集型应⽤,为了能在多处理器系统上运⾏,将计算分解到多个线程中实现
- I/O密集型应⽤,为了提⾼性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
- 性能损失
⼀个很少被外部事件阻塞的计算密集型线程往往⽆法与共它线程共享同⼀个处理器。如果计算密集型线程的数量⽐可⽤的处理器多,那么可能会有较⼤的性能损失,这⾥的性能损失指的是增加了额外的同步和调度开销,⽽可⽤的资源不变。 - 健壮性降低
编写多线程需要更全⾯更深⼊的考虑,在⼀个多线程程序⾥,因时间分配上的细微偏差或者因共享了不该共享的变量⽽造成不良影响的可能性是很⼤的,换句话说线程之间是缺乏保护的。 - 缺乏访问控制
进程是访问控制的基本粒度,在⼀个线程中调⽤某些OS函数会对整个进程造成影响。 - 编程难度提⾼
编写与调试⼀个多线程程序⽐单线程程序困难得多
进程ID和线程ID
- 在Linux中,目前的线程实现是Native POSIX Thread Libaray,简称NPTL。在这种实现下,线程又被称为轻量级进程(Light Weighted Process),每一个用户态的线程,在内核中都对应一个调度实体,也拥有自己的进程描述符(task_struct结构体)。
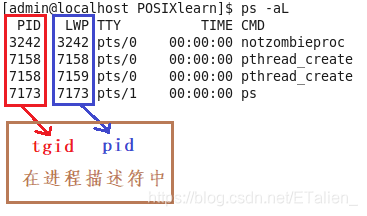
- 没有线程之前,一个进程对应内核里的一个进程描述符,对应一个进程ID。但是引入线程概念之后,情况发生了变化,操作系统底层不认识线程,因此线程的概念只能在用户层谈,所以叫做用户态线程,每一个线程作为一个独立的调度实体,在内核态都有自己的线程描述符。一个用户进程下管辖N个用户态线程,每个线程作为一个独立的调度实体在内核态都有自己的进程描述符,进程和内核的描述符一下子就变成了1:N关系,POSIX标准又要求进程内的所有线程调用getpid函数时返回相同的进程ID,如何解决上述问题呢?
- Linux内核引入了线程组的概念
举个栗子,假如我现在有十个线程,那么每个线程调getpid拿到的进程id都应该是一样的,然而每个线程又是一个独立的调度实体,因此还应该有一个id来标识一个一个的线程。
struct task_struct {
...
pid_t pid;
pid_t tgid;
...
struct task_struct *group_leader;
...
struct list_head thread_group;
...
};
-
多线程的进程,又被称为线程组,线程组内的每一个线程在内核之中都存在一个进程描述符(task_struct)与之对应。进程描述符结构体中的pid,表面上看对应的是进程ID,其实不然,它对应的是线程ID。进程描述符中的tgid,含义是Thread Group ID,该值对应的是用户层面的进程ID。

-
线程和进程不一样,进程有父进程的概念,但在线程组里面,所有的线程都是对等关系
线程ID及进程地址空间布局
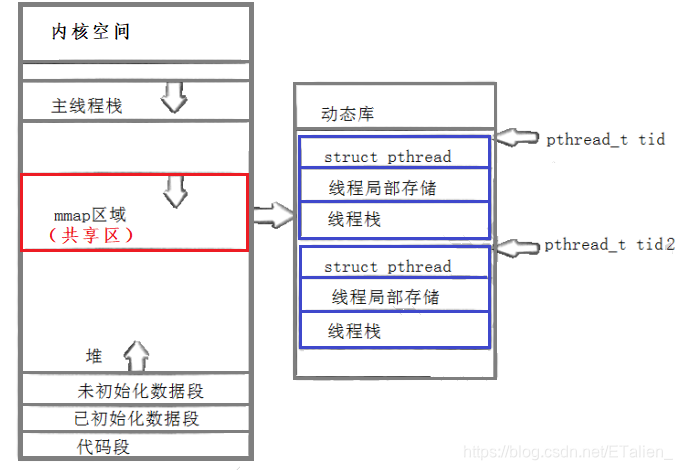
线程库要管理线程就要把线程描述并组织起来,只有线程库里才有线程的概念,库一旦被加载就会加载到内存中,在内存中加载就牵扯到虚拟地址空间。在多线程的运行过程中,栈是被共享的,库被加载,也就是说把该库全部映射到主线程虚拟地址空间堆栈之间的共享区(mmap区域),那么每个线程都可以看到这个动态库。
这个动态库除了要有代码之外,还要能够描述线程,描述线程时具备了三个东西,struct_pthread(线程结构体:里面有LWP),线程局部储存、线程栈(线程都有自己的私有栈,这个栈在哪里呢?在共享区当中线程库的内部),我们把这三个东西打包整理起来用来进行用户层面上的线程描述,因此以后我们想要找哪个线程只要找到这个库里对应线程存放区域的首地址即可(因为地址本身也是具有唯一性的)。所以我们在查看线程id时的那个数据,其实就是共享区的某一块起始地址。这叫做用户级别的线程库。