文章还不完善,会慢慢更新。
1.介绍
2.Deep learning:
深度学习已经广泛应用各个领域,不管是图像识别还是语音识别方面均已超过原有的机器学习算法。取代了传统的人工特征方法。
2.1 Spectrogram:
声音信号是一维时域信号。通过傅里叶变换,到频域上可以看出信号的频率分布,但是丢失了时域信息,无法看出频率分布随时间的变化。为了解决这个问题,常用的办法是短时傅里叶变换(STFT)。
2.1.1 生成声谱图:
- 对长信号分帧,加窗口;
- 对每一帧(短时)信号做傅里叶变换;
- 将频谱图旋转;
- 将频谱图幅度用灰度图来表示;
- 将FFT的结果按照时间维度堆叠;
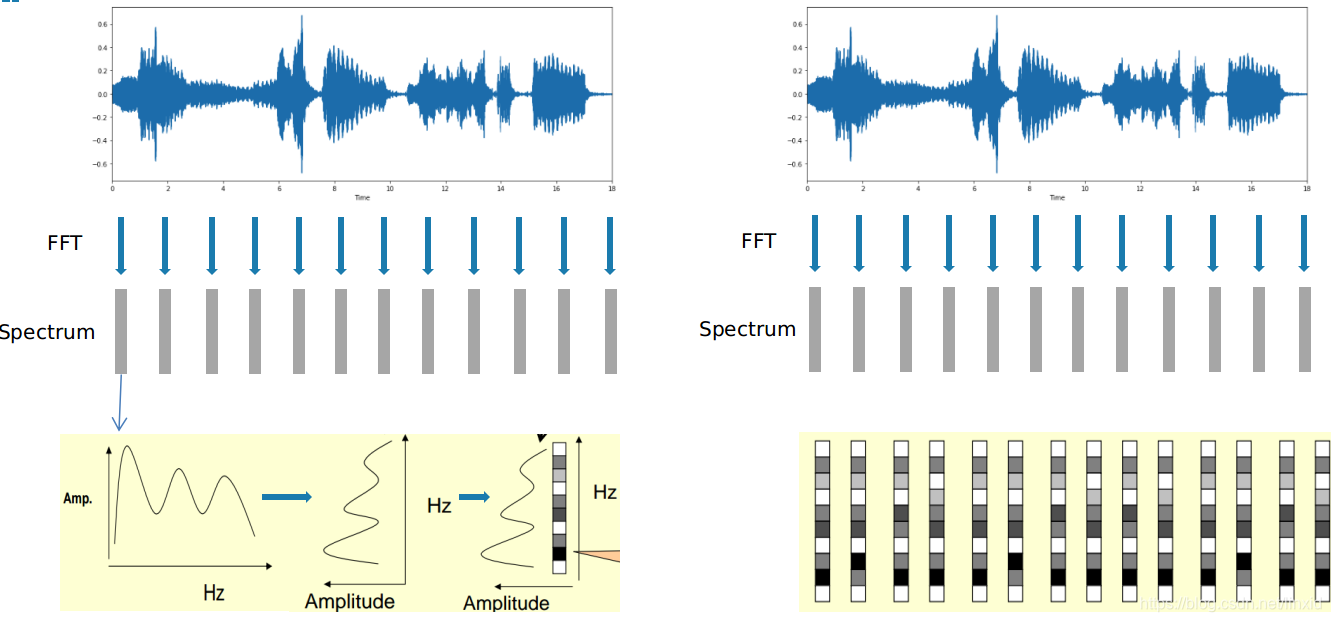
2.2.2 声谱图的作用:
- 声音信号的时频域表示
- 研究语音的重要工具;
- 利用HMM对声谱建模,可以讲声音转化为文字;
- 提取声音分类所需要的特征;
2.2.3 MFCCs:
以上均为我们人为对声音信号的分析,相比这些,人的听觉系统具有巨大的优势。
-
只聚焦于某些特定频率区域:
只让某些频率的信号通过;低频区域分布密集;高频区域分布稀疏 -
非线性系统:
对不同频率信号的灵敏度不同;频率提高1倍,人察觉不到提高了两倍 -
语音特征:
能提取出语义信息, 而且能提取出说话人的个人特征
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征。
梅尔标度:
将普通的频率标度转化为梅尔频率标度
映射关系:
通过这个映射关系,在梅尔标度下,人耳对频率的灵敏度变成了线性关系。
这部分内容大部分参考[13,14,15],此处仅做一个简单总结,描述如何得到MFCC特征。
可以简单认为梅尔频谱是对正常声谱加了一个滤波器得到对梅尔频谱做倒谱分析得到梅尔倒谱。
- 何为.wav文件,信号数据和采样频率:
.wav文件即无损音频文件,录音设备在录音,或者python读取音频文件时,是按固定频率对真实声波的每个点进行采样,实现从真实信号到模拟信号的转变。此处采样频率应该满足奈奎斯特采样定律,即采样频率大于信号最大频率的2倍。保证能够还原原始信号。 - 数据预处理:
为了提高信噪比,我们需要进行数据预处理。按照以下公式进行数据预处理(但不知道原理):
- 分帧:
将原始数据划分为多个音频段,类似一张图和视频的关系。比如我们常见的60帧。 - 加汉明(Hanmming)窗:
作用是为了使帧和帧之间变得平滑,消除吉布斯效应。 - 离散傅里叶变换(FFT):
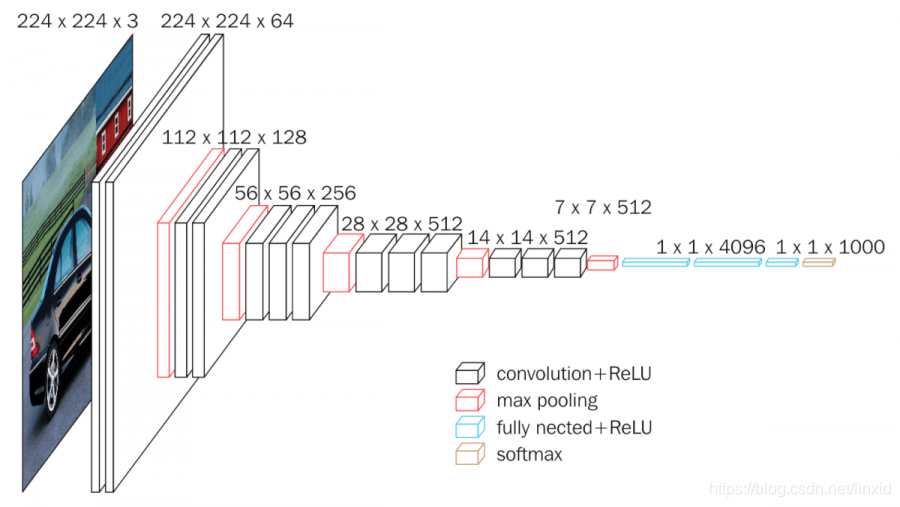
2.3 DL Model(CNN)
3. Machine Learning:
3.1 Feature Extraction:
3.1.1 时域特征(Time Domain)
-
中心距(Central moments):
原始声音信号(声波)的幅度的均值(mean),标准差(standard deviation),偏度(skewness),峰度(kurtosis)。 -
过零点(Zero Crossing Rate-ZCR):
过零点即声音信号(声波)符号变化的点,也就是从正值变成负值。比如下面是一段声音信号:
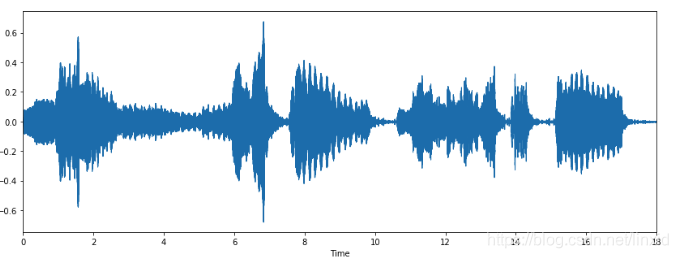
对这段信号放大,只选取一小部分,得到放大的局部图:
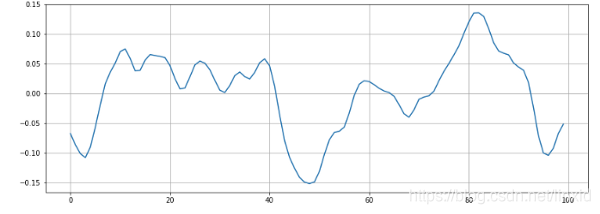
我们可以从图中可以看出,这一段信号有6个过零点。
提取信号过零点个数的 总数(sum),均值(mean),标准差(mean) 作为特征。
对于某些Rock或者重金属音乐这个特征值会非常的高; -
Root Mean Square Energy (RMSE):
然后对RMSE求均值(mean),标准差(mean) 。 -
节奏(Tempo)
节拍可以表征音乐的快慢,特被定义为每分钟的节拍数(Beats Per Minute-BPM)
3.1.2 频域特征(Frequency Domain)
-
梅尔倒谱系数(Mel-Frequency Cepstral Coefficients-MFCC )
-
色度特征(Chroma Features):
这是一个音频信号非常有用的一个表征方式。可以认为是将整个频谱投影到12个箱子。
有兴趣的可以参考[21],非音乐专业,不是很理解,以下是这个特征的生成方式。
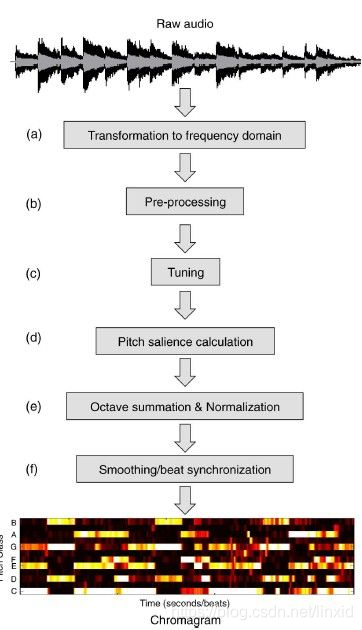
-
频谱中心(Spectral Centroid) :
类比,假设我们有两首歌,风格分别是Blues和Metal。和Blues相比,Metal风格的声音,在音乐的尾部有更多的频率。二者的频率的中心也就有所不同。
对频率做带权(幅度)求和,然后除以幅度求和。 -
频谱带宽(Spectral Band-width):
-
谱对比度(Spectral Contrast):
-
Spectral Roll-off:
它是对声音信号形状(波形图)的一种衡量。它表示低于总频谱能量的指定百分比的频率。
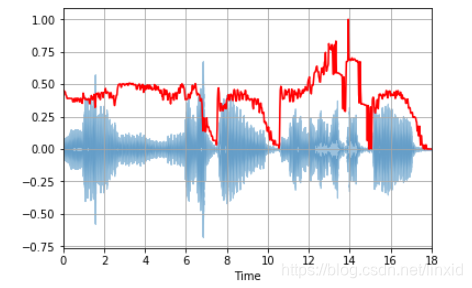
蓝色为原声音信号,红色为Spectral Roll-off。可以发现和声波信号形状相似。
4.结论和展望:
参考资料:
[1] 手把手教你打造一个曲风分类机器人
[2] 怎样用深度学习发现一首歌属于哪个流派?
[3] Finding the genre of a song with Deep Learning — A.I. Odyssey part. 1
[4] 私人定制——使用深度学习Keras和TensorFlow打造一款音乐推荐系统
[5] Building a Music Recommender with Deep Learning
[6] 个性化推荐算法:为什么网易云音乐推荐歌单那么精准?
[7] pyAudioAnalysis: An Open-Source Python Library for Audio Signal Analysis
[8] Music Genre Classification
[9] Music Genre Classification using Machine Learning Techniques
[10] Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between
[11] 【干货】用神经网络识别歌曲流派(附代码)
[12] Models for AudioSet: A Large Scale Dataset of Audio Events
[13] 语音信号处理之(四)梅尔频率倒谱系数(MFCC)
[14] AI(I)语音(I):MFCC特征参数提取
[15] CMU:Topic: Spectrogram, Cepstrum and Mel-Frequency Analysis
[16] Recommending music on Spotify with deep learning
[17] Sound Classification using Spectrogram Images
[18] 采用深度学习算法为Spotify做基于内容的音乐推荐
[19] 音频特征提取——librosa工具包使用
[20] Music Genre Classification with Python
[21] 什么是Chroma Features