目标检测系列(二):SPP-Net
标签(空格分隔): 目标检测
References:
- https://blog.csdn.net/chaipp0607/article/details/78446708
- https://blog.csdn.net/v1_vivian/article/details/73275259
STAR
S: R-CNN的致命缺陷,超长的训练时间(84h)和测试时间(47s),造成这个问题的主要原因是对每一张待检测图产生的1000-2000个区域进行重复性的卷积计算。
T: 如何共享卷积运算?
A: 共享卷积计算+空间金字塔池化
R: 训练时间和单张图片的测试时间都出现较大的缩短。
1. SPP-Net VS R-CNN
R-CNN的卷积神经网络的输入是ss生成的建议区域(经过尺寸的归一化),而SPP-Net的中的卷积神经网络的输入是整幅图,经过卷积特征提取后,在Conv5上做建议区域的提取。


对于R-CNN,整个过程是:
- 首先通过选择性搜索,对待检测的图片进行搜索出1000 ~2000个候选窗口。
- 把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个proposal提取出一个特征向量,也就是说利用CNN对每个proposal进行提取特征向量。
- 把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
而对于SPP-Net,整个过程是:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用***金字塔空间池化***,提取出***固定长度的特征向量***(用于做全连接层的输入)。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
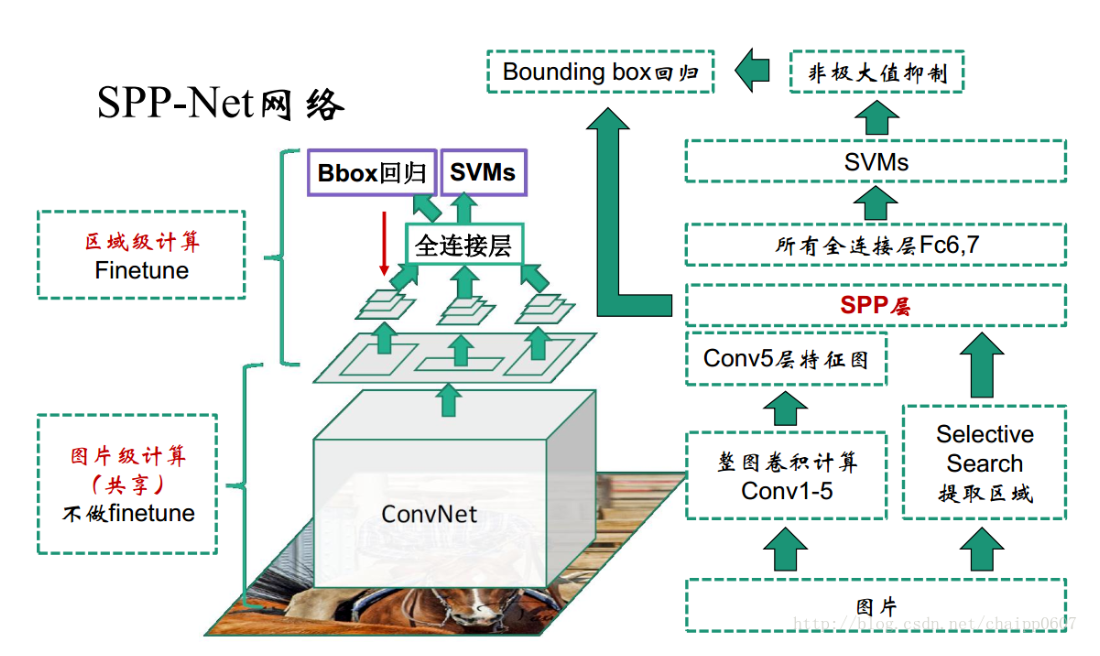
2. SPP-Net 网络
1. SS 算法:提取区域建议
2. CNN 网络:提取特征
(1)Mapping a Window to Feature Maps:
在原图中的proposal,经过多层卷积之后,位置还是相对于原图不变的(如下图所示),那现在需要解决的问题就是,如何能够将原图上的proposal,映射到卷积之后得到的特征图上,因为在此之后我们要对proposal进行金字塔池化。


(2)空间金字塔池化:
因为卷积层的参数和输入大小无关,但全连接层的参数就和输入图像大小有关。因为对于同一张图片提取的Cov5层的特征,因为SS提取的候选区域大小不同,因此采用金字塔空间池化的方式,提取出固定长度的特征向量, 用于做全连接层的输入(即多尺度特征提取出固定大小的特征向量)。如下图所示,可以得到21维特征的输出。

3. SVM网络:分类器
4. Bounding Box Regression: 边框回归调整推荐窗口
3. SPP-Net的训练过程
首先拿到在ImageNet预训练的AlexNet模型,用AlexNet计算Conv5层特征,根据ss生成的区域建议,从Conv5上提取到对应的SPP特征,用提取到的特征finetune全连接层(把AlexNet当做分类模型来训练)。
AlexNet训练好之后,用fc7层的特征训练SVM分类器,用SPP特征训练bounding box(这里和R-CNN一样了)。
4. SPP-Net的测试过程
首先在一张图片上用训练好的AlexNet网络提取整张图片的Conv5和fc7层特征,同时在图片上用ss算法生成1000-2000个区域建议,将区域建议框坐标变换之后在Conv5上提取SPP特征,fc7层特征送入SVM做类别的预测,SPP特征送入bounding box做边界框的修正。
5. SPP-Net性能评价

6. SPP-Net主要问题
- SPP-Net的训练过程依然是一个多阶段的训练,这一点和R-CNN一样,并未改进。 由于是多阶段训练,过程中需要存储大量特征。
- 从SPP-Net的训练过程可以看出,它是无法finetune卷积层的,这个问题在Fast RCNN中通过多任务损失函数与Roi Pooling提出得以解决。