深度学习疑难杂症解决(一)
References:
1. Batch Normalization:
参考:https://zhuanlan.zhihu.com/p/34879333
- 问题:
(1)蝴蝶效应:当底层网络中参数发生微弱变化时,由于每一层中的线性变换与非线性激活映射,这些微弱变化随着网络层数的加深而被放大(类似蝴蝶效应;
(2)Internal Covariate Shift:参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难。可以这样通俗的理解,本来来一批数据,模型赋予第一次权重,发现结果不是想要的情况,那我继续去调整就好了,但是现在你数据还每次都改变,模型要调整成想要情况的困难程度就大大增加了。
- 上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低;
- 网络的训练过程容易陷入梯度饱和区(一个通过RELU, 一个通过BN来进行解决),减缓网络收敛速度;
- 原有做法:白化
- 白化过程计算成本太高,并且在每一轮训练中的每一层我们都需要做如此高成本计算的白化操作;
- 白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。底层网络学习到的参数信息会被白化操作丢失掉。(注意这个问题是如何被BN解决的)
- BN:定向解决问题
- 对每个特征进行独立的normalization;
- BN又引入了两个可学习(learnable)的参数 gamma 与 beta 。这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换特别地,当 gamma2=sigma2,beta=u 时,可以实现等价变换(identity transform)并且保留了原始输入特征的分布信息。通过上面的步骤,我们就在一定程度上保证了输入数据的表达能力。

- BN的优势
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度;
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定;
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题;
(4)BN具有一定的正则化效果:最后BN训练过程中由于使用mini-batch的mean/variance作为总体样本统计量估计,引入了随机噪声,在一定程度上对模型起到了正则化的效果。
2. Attention机制
- 学习权重分布:输入数据或特征图上的不同部分对应的专注度不同;
- 任务聚焦:通过将任务分解,设计不同的网络结构(或分支)专注于不同的子任务,重新分配网络的学习能力,从而降低原始任务的难度,使网络更加容易训练。
3. Loss
参考:https://blog.csdn.net/jasonzzj/article/details/52017438
- Logistic回归的交叉熵
- softmax 的交叉熵
- cross entropy loss:用于度量两个概率分布之间的相似性
4. 优化算法
参考:
- https://blog.csdn.net/qsczse943062710/article/details/76763739
- https://zhuanlan.zhihu.com/p/23906526
- SGD
- Momentum:The incorporation of momentum into stochastic gradient descent reduces the variation in overall gradient directions and speeds up learning.
- AdaGrad (Adaptive Gradient Algorithm):AdaGrad scales the learning rates of all model parameters by inversely proportional to the square root of the sum of all of their historical squared gradients.
- RMSProp (Root Mean Square Propagation):RMSProp uses an exponentially decaying average to discard history from the extreme past
- Adam (Adaptive Moments):Roughly a combination of RMSProp and momentum, with bias correction.
- 超参数理解:
- Learning Rate:学习率决定了权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢;
- Weight decay:其实就是正则化;
- Momentum: 加入‘惯性’的影响;
- Learning Rate Decay:为了提高SGD寻优能力,具体就是每次迭代的时候减少学习率的大小;
5. 激活函数
参考:https://blog.csdn.net/yangdashi888/article/details/78015448
- Sigmoid:Sigmoids saturate and kill gradients; Sigmoid outputs are not zero-centered。
- Tanh:解决了sigmoid 关于中心不对称的问题,但是仍然容易梯度饱和。
- ReLU:
- 其在梯度下降上比较tanh/sigmoid有更快的收敛速度。这被认为时其线性、非饱和的形式。
- 比较tanh/sigmoid操作开销大(指数型),ReLU可以简单设计矩阵在0的阈值来实现。
- 不幸的是,ReLU单元脆弱且可能会在训练中死去。
- Leaky ReLU:Leaky ReLUs 就是用来解决ReLU坏死的问题的。和ReLU不同,当x<0时,它的值不再是0,而是一个较小斜率(如0.01等)的函数。
- Random ReLU:是 leaky ReLU 的random 版本, 其核心思想就是,在训练过程中,a是从一个高斯分布中随机出来的(x为负数时的参数),然后再在测试过程中进行修正。
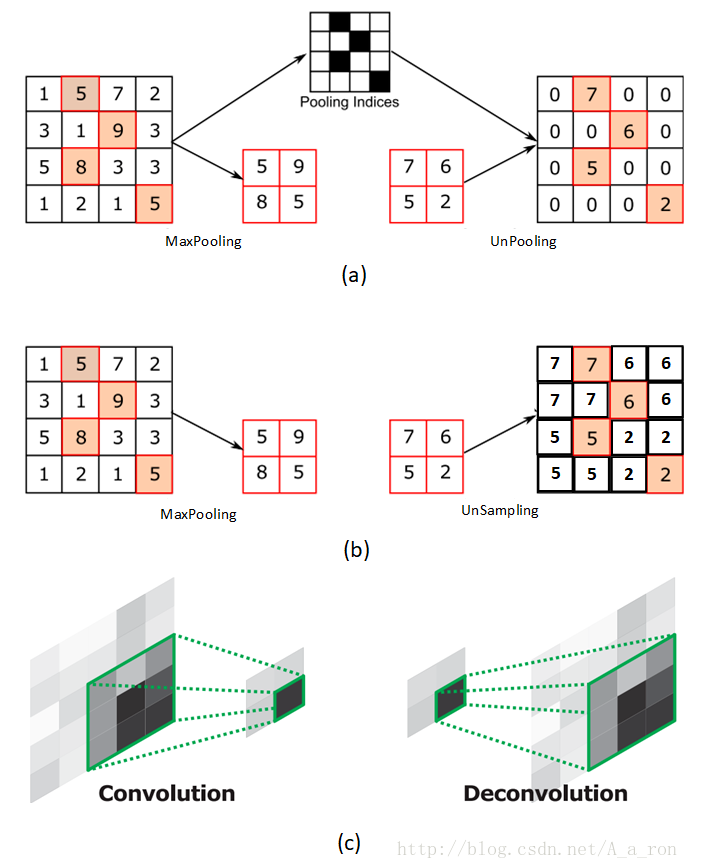
6. 反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)
参考:https://blog.csdn.net/a_a_ron/article/details/79181108
7. 过拟合与欠拟合
- 欠拟合:模型的复杂度较低,没法很好的学习到数据背后的规律;
- 过拟合:模型的复杂度要高于实际的问题。
8. 数据不完美问题
参考:http://www.cnblogs.com/demian/p/9575735.html
-
数据不平衡:
- 数据扩充/增强/过采样/欠采样
- one class learning:针对极端不均衡的情况,即当作异常值检测进行处理。
- online hard example mining(OHEM):上图绿色和红色分为两个网络但共享权限,通过将提取的RoI传入绿色的只读网络(只进行forward),计算出每个RoI的loss。根据loss排序(可使用NMS)选出部分样本,再输入红色网络(进行forward和backward)学习并进行梯度传播。文中提出另一种办法,在反向传播时,只对选出的样本的梯度/残差回传,而其他的props的梯度/残差设为0。但容易导致显存显著增加,迭代时间增加。
- focal loss:同样所有样本的loss都会缩小,但是hard example要不easy example缩小的少得多,从而取得好的训练效果。
- class balanced cross-entropy: 思想就是引入新的权值β,实现正负样本loss的平衡,从而实现对不同正负样本的平衡。
-
数据标签不足:我认为需要聚类?
9. 不适合深度学习的情况
参考:https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/79283400
- 低成本或者低承诺问题:无论是网络结构设计,调参,选优化函数激活函数等,都需要消耗很高的计算量和人力,有时SVM 可以解决这些问题;
- 解释和传达模型参数对一般观众的重要性;
- 建立因果机制;
- 从‘非结构化’功能中学习
10. BP算法推导
11. 全连接层与全局平均池化
参考:https://blog.csdn.net/qq_23304241/article/details/80292859
- 全连接层:将最后一层卷积的‘feature maps’ flatten 后,全连接到全连接层,用于后续分类。但参数量过大,降低了训练的速度,且很容易过拟合;
- Global average pooling: global 显然就是对整个 feature map 求平均值了。
12. 神经网络不收敛的常见问题:
参考:
- 没有对数据进行归一化
- 忘记检查输入和输出
- 没有对数据进行预处理
- 没有对数据正则化
- 使用过大的样本
- 使用不正确的学习率
- 在输出层使用错误的激活函数
- 网络中包含坏梯度
- 初始化权重错误
- 过深的网络
- 隐藏单元数量错误
13. 为什么深度学习几乎成了计算机视觉研究的标配?
参考:https://zhuanlan.zhihu.com/p/21533690
- 从传统目标检测和深度学习框架下的目标检测进行对比。
- 深度学习可以做到传统方法无法企及的精度,这是关键中的关键;
- 深度学习算法的通用性很强,刚才提到的检测,在传统算法里面,针对不同的物体需要定制化不同的算法;
- 深度学习获得的特征(feature)有很强的迁移能力;
- 工程开发、优化、维护成本低;
- 机器学习就是学习输入到输出的一个映射,传统方法使用浅层的简单映射,现在深度学习是多层的复合映射(复合映射就提供很高的自由度)。
14. DL和ML的区别
- 统计机器学习需要人工设计特征,特征工程很重要;
- 深度学习可以自动学习特征,特别是在图像、语音、文本方面,这些数据都有局部和整体关系,DL能发挥很大作用。
15. CNN 重点操作
参考:
1. CNN的精华:(2核心3概念)
- 卷积:卷积核相当于滤波器,主要用于提取特征,k/s/p/多通道等超参数设置,可用于提取不同特征;
- 池化:保留显著特征的同时jiang’w降维,增加感受野;
- 局部感受野
- 权值共享
- 下采样/上采样
2. 卷积的反向传播
参考:https://www.zhihu.com/question/58716267
我觉得就还是利用梯度等于loss*input 来理解。
3. 池化的反向传播
记住最大值的位置,maxpooling 则只传给对应位置,其他为0;average pooling 则对应位置平均。
4. 卷积层参数量,计算量
参考:https://imlogm.github.io/深度学习/vgg-complexity/
5. 感受野的计算
16. 为什么梯度反方向是函数值下降最快的方向?
参考:http://sofasofa.io/forum_main_post.php?postid=1002758
17. bagging和dropout
参考:https://blog.csdn.net/m0_37477175/article/details/77145459
18. 各种损失函数,交叉熵,多标签分类
参考:
-
常见的损失函数:
- cross entropy/log(逻辑回归/softmax)
- 平方损失(最小二乘法)
- 指数损失函数(Adaboost)
- HingeLoss(SVM)
- 0-1损失(多用于统计正确率)
- 绝对值损失(减小异常值的放大作用)
-
异军突起的损失函数:
-
多标签:
参考:https://blog.csdn.net/u011734144/article/details/80915559
对于任何一部电影,电影的中央委员会会根据电影的内容颁发证书。例如,如果你看上面的图片,这部电影被评为“UA”(意思是“12岁以下儿童需在父母陪同下观看”)。还有其他类型的证书类,如“A”(仅限于成人)或“U”(不受限制的公开放映),但可以肯定的是,每部电影只能在这三种类型的证书中进行分类。简而言之,有多个类别,但每个实例只分配一个,因此这些问题被称为多类分类问题。
同时,你回顾一下这张图片,这部电影被归类为喜剧和浪漫类型。但不同的是,这一次,每部电影都有可能被分成一个或多个不同的类别。
所以每个实例都可以使用多个类别进行分配。因此,这些类型的问题被称为多标签分类问题。(可以总结为标签不是互斥的,是有关联的,但是各分类类别之前是互斥的)
Sigmoid 和 softmax 函数都可以用于实现多类分类和多标签分类。
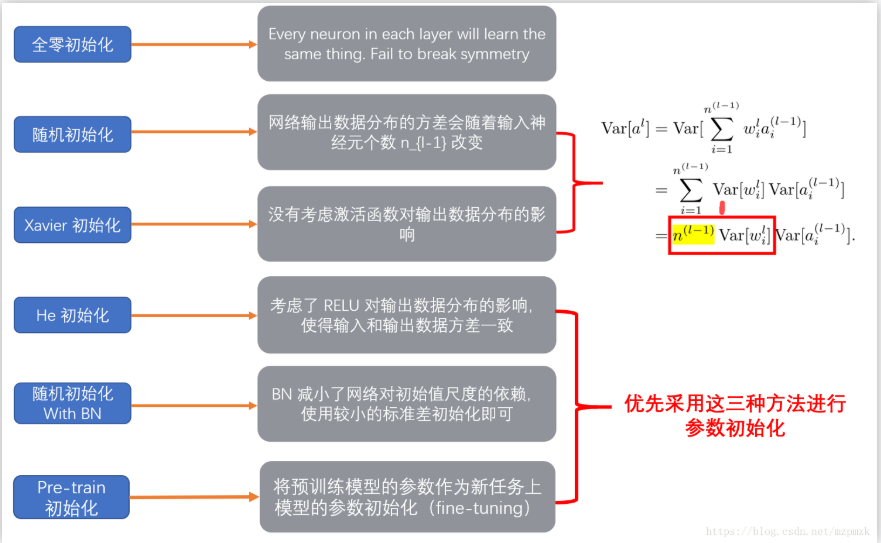
19. 权重初始化的方法
参考:https://www.cnblogs.com/makefile/p/init-weight.html?utm_source=itdadao&utm_medium=referral
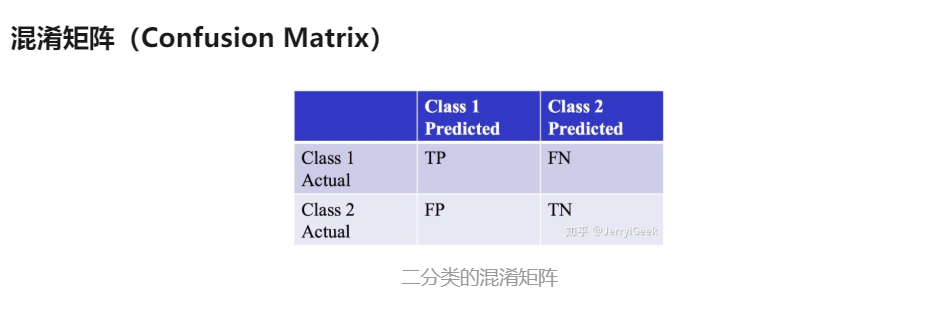
20. 机器学习性能度量方法
参考:https://zhuanlan.zhihu.com/p/39957290
1. 回归任务:均方误差
2. 分类任务:以混淆矩阵出发
- 精度(accuracy)
- 查全率(Recall)
- 查准率(Precision)
- F1 Measure/Score
- P-R曲线:precision/recall
- ROC/AUC: area under curve
21. CNN、RNN对于激活函数的选择
参考:https://www.zhihu.com/question/61265076
- CNN多用ReLU, 可以用于防止梯度消失,而且不同w本身的稀疏性导致不容易发生梯度爆炸;
- RNN多用Tanh, RNN中直接把激活函数换成ReLU会导致非常大的输出值,将激活函数换成ReLU也不能解决梯度在长程上传递的问题(要么会出现梯度消失,要么会出现梯度爆炸),因此采用gradient cliping/LSTM等解决问题。
22. 性能度量延伸问题
- 某个类别准确率不高怎么办,混淆矩阵互分严重怎么办?
参考:https://segmentfault.com/q/1010000014379836/
- 是不是本身人眼看起来就很难分类(是否需要清洗)
- 是否该类别需要扩大样本集
- 是否需要在LoSS中额外体现出该类别的情况
- 精确率较高,但召回率比较低,如何解决:
- 数据小物体偏多,容易漏检,预测的虽然少,但是比较准确
- 多尺度进行预测, 增加anchor 的数量
- 为什么不直接回归bbox的坐标,要用anchor来辅助?
因为自然图片中物体的大小是在几个常用的范围之内的,faster-rcnn中的9个anchor的大小,基本上就是自然图片中大多数物体的大小范围,所以找出与物体gt最接近的anchor,并且微调这个anchor,让其接近物体的gt(真实框的大小),更省时间,更准确。直接回归bbox坐标的话,会很慢。
23. 小样本学习
参考:
24. 主流深度学习框架对比
参考:
选择用不同框架时可以从一下几个方面进行考虑:
- 自己用来做什么:视觉
- 能提供相关问题的资源:论文、文档、技术资料、开源性、社区
- 训练效率、速度、性能
- 门槛及上手难度、易用性、开发速度
如需转载请注明出处,谢谢