在前面的文章介绍了对象在虚拟机中的创建过程。本文主要是记录下对象在虚拟机中的内存布局分配情况。
对象的内存布局
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头,实例数据和对齐填充。
| 序号 | 区域 | 说明 |
|---|---|---|
| 1 | 对象头 | 存储对象的hashCode或锁的相关信息 |
| 2 | 实例数据 | 存储对象实例相关的数据 |
| 3 | 对齐填充 | 占位符的作用 |
1.对象头
对象头包含两部分
第一部分内容
第一部分存储自身的运行时数据,如hashCode,GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时间戳,对象分代年龄,这部分信息称为"Mark Word",Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据自己的状态复用自己的存储空间。32位或者64位存储也有区别。
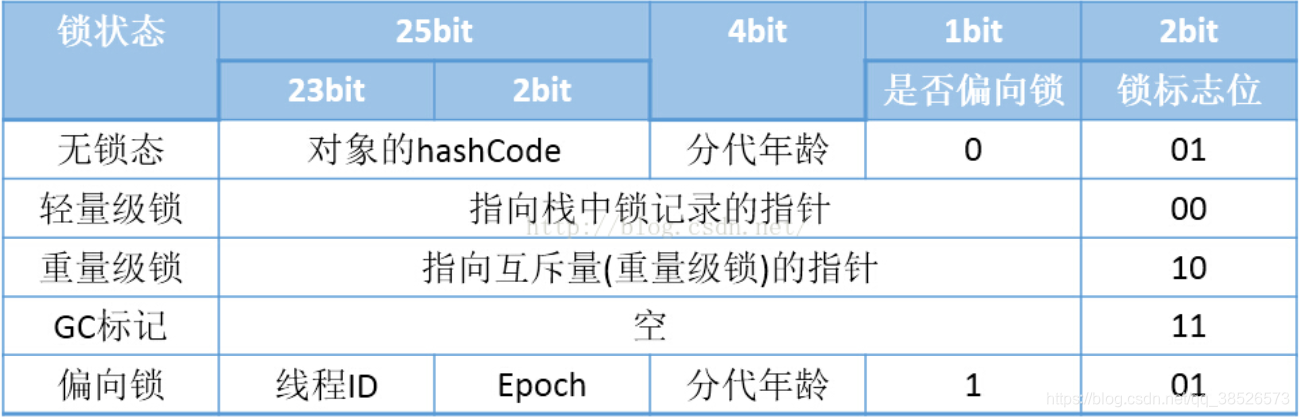
例如:在 32 位的 HotSpot 虚拟机中,如果对象处于未被锁定的状态下,那么 Mark Word 的 32bit 空间中的 25bit 用于存储对象哈希码,4bit 用于存储对象分代年龄,2bit 用于存储锁标志位,1bit 固定为 0,如下表所示
| 锁状态 | 25bit | 4bit | 1bit是否是偏向锁 | 2bit锁标志位 |
|---|---|---|---|---|
| 无锁状态 | 对象的hashCode | 对象的分代年龄 | 0 | 01 |
对象在其他状态下(轻量级锁定,重量级锁定,GC标记,可偏向)对象的存储内容如下:
| 存储内容 | 标志位 | 状态 |
|---|---|---|
| 对象哈希码,对象分代年龄 | 01 | 未锁定 |
| 指向锁记录的指针 | 00 | 轻量级锁定 |
| 指向重量级锁的指针 | 10 | 膨胀(重量级锁定) |
| 空,不需要记录信息 | 11 | GC标记 |
| 偏向线程ID,偏向时间戳, 对象分代年龄 |
01 | 可偏向 |
第二部分内容
第二部分存储类型的指针,既对象执行它的类元数据的执行(方法区),虚拟机通过这个指针来确定这个对象是那个类的实例。如果对象是一个Java数组,在对象头中还须有一块用于记录数组长度的数据,因为虚拟机可通过普通Java对象的元数据信息确定Java对象的大小,但从数组的元数据中无法确定数组的大小。
2.实例数据(Instance Data)
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。这部分的存储顺序会受到虚拟机分配策略参数(FieldsAllocationStyle)和字段在 Java 源码中定义顺序的影响。
3.对齐填充(Padding)
对齐填充不是必然存在的,没有特别的含义,它仅起到占位符的作用。
由于 HotSpot VM 的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,也就是说对象的大小必须是 8 字节的整数倍。对象头部分是 8 字节的倍数,所以当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
对象大小估算
32 位系统下,当使用 new Object() 时,JVM 将会分配 8(Mark Word+类型指针) 字节的空间,128 个 Object 对象将占用 1KB 的空间。如果是 new Integer(),那么对象里还有一个 int 值,其占用 4 字节,这个对象也就是 8+4=12 字节,对齐后,该对象就是 16 字节。
以上只是一些简单的对象,那么对象的内部属性是怎么排布的?
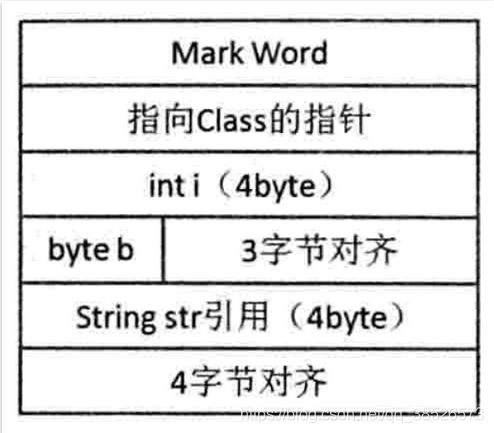
Class A {
int i;
byte b;
String str;
}
其中对象头部占用 ‘Mark Word’4 + ‘类型指针’4 = 8 字节;byte 8 位长,占用 1 字节;int 32 位长,占用 4 字节;String 只有引用,占用 4 字节;
那么对象 A 一共占用了 8+1+4+4=17 字节,按照 8 字节对齐原则,对象大小也就是 24 字节。
这个计算看起来是没有问题的,对象的大小也确实是 24 字节,但是对齐(padding)的位置并不对:
在 HotSpot VM 中,对象排布时,间隙是在 4 字节基础上的(在 32 位和 64 位压缩模式下),上述例子中,int 后面的 byte,空隙只剩下 3 字节,接下来的 String 对象引用需要 4 字节来存放,因此 byte 和对象引用之间就会有 3 字节对齐,对象引用排布后,最后会有 4 字节对齐,因此结果上依然是 7 字节对齐。此时对象的结构示意图,如下图所示:
参考资料:<深入理解Java虚拟机>